导读
过去,数据分析意味着写复杂SQL、等待执行、解读结果。现在,借助 Lakehouse MCP Server 的50多个工具(详见附录工具列表),让这一切变得像对话一样自然:用户用业务语言提问,AI自动理解并生成查询,Lakehouse在底层高效执行,最终答案以自然语言返回。这样的模式不仅降低了数据使用门槛,还加快了决策与创新的节奏,并依托 Lakehouse的实时引擎,确保结果始终鲜活。从过去AI的小规模数据分析,到如今AI × Lakehouse的结合,让智能数据服务真正触手可及。
什么是 MCP:AI与数据系统的标准化桥梁
MCP (Model Context Protocol)是一个标准化的接口协议,它保证了AI与外部系统的交互是安全的、可控的、可扩展的。而云器Lakehouse本身已经是一个高性能、低延迟、支持通用增量计算的数据底座。两者结合,就相当于:
- MCP提供了“语言 → 调用”的桥梁 :将自然语言转换为系统调用
- Lakehouse提供了“调用 → 执行”的引擎 :高效执行数据查询和分析
这种架构设计解决了传统数据分析中最大的痛点—技术门槛与业务需求之间的鸿沟。
价值意义:从技术驱动到业务驱动的转变
传统数据平台的使用方式是“写SQL → 系统执行”。这要求用户必须懂 schema、懂SQL语法,还要能把业务问题翻译成查询逻辑。MCP Server的出现,把这个流程替换为:
💡 输入业务语言 → AI 理解并生成查询 → Lakehouse 高效执行 → AI 用自然语言返回答案
这背后的价值体现在三个维度:
1. 认知门槛降低
更多人可以直接与数据对话,而不是依赖数据工程师。业务分析师、产品经理,甚至业务决策者都能直接获取数据洞察,真正实现了数据的民主化。
2. 迭代速度加快
实验和分析不再被阻塞在“写查询 → 等人”的环节。想法可以立即验证,假设可以快速测试,大大缩短了从问题到答案的路径。
3. 实时智能服务
Lakehouse的秒级延迟能力,让AI可以返回「鲜活」的数据。无论是实时监控、动态报表还是即时决策支持,都能基于最新的数据状态进行。
云器 Lakehouse MCP Server:技术架构与特性
💡 云器Lakehouse 正式开放 MCP 协议集成公测。这意味着任何支持 MCP 的 AI 客户端都可以直接与云器 Lakehouse 进行交互,用户仅需使用自然语言,就可以享受企业级数据湖仓的强大能力。
Lakehouse MCP Server 是专为 Lakehouse 平台设计的 MCP 服务器,它将云器 Lakehouse 强大的数据湖仓能力与 AI 助手无缝集成,让用户能够通过自然语言与数据湖仓进行交互。
核心特性
- 协议支持 :支持 HTTP (Streamable)、SSE、Stdio 三种传输协议
- 标准兼容 :完全遵循 MCP 官方规范,提供标准 /mcp 端点
- 广泛兼容 :支持 Claude Desktop、Dify、n8n、Cursor 等主流平台
部署环境要求
系统要求
- 操作系统:MacOS、Windows、Linux
- Docker:20.10+ 版本
- 内存:最低 2GB,推荐 8GB
- CPU:最低 2 核,推荐 4 核
- 存储:最低 10GB 可用空间
快速开始:从零到一构建智能数据对话
本示例介绍采用 HTTP (Streamable) 协议方式部署(推荐),同时 Claude Desktop (MCP 客户端) 和MCP服务器都运行在同一台本地计算机(localhost)上。该架构同样支持分布式部署,即客户端、服务器和 Lakehouse 平台可以分别位于不同的远程主机上。

步骤0:MCP Server 端配置准备
Docker 环境准备:访问https://www.docker.com/products/docker-desktop/ 下载 Docker Desktop for Mac。
- 验证安装 Docker Desktop (MacOS 环境)保证 Docker 版本20.10+
docker --version
- 配置 Docker Desktop:
- 分配至少 4GB 内存给 Docker
- 启用文件共享功能
步骤1:MCP Server 端:拉取最新云器的 MCP Server 镜像
docker pull czqiliang/mcp-clickzetta-server:latest
步骤2:MCP Server 端:创建工作目录(如果不存在)
- macOS:
mkdir -p ~/.clickzetta/lakehouse_connection
- Windows PowerShell:
New-Item -ItemType Directory -Path "$env:USERPROFILE\.clickzetta/lakehouse_connection" -Force
在上述路径下,新建名称为connections.json的配置文件并添加 Lakehouse 实例的连接信息,配置模板如下(如果连接两个 Lakehouse 实例,用逗号分隔):
参数说明:
| 参数名 | 说明 | 示例值 |
|---|---|---|
| is_default | 是否为默认连接配置 | true |
| service | 服务端点地址请参考文档 https://www.yunqi.tech/documents/Supported_Cloud_Platforms | 上海阿里云:cn-shanghai-alicloud.api.clickzetta.com |
北京腾讯云:ap-beijing-tencentcloud.api.clickzetta.com
北京 AWS :cn-north-1-aws.api.clickzetta.com
广州腾讯云:ap-guangzhou-tencentcloud.api.clickzetta.com
新加坡阿里云:ap-southeast-1-alicloud.api.singdata.com 新加坡AWS:ap-southeast-1-aws.api.singdata.com | | username | 用户名,用于身份验证 | "your_name" | | password | 密码,用于身份验证 | "your_password" | | instance | 实例ID,标识特定的Lakehouse实例 | "your_instanceid" | | workspace | 工作空间名称,用于数据隔离和组织 | "your_workspacename" | | schema | 数据库模式名称 | "public" | | vcluster | 虚拟集群名称,用于计算资源管理 | "default_ap" | | description | 连接配置的描述信息 | "PRD environment for marketing" | | hints | 性能优化和标识配置对象 | {...} | | hints.sdk.job.timeout | SDK作业超时时间(秒) | 300 | | hints.query_tag | 查询标签,用于查询追踪和标识 | "mcp_uat" | | name | 连接配置的名称标识 | "Shanghai production env" | | is_active | 连接是否处于活跃状态 | false | | last_test_time | 最后一次连接测试的时间戳(ISO格式) | "2025-06-30T19:55:51.839166" | | last_test_result | 最后一次连接测试的结果状态 | "success" |
步骤3:MCP Server 端:启动 MCP Server 镜像
创建docker-compose.yml文件,拷贝内容到文件中(文件内容详见附录)
在包含该文件的目录下打开终端或命令行,并执行以下命令。
docker compose up -d
预期输出:
bash-3.2$ docker compose up -d
[+] Running 4/4
✔ Network mcp_docker_clickzetta-net Created 0.0s
✔ Container clickzetta-sse Started 0.2s
✔ Container clickzetta-http Started 0.2s
✔ Container clickzetta-webui Started 0.2s
校验状态,使用docker compose ps --format "table {{.Name}}\t{{.Service}}\t{{.Status}}" 命令,预期输出如下(忽略 WARNING 信息):
bash-3.2$ docker compose ps --format "table {{.Name}}\t{{.Service}}\t{{.Status}}"
NAME SERVICE STATUS
clickzetta-http clickzetta-http Up 5 hours (unhealthy)
clickzetta-sse clickzetta-sse Up 5 hours (unhealthy)
clickzetta-webui clickzetta-webui Up 5 hours (unhealthy)
如果需要关闭,请在包含docker-compose.yml文件的目录下执行:docker compose down
步骤4:配置 Claude Desktop
本示例选择的MCP 客户端工具是Claude Desktop,主机与MCP Server 端位于同一台主机
找到并打开 Claude Desktop 配置文件:
macOS 操作步骤:
- 打开 Finder
- 按 Cmd+Shift+G
- 粘贴路径:~/Library/Application Support/Claude
- 双击打开 claude_desktop_config.json(用文本编辑器)
Windows 操作步骤:
- 按 Win+R 打开运行对话框
- 输入 %APPDATA%\Claude 并回车
- 右键点击 claude_desktop_config.json
- 选择"编辑"或"用记事本打开"
将以下内容复制到配置文件(替换原有内容或添加到mcpServers 中):
请输入 MCP Server 的地址:如果服务器与客户端运行在同一台机器上,请填写 localhost;否则,请填写服务器的 IP 地址。
{
"mcpServers": {
"clickzetta-http": {
"command": "npx",
"args": [
"-y", "mcp-remote",
"http://<YOUR_SERVER_IP>:8002/mcp",
"--allow-http",
"--transport", "http"
]
}
}
}
配置完成!
另外:Claude Desktop 支持通过多种方式连接后端的 MCP Server,以适应不同的部署环境和性能需求。上面的示例介绍了 HTTP (Streamable) 协议连接方式,如果想利用 SSE 或者 STDIO 协议连接,配置也很简单:
SSE 连接方式(远程服务)
SSE (Server-Sent Events) 是一种基于 HTTP 的长连接技术,允许服务器向客户端单向推送消息。相比于传统的轮询方式,SSE 能够以更低的延迟实现实时通信。
- 适用场景: 需要从服务器实时接收数据流或更新通知的场景。
- Docker Server 配置参考: 此方式对应启动容器中的 clickzetta-sse 的服务,该服务在8003端口上提供服务。
- 配置示例: 在Claude Desktop的claude_desktop_config.json配置文件中更新如下信息,连接到远程SSE端点。
{
"mcpServers": {
"clickzetta-remote-sse": {
"command": "npx",
"args": [
"-y", "mcp-remote",
"http://localhost:8003/sse",
"--allow-http",
"--transport", "sse"
]
}
}
}
说明:
- 请将 <YOUR_SERVER_IP> 替换为 MCP Server 实际的 IP 地址或域名。
- 目标端口为8003,端点路径为 /sse。
- -transport sse 参数指明了使用SSE通信协议。
STDIO 连接方式(本地进程)
此方式主要用于本地开发和调试。Claude Desktop 会将 MCP Server 作为一个子进程直接在本地启动,并通过标准输入/输出(STDIO)进行通信。这种方式延迟最低,但不适用于远程连接。
- 适用场景: 本地开发、单机部署。
- Docker Server 配置参考: 此方式对应启动容器中的 clickzetta-stdio 的服务,该容器镜像会随着 Claude Desktop 的开启和关闭,自动操作容器镜像拉起和停止。
- 配置示例: 在Claude Desktop的 claude_desktop_config.json 配置文件中更新如下信息,直接指定启动本地 Server 的命令。
注意:
-
配置文件中-v 后的路径中USERNAME请根据系统的实际路径进行修改。
-
请使用docker compose down关闭创建的相关容器,因为此种方式下,Claude Desktop会随着自身的开启和关闭,自动操作容器镜像拉起和停止。
{
"mcpServers": {
"clickzetta-stdio": {
"command": "docker",
"args": [
"run", "-i", "--rm",
"--stop-timeout", "60",
"-p", "8502:8501",
"-v", "/Users/derekmeng/.clickzetta:/app/.clickzetta",
"czqiliang/mcp-clickzetta-server:latest"
]
}
}
}
说明:
- command和args 直接定义了如何在本地启动 MCP Server。
- 无需指定IP地址和端口。
- -transport stdio参数指明了使用STDIO通信协议。
开始使用:
部署验证
- 打开Claude Desktop,在输入框中,发送以下指令:
列出所有 Clickzetta Lakehouse 可用的 MCP工具
如果连接成功,您将看到一个包含 50+ 个工具的列表(注意:随着版本更新,工具的具体数量可能会有变化)
- 验证WebUI界面
在您的浏览器中访问以下地址:http://localhost:8503,预期可以展示以下页面:
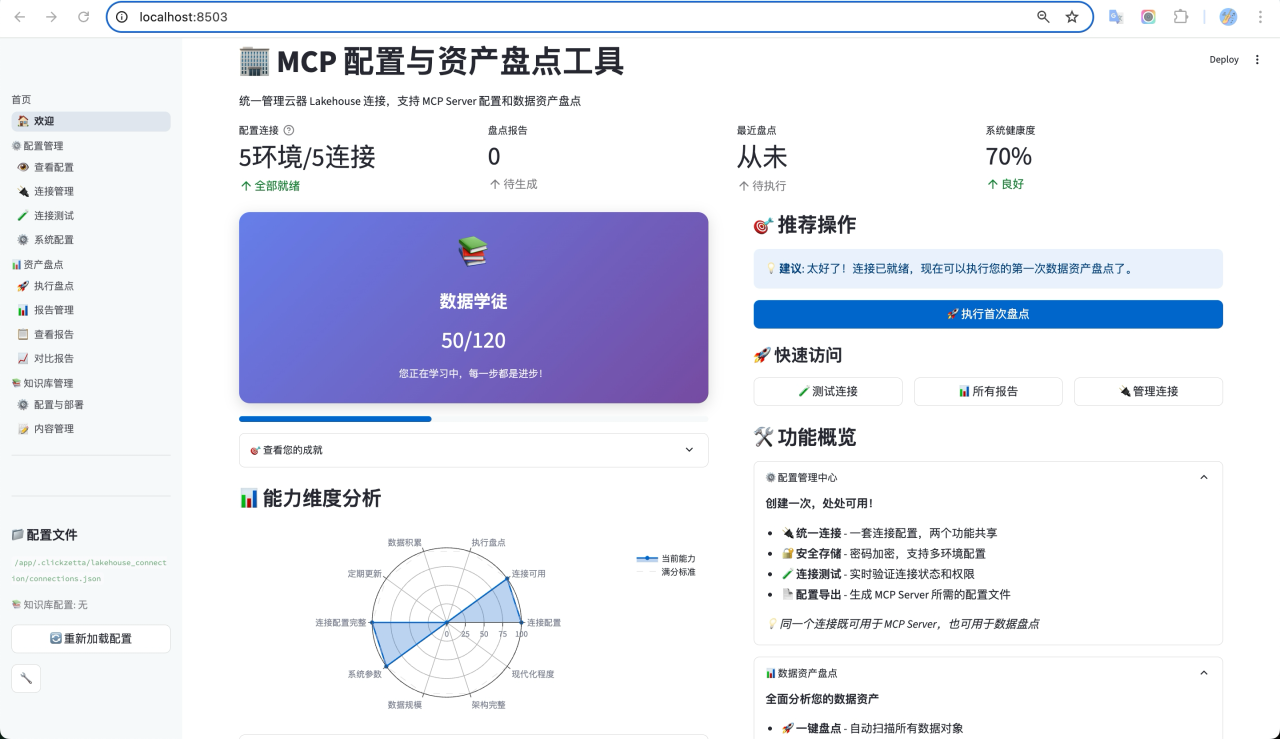
如果以上两个步骤都顺利完成,恭喜您,您的应用已成功安装!
第二步:配置您的第一个数据源 (Lakehouse)
接下来,让我们配置一个Lakehouse连接,以便Claude可以访问您的数据。
1、打开连接管理器
访问WebUI界面http://localhost:8503,然后在左侧菜单中选择「连接管理」。
2、添加并填写连接信息
点击「添加新连接」按钮,并根据提示准确填写您的Lakehouse连接信息(如主机、端口、凭证等)
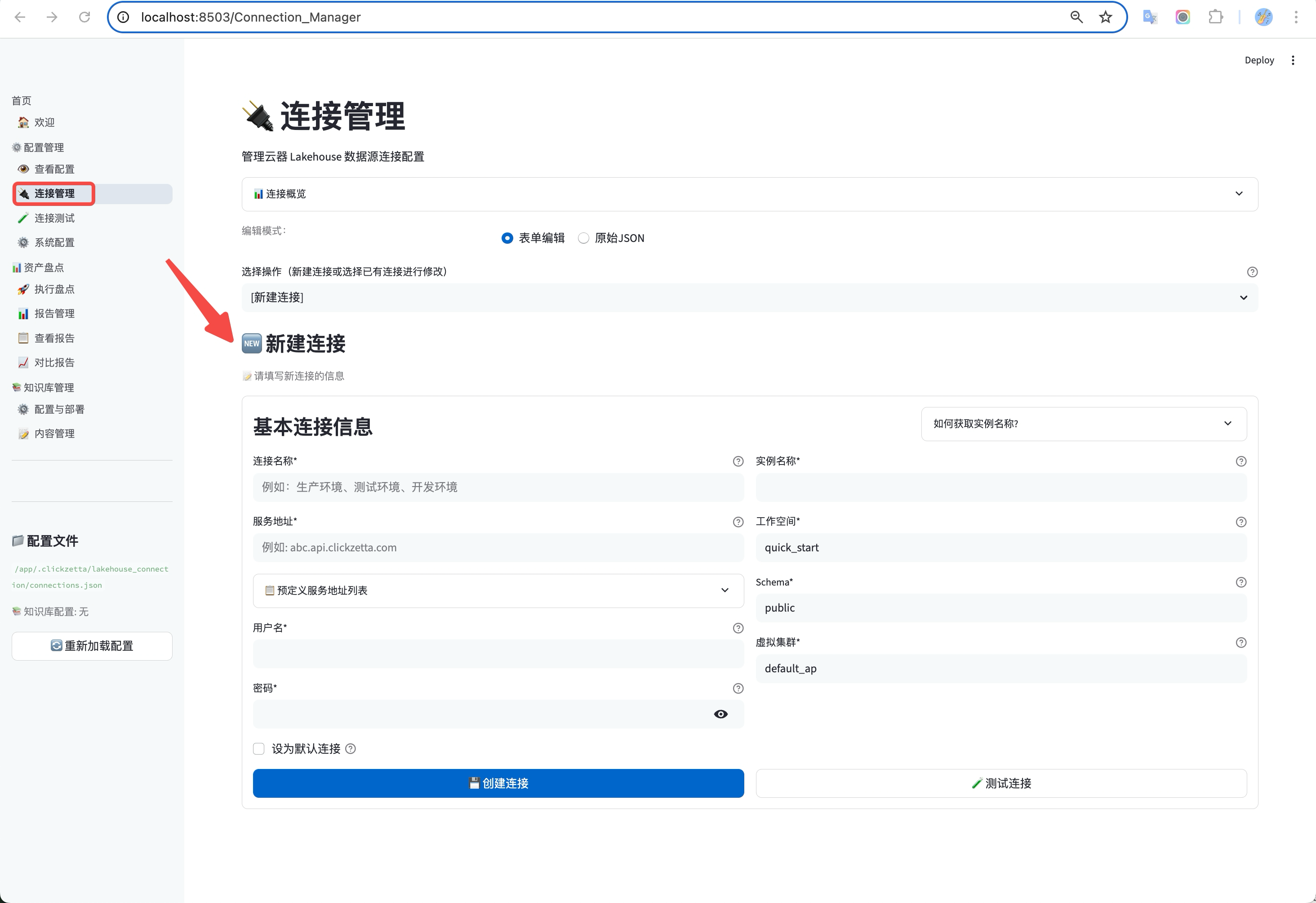
测试并保存
- 填写完毕后,点击「测试连接」按钮,确保所有配置信息无误且网络通畅。
- 测试通过后,点击「保存」完成配置。
第三步:开始您的第一个查询
现在一切准备就绪!您可以开始与您的数据进行交互了。尝试在Claude Desktop中提问:
"帮我看下有哪些 Lakehouse 实例"
高级配置:配置云器产品文档知识库
这个步骤会将云器Lakehouse产品知识库表集成进来,构建一个智能问答知识库。配置完成后,您将能够在MCP Client(如Claude Desktop)中,通过自然语言提问的方式,快速获得关于Lakehouse操作的官方指导和答案。
该功能的核心是利用嵌入服务 (Embedding) 和向量搜索 (Vector Search) 技术,将非结构化的文档转化为可供机器理解和检索的知识库。
第一步:配置嵌入服务
此步骤的目的是告诉MCP系统如何将用户的“问题”也转换成向量,以便在知识库中进行匹配。
1、在MCP Server管理界面,从左侧导航栏进入「系统配置」。
2、在主配置区,选择 「嵌入服务」 标签页。
3、找到并填写 DashScope 配置(默认)部分:
- API Key :粘贴您的阿里云百炼平台的 API 密钥。这是调用模型的身份凭证,请妥善保管。
- 向量维度 (Vector Dimension) :输入您选择的嵌入模型所输出的向量维度。此值必须与知识库文档向量化时使用的维度完全一致。例如,截图中 text-embedding-v4 模型的维度是 1024。
- 嵌入模型 (Embedding Model) :选择或填写用于将文本转换为向量的模型名称,例如 text-embedding-v4。
- 最大文本长度 (Max Text Length) :设置模型一次可以处理的文本单元(Token)的最大数量。如果问题过长,超出部分将被忽略。
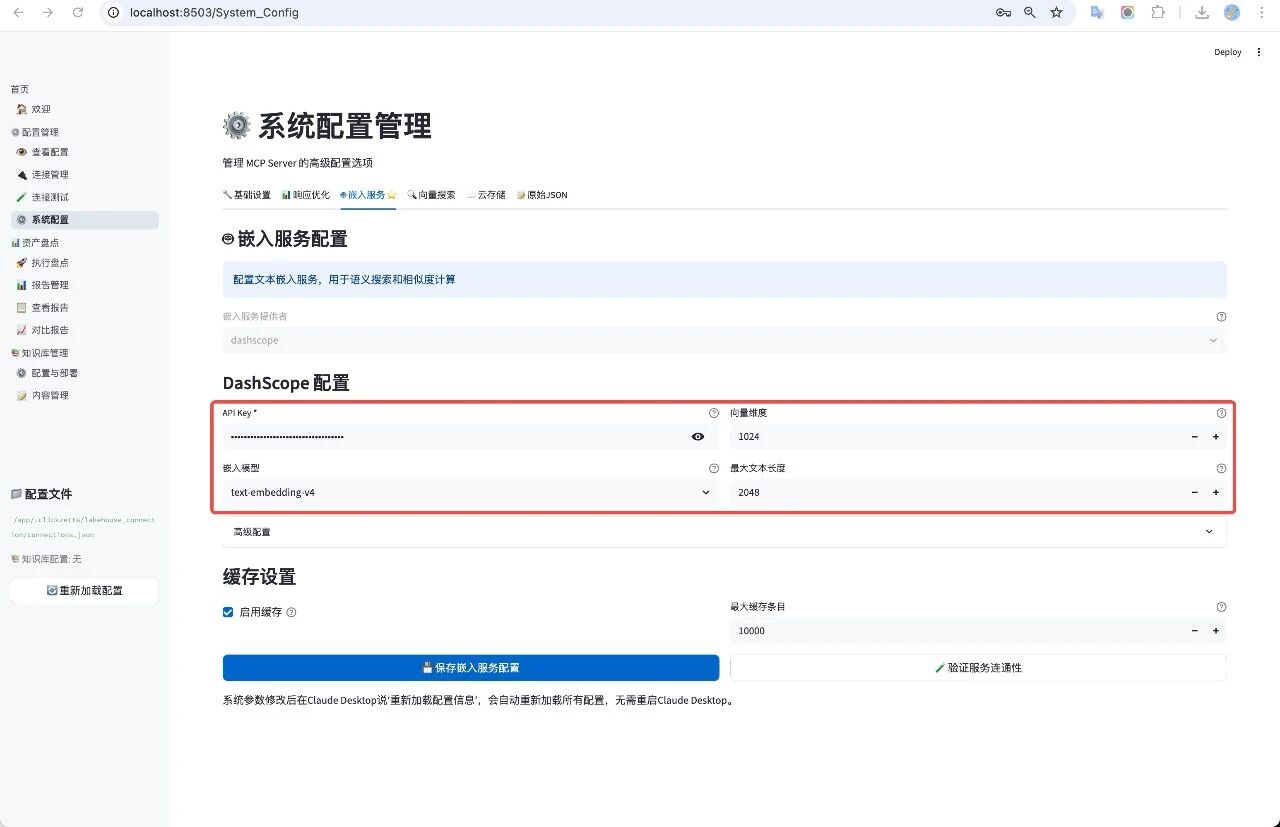
- 点击保存嵌入服务配置 按钮。
第二步:配置向量搜索
此步骤的目的是告诉MCP系统去哪里、以及如何搜索已经存储好的文档知识库。
-
在系统配置 页面,切换到 「向量搜索」 标签页。
-
填写向量表配置 部分:
- 向量表名称 (Vector Table Name) :准确填写存储了文档向量的完整表名。格式通常为数据库名.模式名.表名,例如clickzetta_sample_data.clickzetta_doc.kb_dashscope_clickzetta_elements。
- 嵌入列 (Embedding Column) :填写该表中用于存储文本向量的列名,例如 embeddings。
- 内容列 (Content Column) :填写该表中用于存储原始文本内容的列名,例如 text。当系统找到相关答案时,这里的内容会作为主要参考。
- 其他列 (Other Columns) :可选。填写您希望一并检索出的元数据列,如 file_directory, filename,这有助于用户追溯信息的原始出处。
- 配置 搜索参数:保持默认即可,如果想进行修改,请参考下面的说明:
- 距离阈值 (Distance Threshold) :设置一个相似度匹配的严格程度。系统会计算问题向量与文档向量之间的“距离”,只有距离小于此值的文档才会被视为相关。值越小,代表匹配要求越严格。通常建议从0.80 开始尝试。
- 返回结果数 (Number of Results to Return) :定义单次查询从数据库中检索出的最相关文档的数量。例如,设置为5表示每次找出5个最相关的文档片段。
- 启用重排序 (Enable Reranking) :勾选此项后,系统会对初步检索出的结果进行二次智能排序,以提高最准确答案出现在最前面的概率。
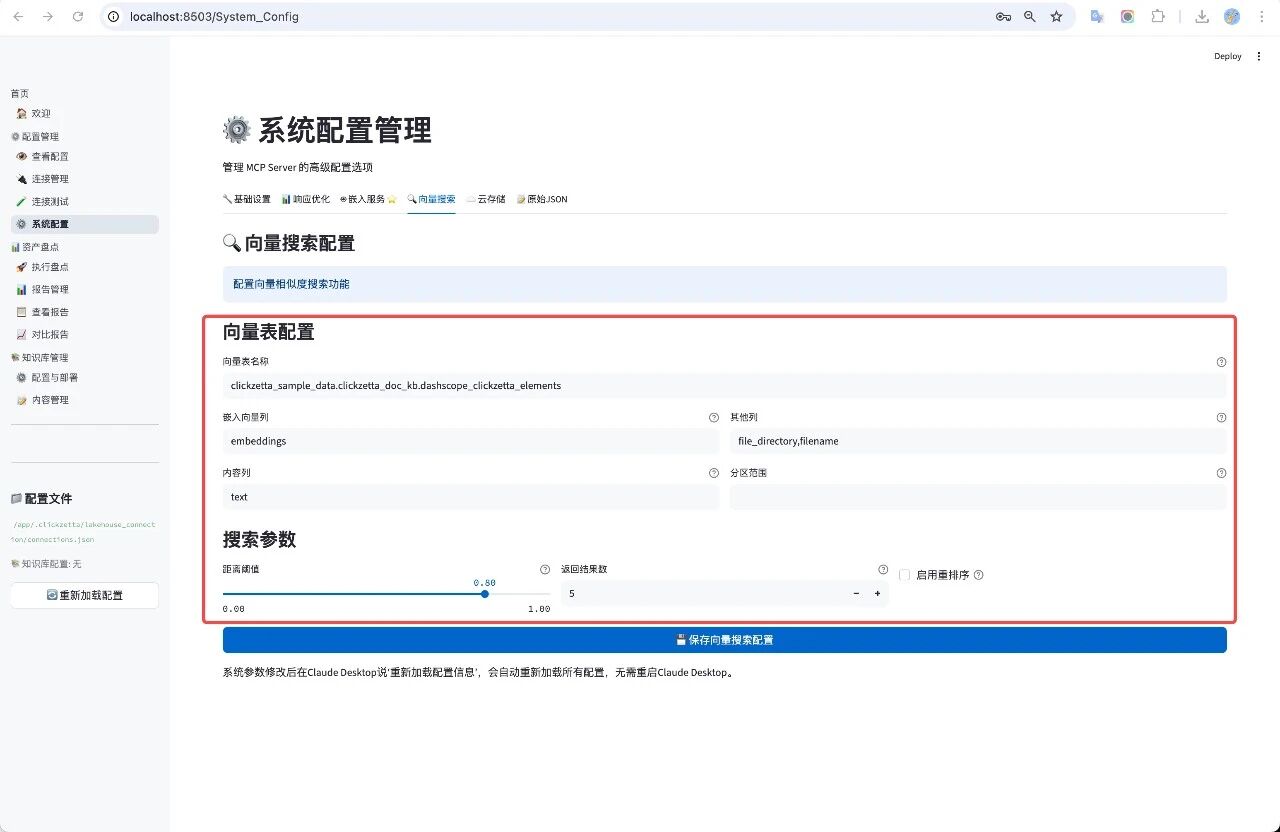
- 点击保存向量搜索配置按钮。
其他典型使用场景
请参考公众号文章:
MCP Server 如何助力 Lakehouse 实现 AI 驱动的 6 大数据应用场景
我们期待与您一起探索 AI 驱动的数据分析新时代!
附录
- 创建docker-compose.yml文件内容,详见:
https://www.yunqi.tech/documents/LakehouseMCPServer_intro
- Lakehouse MCP工具列表:
| 序号 | 工具名称 | 功能类别 | 主要功能 | 支持操作 |
|---|---|---|---|---|
| 1 | read_query | 数据查询 | 执行SELECT查询并返回结果 | 支持自动结果限制,Spark SQL兼容 |
| 2 | write_query | 数据操作 | 执行写操作SQL语句 | INSERT/UPDATE/DELETE/CREATE/DROP |
| 3 | vector_search | AI搜索 | 对表执行向量搜索/知识检索 | 智能列名推断,支持分区过滤 |
| 4 | match_all | 全文搜索 | 使用MATCH_ALL函数进行全文搜索 | 自动检测可搜索文本列 |
| 5 | get_product_knowledge | 知识检索 | 从向量数据库中搜索产品知识 | 语义相似性搜索 |
| 6 | show_object_list | 对象管理 | 列出数据库对象,支持智能筛选 | 智能分析、精确统计、过滤建议 |
| 7 | desc_object | 对象查看 | 获取数据库对象的详细信息 | 支持扩展模式、历史信息、索引信息 |
| 8 | desc_object_history | 版本管理 | 查看对象的历史版本和变更记录 | 支持TABLE/VIEW/FUNCTION/PIPE |
| 9 | drop_object | 对象删除 | 安全删除各种类型的数据库对象 | 确认机制、UNDROP提示 |
| 10 | restore_object | 时间旅行 | 将对象恢复到指定历史时间点 | 支持表、动态表、物化视图 |
| 11 | undrop_object | 对象恢复 | 恢复被删除的对象 | 支持表、动态表、物化视图 |
| 12 | create_table | 表创建 | 创建ClickZetta表,支持完整语法 | 分区、分桶、索引、约束、生成列 |
| 13 | create_external_table | 外部表 | 创建外部表(Delta Lake格式) | 仅支持Delta Lake,对象存储 |
| 14 | create_dynamic_table | 动态表 | 创建动态表,自动维护查询结果 | 自动刷新、增量更新 |
| 15 | create_table_stream | 流表 | 创建表流,用于捕获表变更数据 | CDC功能,跟踪INSERT/UPDATE/DELETE |
| 16 | create_schema | 模式创建 | 创建新的SCHEMA(数据模式) | 逻辑分组,权限管理 |
| 17 | create_external_schema | 外部模式 | 创建外部SCHEMA映射 | 基于CATALOG CONNECTION |
| 18 | create_catalog_connection | 目录连接 | 创建外部元数据目录连接 | 支持Hive、OSS、Databricks |
| 19 | create_external_catalog | 外部目录 | 创建外部CATALOG挂载 | 基于已创建的CATALOG CONNECTION |
| 20 | create_storage_connection | 存储连接 | 创建存储系统连接 | HDFS、OSS、COS、S3、Kafka |
| 21 | create_api_connection | API连接 | 创建API CONNECTION用于云函数 | 阿里云FC、腾讯云函数、AWS Lambda |
| 22 | create_volume | 存储卷 | 创建EXTERNAL VOLUME访问对象存储 | 自动验证bucket存在性 |
| 23 | put_file_to_volume | 文件上传 | 将文件上传到Volume存储 | 支持URL、本地文件、直接内容 |
| 24 | get_file_from_volume | 文件下载 | 从Volume下载文件到本地 | 支持单个或批量文件下载 |
| 25 | list_files_on_volume | 文件列表 | 列举Volume中的文件列表 | 支持子目录浏览、正则筛选 |
| 26 | remove_file_from_volume | 文件删除 | 从Volume删除文件或目录 | 支持文件和目录删除 |
| 27 | create_index | 索引创建 | 创建索引 | VECTOR/INVERTED/BLOOMFILTER三种类型 |
| 28 | create_function | UDF创建 | 创建基于SQL的用户自定义函数 | 仅支持SQL表达式和查询 |
| 29 | create_external_function | 外部函数 | 创建外部函数,支持Python/Java代码 | 云函数执行,复杂业务逻辑 |
| 30 | package_external_function | 函数打包 | 智能打包Python外部函数及依赖 | 生产/开发/Docker三种模式 |
| 31 | get_external_function_guide | 函数指南 | 获取外部函数开发指南 | Python开发规范、最佳实践 |
| 32 | get_external_function_template | 函数模板 | 获取外部函数开发模板 | AI文本、多模态、向量、业务场景 |
| 33 | create_pipe | 管道创建 | 创建PIPE管道用于自动化数据导入 | 智能模式、手动模式 |
| 34 | alter_pipe | 管道修改 | 修改PIPE属性 | suspend/resume、批处理参数 |
| 35 | create_vcluster | 集群创建 | 创建虚拟计算集群 | 资源隔离、工作负载管理 |
| 36 | alter_vcluster | 集群修改 | 修改计算集群配置 | 启停、属性配置、说明更新 |
| 37 | get_current_context | 上下文查看 | 获取当前连接的上下文信息 | 连接、WORKSPACE、SCHEMA、VCLUSTER |
| 38 | switch_context | 上下文切换 | 切换当前上下文 | 会话级切换,智能路由 |
| 39 | switch_vcluster_schema | 环境切换 | 切换虚拟集群和模式 | 在当前workspace内切换 |
| 40 | switch_workspace | 工作空间 | 切换workspace | 重新建立数据库连接 |
| 41 | switch_lakehouse_instance | 实例切换 | 切换多云环境或Lakehouse环境 | 多云、多环境、多地域切换 |
| 42 | import_data_src | 数据导入 | 从URL、文件路径或Volume导入数据 | 支持多种格式,三种写入模式 |
| 43 | import_data_from_db | 数据库导入 | 从外部数据库导入数据 | MySQL、PostgreSQL、SQLite |
| 44 | preview_volume_data | 数据预览 | 对Volume文件进行SQL查询分析 | 预览模式、导入模式 |
| 45 | alter_dynamic_table | 动态表修改 | 修改动态表属性 | suspend/resume、注释、列操作 |
| 46 | modify_dynamic_table_data | 动态表数据 | 对动态表执行数据修改操作 | INSERT/UPDATE/DELETE/MERGE |
| 47 | refresh_dynamic_table | 动态表刷新 | 手动刷新动态表数据 | 立即刷新数据 |
| 48 | create_knowledge_base | 知识库创建 | 创建知识库,支持文档向量化 | 非结构化ETL管道 |
| 49 | add_knowledge_entry | 知识添加 | 添加知识条目到向量数据库 | 产品知识、技术规范存储 |
| 50 | add_data_insight | 洞察记录 | 添加数据洞察到备忘录 | 分析过程中的重要发现 |
| 51 | manage_share | 共享管理 | 管理SHARE对象 | 跨实例数据共享,OUTBOUND/INBOUND |
| 52 | show_job_history | 作业历史 | 查询系统级作业执行历史 | 性能分析、问题排查 |
| 53 | show_table_load_history | 加载历史 | 查询表的COPY操作加载历史 | 文件导入历史追踪(7天保留) |
| 54 | smart_crawl_to_volume | 智能爬取 | 智能抓取URL内容到Volume | sitemap、网页、文档抓取 |
| 55 | smart_crawl_url | 网页抓取 | 智能网页内容抓取 | 高级提取策略、智能分块 |
| 56 | crawl_single_page | 单页抓取 | 单页面网页抓取 | CSS选择器、原始HTML |
| 57 | get_operation_guide | 操作指南 | 获取特定操作的综合指南 | 详细步骤、最佳实践、常见问题 |
| 58 | run_happy_paths | 演示路径 | 执行Lakehouse快乐路径演示 | 关键功能展示、完整使用流程 |
🎁 新用户专享福利
✅ 1 TB 存储 · 1 CRU时/天计算 · 1 年全托管体验
➤ 即刻访问云器官网领取:https://www.yunqi.tech/product/one-year-package
