
📌 导语:
大数据平台面临一个根本性矛盾:用于分析的数据字段可(灵活)调整与数据的加工和分析(性能)的矛盾。
Spark查询JSON灵活但慢(数十分钟),ClickHouse查询宽表快(秒级)但Schema固化。每次业务需要新的查询维度,都需要平台团队开发ETL、打平JSON、写入ClickHouse,耗时至少1天。
数美科技每天100亿次风控请求,2PB半结构化日志需要高频即席分析。业务人员发现异常后需要立即多维下钻,但传统架构将”秒级需求”拉长到”天级响应”。
2024年8月起,我们基于云器Lakehouse突破了这个悖论:让JSON半结构化数据具备宽表级查询性能。 最终实现业务人员 “定义即可查” ——定义SQL即可直接在500TB原始JSON上秒级查询,无需ETL、无需等待。
本文分享数美科技的技术实践:
- 如何让数百TB级JSON半结构化数据实现秒级查询
- 如何让业务人员从”提需求等1天”到”定义即可查”
- 云器Lakehouse如何突破”灵活性vs性能”的技术矛盾
一、业务背景与原有架构
1.1 日均百亿次请求:风控场景下的数据挑战
数美科技成立于2015年,专注于为互联网企业提供全栈式业务安全解决方案。凭借先进的AI技术和大数据分析能力,在内容安全、营销反欺诈、账户安全、设备指纹等领域建立了强大的技术壁垒。
目前,数美的服务已覆盖金融、电商、社交、直播、游戏等多个行业,为超过1000家企业提供风控服务,包括工商银行、银联、小红书、爱奇艺等头部企业。每天超过100亿次的请求处理量,不仅体现了数美在行业中的领先地位,也对底层数据架构提出了极为严苛的要求。
1.2 五大系统并存:2PB数据的分散式管理困境
数美的核心业务依赖海量风控数据的实时分析与决策。在2PB级存储规模、每天百TB级增量数据的压力下,我们需要支撑以下四类关键场景:
场景一:原始明细日志的即席查询分析
- 数据特征:JSON格式半结构化日志,10层以上嵌套,上千个字段
- 查询需求:业务人员需要在百TB级单表上进行多维度分析
- 现实困境:受限于Spark查询性能,只能由平台人员针对特定列提取数据,展开打平后写入ClickHouse,业务人员再从ClickHouse查询,一个需求至少需要1天响应时间
场景二:离线加工与特征提取
- 通过HBase进行数据特征提取
- Spark进行T+1批量数据离线加工
场景三:AI训练数据抽样
- 从原始明细日志中抽样数据
- 提供给AI平台进行算法/模型训练
场景四:全文检索
- 通过Elasticsearch进行日志检索及数据提取
- 支持快速定位问题和异常分析
为满足这些场景,我们构建了基于传统Hadoop生态的复杂架构:
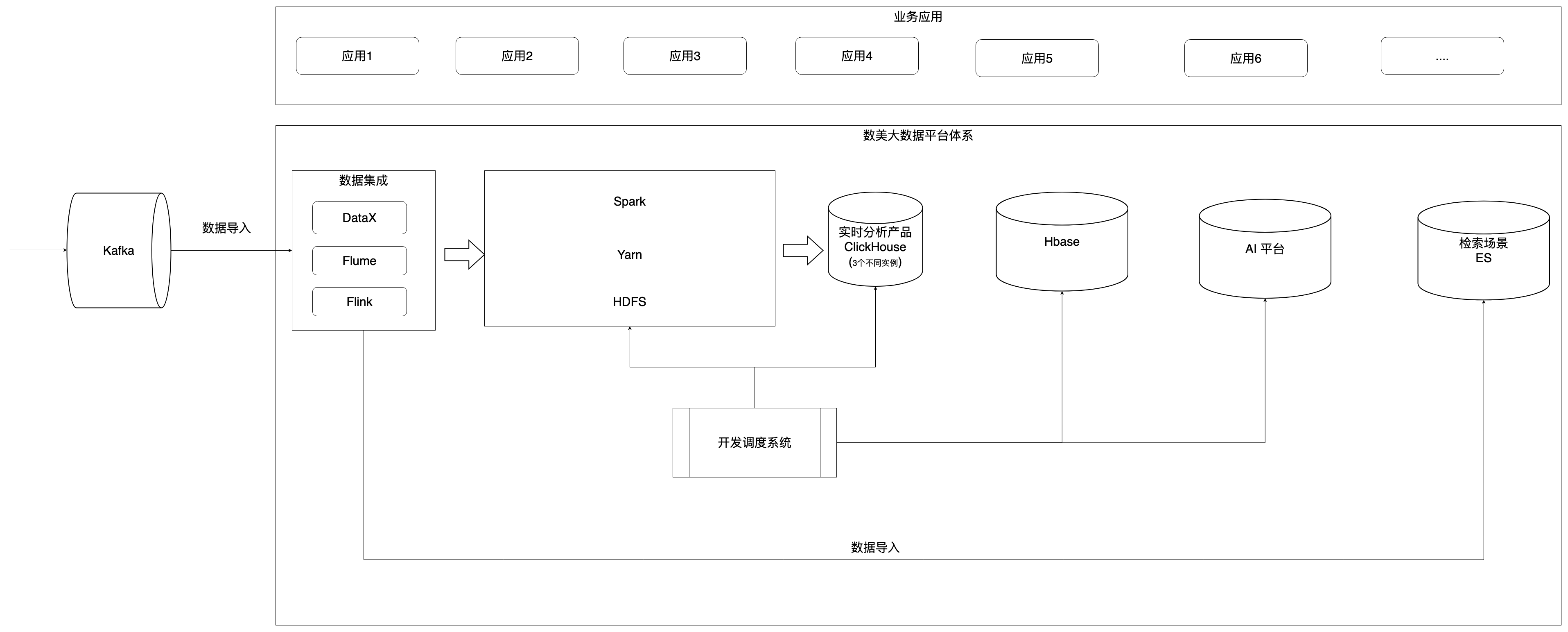
(图:数美原有系统架构)
(图:数美原有系统架构)
如图所示,五大系统各司其职:Spark负责离线计算、HBase提取特征、ClickHouse支撑即席查询、ES处理日志检索、AI平台进行模型训练。这种架构在业务早期满足了功能需求,但随着数据规模的爆发式增长,弊端逐渐显现。
二、架构矛盾与技术突破
2.1 灵活性与性能的架构矛盾
随着数据规模从TB级向PB级跨越,传统架构陷入”灵活性与性能”的根本性矛盾。
风控业务需要对原始JSON日志进行高频即席分析:今天按user_id分析,明天可能按device_fingerprint分析;查询维度不固定,10层以上嵌套、上千个字段无法预知。但Spark查询JSON虽然灵活,百TB级数据扫描耗时数十分钟;ClickHouse查询宽表虽然秒级,但Schema固化,每次新增字段都需要ETL开发,流程变成:提需求 → 打平JSON → 写入CK → 次日分析。要灵活性就没性能,要性能就没灵活性。
为了平衡这个矛盾,数美科技构建了五套系统各司其职的架构。这带来了连锁问题:数据分散多平台需要来回切换,同一份数据在五个系统各存一份,五套独立集群资源无法共享整体利用率不足30%,五套技术栈和监控体系使运维复杂度居高不下。但这些都是表象,根源在于技术架构无法同时满足灵活性和性能。
2.2 重新定义选型标准
面对架构升级,我们明确了核心诉求:必须让JSON半结构化数据同时具备灵活性和性能。
传统选型思路是”功能拆分”,但业务需要的是”既灵活又快”,而不是”要么灵活要么快”。新平台必须满足:
- 灵活性 :业务人员直接在原始JSON日志上查询,无需提前定义Schema,无需ETL开发
- 高性能 :单表500TB的JSON数据,查询性能达到秒级,不逊于ClickHouse宽表
- 降低复杂度 :能够支撑更多场景,减少多系统架构带来的数据冗余和运维成本
同时考虑:运维简化(全托管服务)、出海支持(多云部署能力)。
2.3 云器Lakehouse的技术突破
经过POC验证,云器Lakehouse的核心能力实现了技术突破:
关键技术:JSON类型优化 + 生成列技术 + 自动索引
- 云器Lakehouse支持原生JSON类型字段,并在存储计算层面做了大量优化
- 对嵌套结构内的key可灵活自定义生成列,SQL操作,追加即可,灵活方便
- 对生成列实现自动索引,实现更好的数据裁剪,提升性能
让JSON半结构化数据同时拥有灵活性和宽表级性能:
- 保持JSON灵活性:业务人员想查哪个字段就查哪个,嵌套10层也能直接访问
- 获得宽表性能:自动索引让查询性能达到秒级
这意味着业务人员定义SQL即可直接在原始JSON上得到结果,无需”提需求 → 等ETL → 次日查询”,平台团队无需针对每个需求开发ETL,真正实现**“定义即可查”**。
其他关键能力:
- 一体化架构:存算分离设计,一份数据支持离线加工、实时分析、全文检索等多场景应用,解决了数据冗余和资源隔离问题。
- 企业级能力:全托管服务降低运维复杂度,7×24小时支持保障稳定性,完整的任务管理、数据血缘、权限管理体系满足企业需求。
2.4 期望达成的目标
基于云器Lakehouse的能力,我们制定了明确目标:
- 核心技术突破:让业务人员直接在500TB原始JSON日志上秒级查询,实现”定义即可查”
- 业务价值目标:需求响应从1天缩短至秒级,业务人员实现分析自闭环
- 架构目标:用一套平台替代Spark + ClickHouse + ES,逐步整合HBase和AI平台数据
- 成本目标:整体存储+计算成本降低50%以上(一体化架构带来的附加收益)
三、实战验证:成本减半、性能翻倍的落地实践
经过3个月的POC验证(2024年8-9月)和分阶段上线,云器Lakehouse在生产环境中稳定运行,各项目标均得到验证。
3.1 从”五套系统”到”一体化平台”:架构演进之路
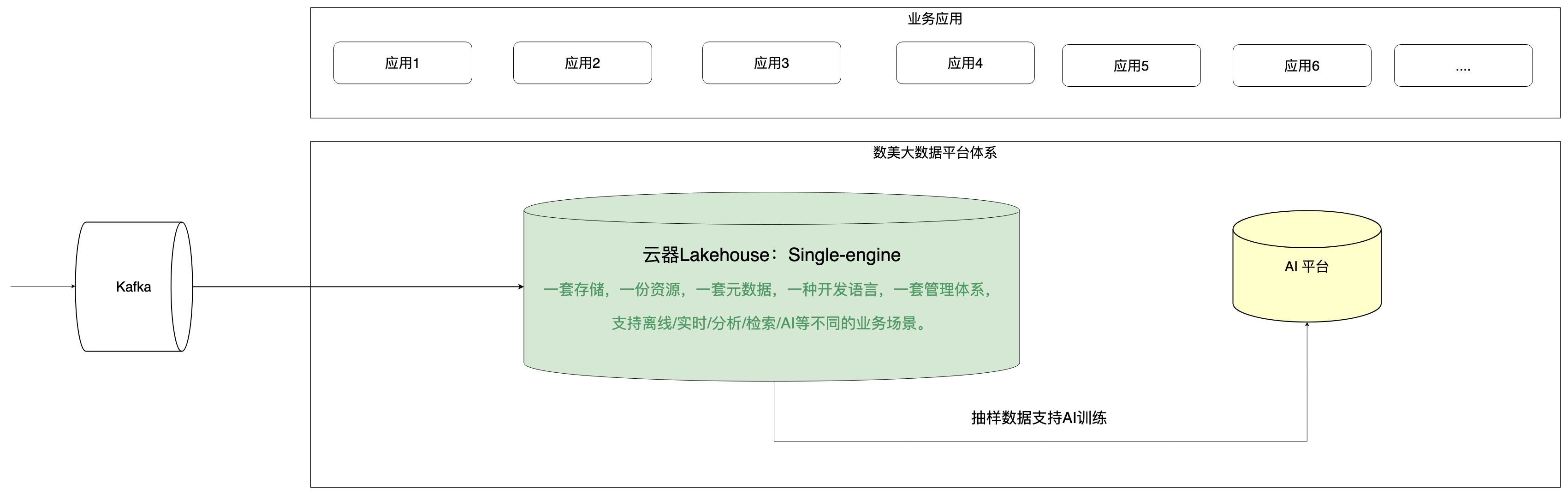
(图:数美升级后的系统架构图)
(图:数美升级后的系统架构图)
升级后的架构实现了根本性变革:
| 维度 | 升级前 | 升级后 |
|---|---|---|
| 存储 | Spark HDFS、HBase、ClickHouse、ES各存一份 | 云器Lakehouse统一存储 |
| 计算 | 5套独立集群,资源隔离 | 统一资源池,弹性调度 |
| 数据分析 | 业务提需求 → 平台提数 → 隔日分析 | 业务人员直接自助查询分析 |
| 平台角色 | 疲于支持”提数”需求 | 专注平台能力建设 |
一体化带来的核心价值:
- 数据只存一份,支持离线加工、实时分析、全文检索、点查等多场景
- 业务人员在同一平台完成所有分析工作,无需跨系统切换
- 平台团队从”需求响应”转向”平台建设”,价值释放
3.2 存储降68%、计算降66%:成本优化的技术密码
整体成本优化成果:
整体存储+计算成本降低50%,具体拆解:
- 存储成本:整体存储size降低68%(原100TB存储,现在只需32TB)
- 离线加工计算:计算资源降低66%
- 实时分析计算:计算资源降低30%
降本增效的技术说明:
| 领域 | 因素 | 细节说明 |
|---|---|---|
| 存储 | • 一体化平台支持离线/实时/分析/检索场景,减少数据冗余存储, • 同一份数据云器Lakehouse有更高的压缩比 • 存算分离带来的资源独立扩展,减少浪费 | • Hdfs 两份 + CK 一份 -> 云器Lakehouse 一份 • Hdfs 两份 + ES 一份 -〉云器Lakehouse 一份 • 整体存储size整体降低68% 左右(降低到原来的32%) • 相对于hdfs单份数据的压缩,也能降低20%-30%的size • 存储在COS上,可单独无限扩展 • 基于对象存储,拥有天然的分层存储能力,无需导数据即可实现分层存储 |
| 计算 | • 新一代向量化增量计算引擎,带来更多的数据加工/查询性能的提升,进而实现降本 • 存算分离带来的资源独立扩展,减少浪费 | • 相对于开源的Spark任务加工,在数美的业务场景下,性能提升3倍 • 相对于Clickhouse,查询性能也提升30%左右 ,并且复杂关联查询提升更多 • 计算资源可独立扩展,解决存算一体模式下,存储扩容需要同时扩容计算,导致计算资源浪费的问题 |
| 运维 | • 云器全托管服务,用户只需要关注自己业务就行 | • 为数美独立部署全托管服务,服务运维全在云器侧 • 数美驻需要关注业务相关任务即可 • 7*24小时服务体系 |
| 开发 | • 一体化平台,减少数据导入导出 • 减少多平台,多任务,多语言开发,降低任务开发门槛,提升开发效率 | • 数据都在云器Lakehouse内部,无需导出即可满足多场景业务需求,减少导入导出任务开发和资源成本 • 云器一套SQL语言支持多场景,代替传统的scala/java/python/sql 等多种语言 |
| 长期持续降本能力 | • 平台持续优化带来的持续降本能力 | • 云器Lakehouse每年的性能都会有大量优化; ◦ 每年30%的资源增长支撑70%的业务增长,核心在平台本身的性能持续优化 • 存储的持续优化:更优的压缩比,更好的存储策略,更优的索引机制等 |
3.3 技术范式突破:JSON半结构化数据的”定义即可查”
这是整个实践中最关键的技术验证——让JSON半结构化数据同时拥有灵活性和宽表级性能。实现业务人员的”定义即可查”,即取消原来ETL开发的过程,变成即时的高性能复杂查询,以支撑业务分析的灵活性。
云器Lakehouse对JSON类型字段的嵌套key实现自动索引,使半结构化数据具备宽表级查询性能。技术对比如下:
| 方案 | 灵活性 | 性能 | 业务流程 |
|---|---|---|---|
| Spark查JSON | ✅ 灵活(想查什么查什么) | ❌ 慢(数十分钟) | 业务无法即时分析 |
| CK宽表 | ❌ 固化(需预定义Schema) | ✅ 快(秒级) | 提需求→ETL开发→次日查询 |
| 云器Lakehouse | ✅ 灵活(原始JSON) | ✅ 快(秒级) | 定义即可查,无需ETL |
这不是妥协,是范式突破 :业务人员定义SQL查询,直接在原始JSON日志上秒级得到结果,无需等待ETL开发和数据转换,真正实现”发现问题→定义查询→立即分析→快速响应”的敏捷闭环。
3.3.1 单表数百TB级JSON半结构化日志查询分析
测试规模:
- 数据量:数百TB单表数据,千条生产查询SQL
- 查询分布:50%查询1天范围内数据,50%查询3天-1个月范围数据
- 资源配置:16 CRU (128 Core),1 replica AP集群
性能测试结果:
| 测试场景 | 平均 QPS | 平均响应时间 | 中位数响应时间 | 95%分位数 |
|---|---|---|---|---|
| 单并发(当天查询sql 和其他周期sql 比例 5:5) | 1 | 517ms | 174ms | 1,984ms |
| 多并发(全部为当天查询 SQL ) | 30.8 | 254.6ms | 119ms | 888.8ms |
| 多并发(当天查询 SQL和其他周期查询 SQL比例 8:1 ) | 18 | 410.97ms | 192ms | 1370.8 |
关键发现:
- 中位数响应时间在100-200ms级别,大部分查询实现毫秒级响应
- 95%分位数在1-2秒内,即使复杂查询也能保持秒级性能
- 多并发场景下,系统仍能保持高吞吐(QPS 18-30)和低延迟
这意味着业务人员在数百TB数据上的即席查询,可以获得与传统OLAP数据库(如ClickHouse)相当的性能体验。
3.3.2 替换ES:文本误杀场景的性能验证
业务场景 : 内容审核中的文本误杀排查,需要批量查询上千个requestId,快速定位误判问题。原先Spark平台计算需要30分钟以上,业务方希望优化到10分钟以内。
云器Lakehouse性能表现:
| 缓存状态 | 执行时间 | 业务满足度 |
|---|---|---|
| 冷启动 (无cache) | 1.4 分钟 | ✅ 满足10分钟要求 |
| 热查询 (有cache) | 2.8秒 | 🚀 秒级响应 |
性能提升分析:
- 冷启动场景下,查询时间从30分钟降至1.4分钟,性能提升20倍, 超出业务预期
- 热查询场景下,直接实现秒级响应
- 这一结果验证了云器Lakehouse可以直接替代ES的检索能力,且性能更优
3.3.3 替换ClickHouse:3个CK实例合并的全面验证
迁移目标 : 将ae/fp/main三个独立的ClickHouse实例合并到一个云器Lakehouse平台,在降低资源成本的同时,打破数据孤岛,实现跨数据源关联分析。
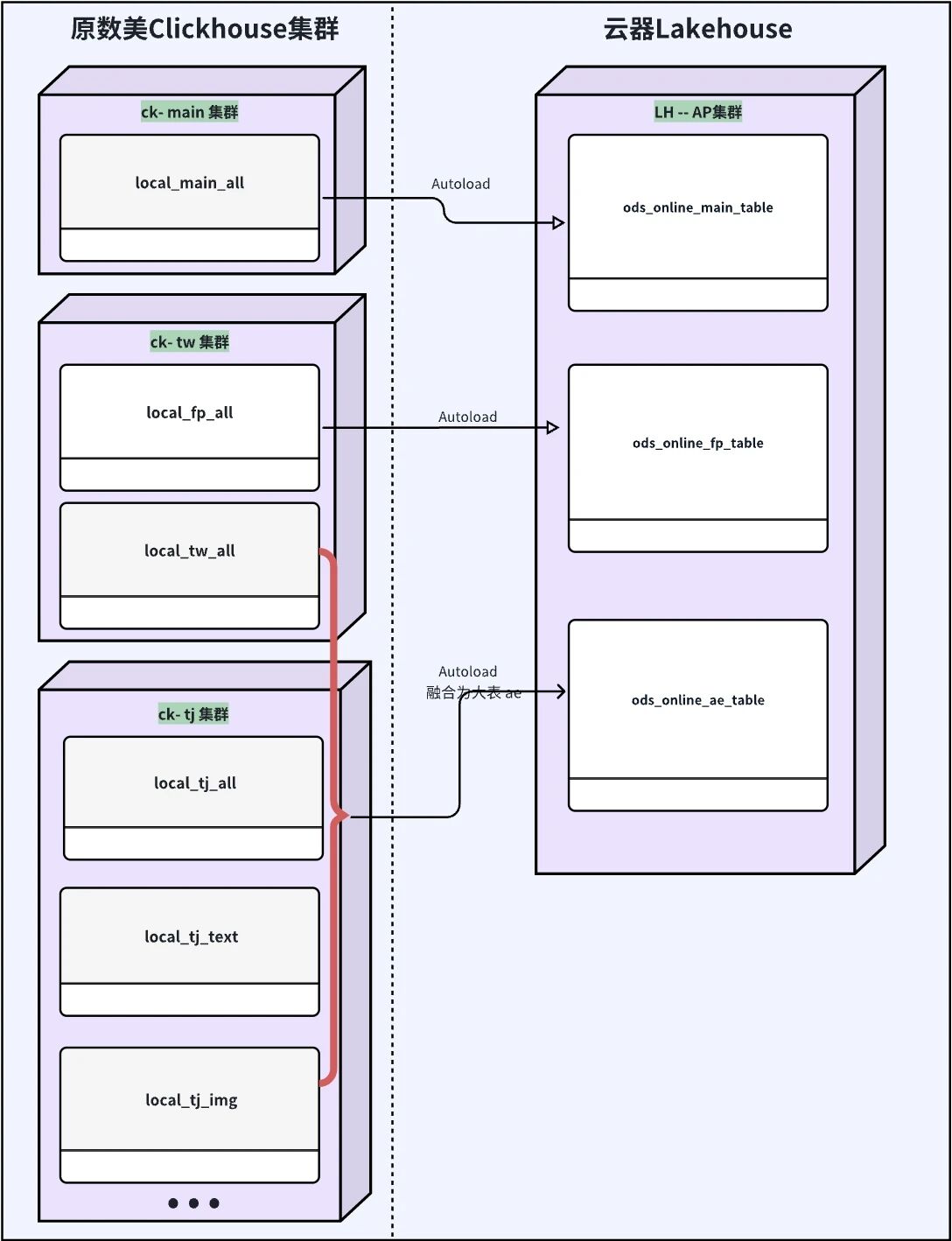
(图:ClickHouse vs 云器Lakehouse)
(图:ClickHouse vs 云器Lakehouse)
数据导入效果:
- 完成ae/fp/main全量数据近实时导入,每天增量数据30+TB(导入前压缩的数据量)
- 数据新鲜度:10分钟内
- 导入后数据单副本Size压缩50%以上
- 导入资源成本可控,支持线性扩展
查询性能对比:
在资源降低40%(对比最大的CK集群)的情况下:
- ae/fp/main数据查询P99性能均保持在秒级别
- 完全满足业务查询要求
- 相对ClickHouse,复杂关联查询性能提升30%以上
四、技术范式突破的价值与经验
4.1 范式突破:消解”灵活性vs性能”的矛盾
传统数据架构存在一个根本性矛盾:要灵活性就牺牲性能(Spark查JSON),要性能就牺牲灵活性(ClickHouse宽表)。所有数据平台都在这个矛盾中做妥协。
云器Lakehouse的技术突破在于:用技术手段消解了这个悖论。
通过对JSON嵌套key的自动索引,让半结构化数据同时拥有:
- JSON的灵活性 :业务人员想查什么字段就查什么,无需预定义Schema
- 宽表的性能 :查询性能达到秒级,不逊于传统OLAP数据库
这不是在两者之间找平衡,而是突破了传统架构的技术约束,开辟了新的可能性。
4.2 业务价值:从”天级响应”到”定义即可查”
核心价值 :让业务人员从”提需求 → 等ETL → 次日分析”变为”定义即可查”
什么是”定义即可查”?
- 业务人员定义SQL查询需求,就能直接在原始JSON上秒级得到结果
- 无需等待平台团队开发ETL、转换数据
- 从”定义”到”查询结果”,中间不再有等待环节
技术层面验证:
- 单表500TB的JSON数据实现秒级查询
- 替代Spark、ClickHouse、ES三套系统
- 存储+计算成本降低50%(一体化架构的附加收益)
业务层面价值:
- 风控异常发现后,可立即定义查询逻辑进行多维分析,响应速度从1天缩短至秒级
- 业务人员无需依赖平台团队”提数”,真正实现分析自闭环
- 平台团队从重复性ETL开发中解放,专注平台能力建设
4.3 打破数据孤岛:提升业务分析便捷性
- 实现跨数据源关联分析 :3个CK实例合并成一个云器Lakehouse平台,原本需要在三个系统分别查询再手动关联的场景,现在可以直接通过SQL JOIN完成;
- 提升单数据源分析能力 :ae相关的4张表合并成一张表,简化查询逻辑,保持高性能的同时,提升全量数据完整分析能力;
- 消除数据冗余 :ae/fp/main数据完成全量接入云器后,HBase/Spark周期任务针对这部分数据无需再存多份,进一步降低存储成本关键成功要素。
4.4 效率提升10倍:让业务人员成为数据分析师
- 分析效率大幅提升 :业务人员从”提需求 → 等待1天 → 获取数据”变为”直接查询 → 秒级响应 → 即时分析”,分析效率提升10倍以上。
- 平台团队价值转型 :平台团队从疲于应付各类数据提取需求,转向专注平台能力建设和技术创新。
- 数据价值深度挖掘 :数据孤岛打破后,业务人员可以更灵活地进行多维度关联分析,发现更多业务洞察。
4.5 关键成功要素
- 抓住核心矛盾 :深入分析出业务人员无法自助分析、多系统资源隔离、JSON数据查询慢等具体痛点,而非笼统的”系统慢”或”成本高”。
- 找到技术突破点 :使用真实生产数据,通过3个月POC验证,确认云器Lakehouse的JSON自动索引能力能够解决具体问题。
- 渐进式验证 :从ClickHouse/Spark到ES/HBase,每一步都用真实生产数据验证技术可行性。
- 深度产品协同 :与云器团队紧密合作,针对数美场景持续优化,确保技术能力落地。
五、持续演进:从POC到生产,从数据到AI
数美科技与云器的合作始于2024年8月。经过快速的POC验证(8月海外POC,9月国内POC)和分阶段上线,目前ClickHouse和Spark主体任务已切换至云器,并稳定运行9个月以上。
下一步计划:
- ES迁移进行中 :ES业务正在上生产,随后是HBase相关业务,相关业务会逐步全量切换到云器,真正实现一份存储、多场景应用。
- 打通AI训练全流程 :AI模型训练的数据源头都在云器Lakehouse,后续将打通AI训练需要的样例提取/存储/管理等端到端流程,提升AI团队算法及模型训练效率。
- 多云战略推进 :在海外建立统一的大数据平台,支撑全球业务发展。
🎁 新用户专享福利
✅ 1 TB 存储 · 1 CRU时/天计算 · 1 年全托管体验
➤ 即刻访问云器官网领取:https://www.yunqi.tech/product/one-year-package

