作者背景:Apache Parquet/Arrow/ORC PMC member,Iceberg committer,iceberg-cpp 项目发起人和核心维护者。本文整理自作者在 Iceberg Summit 2026 上的主题分享。
Iceberg 生态中”缺失”的 C++ 原生 SDK
云器科技的创立目标是构建一个能够统一批处理、流处理和分析负载的云原生 Lakehouse。我们的核心技术优势在于通用增量计算 :只处理”新增且必要”的数据,从而最大限度地提高资源效率。为了保持生态系统的开放性,我们将 Apache Iceberg 定为默认的表格式。然而,在进行架构选型时,我们遇到了一个关键的技术难题:我们的计算引擎完全由 C++ 驱动,但在当时繁荣的 Iceberg 生态中,却始终缺少一个成熟的原生 C++ SDK。
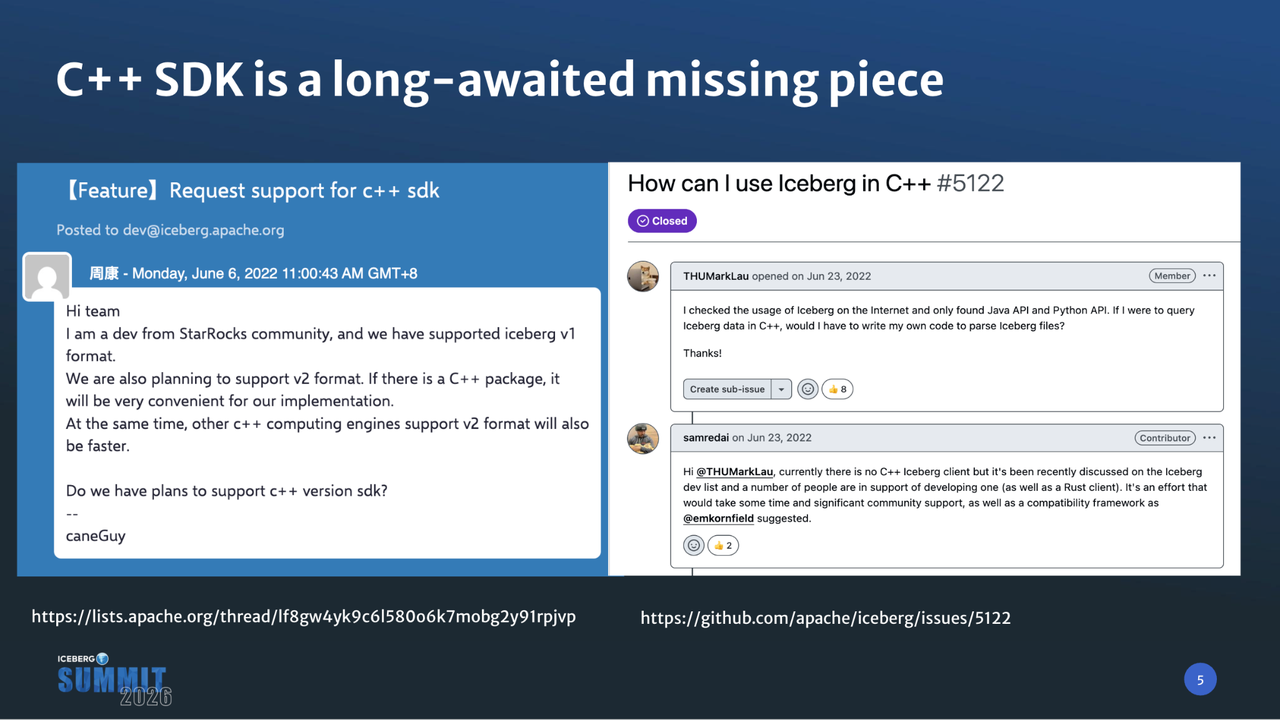
当时,社区内部对 C++ 支持的呼声很高,但由于实现难度大、后续维护负担重,相关进展一直很缓慢。更有意思的是,社区当时的普遍共识是优先投入开发 Rust SDK。然而,对于我们这样深度依赖 C++ 基础设施(包括成熟的 IO 模型、自定义线程池以及现有的 Parquet/压缩库依赖)的高性能引擎来说,简单地采用 Rust 绑定并不是最佳方案。这种做法不仅会引入额外的互操作开销,更关键的是,我们无法充分复用已有的高性能 C++ 组件。
随着 Iceberg 规范(V3/V4)的快速迭代,我们逐渐意识到,仅凭公司力量维护一个内部实现将是一项巨大的持续性投入。更重要的是,我们观察到许多新兴的 C++ 引擎(如 Velox、ClickHouse、DuckDB 等)正面临同样的困境:它们各自重复造轮子,开发着绑定自己引擎的 Iceberg 客户端,导致整个 C++ 生态系统出现碎片化。基于我们在 Apache Arrow 社区积累的丰富经验,以及对构建 Composable Data Stack 的深刻理解,我们坚信:只有将这项基础工作贡献给开源社区,才能真正汇聚行业力量,为所有高性能 C++ 引擎提供一个统一、高可靠、可复用的原生底座。这,正是我们发起 iceberg-cpp 项目并将其推向开源的核心动力。
诞生与使命:打造 Iceberg 标准完全兼容的原生底座
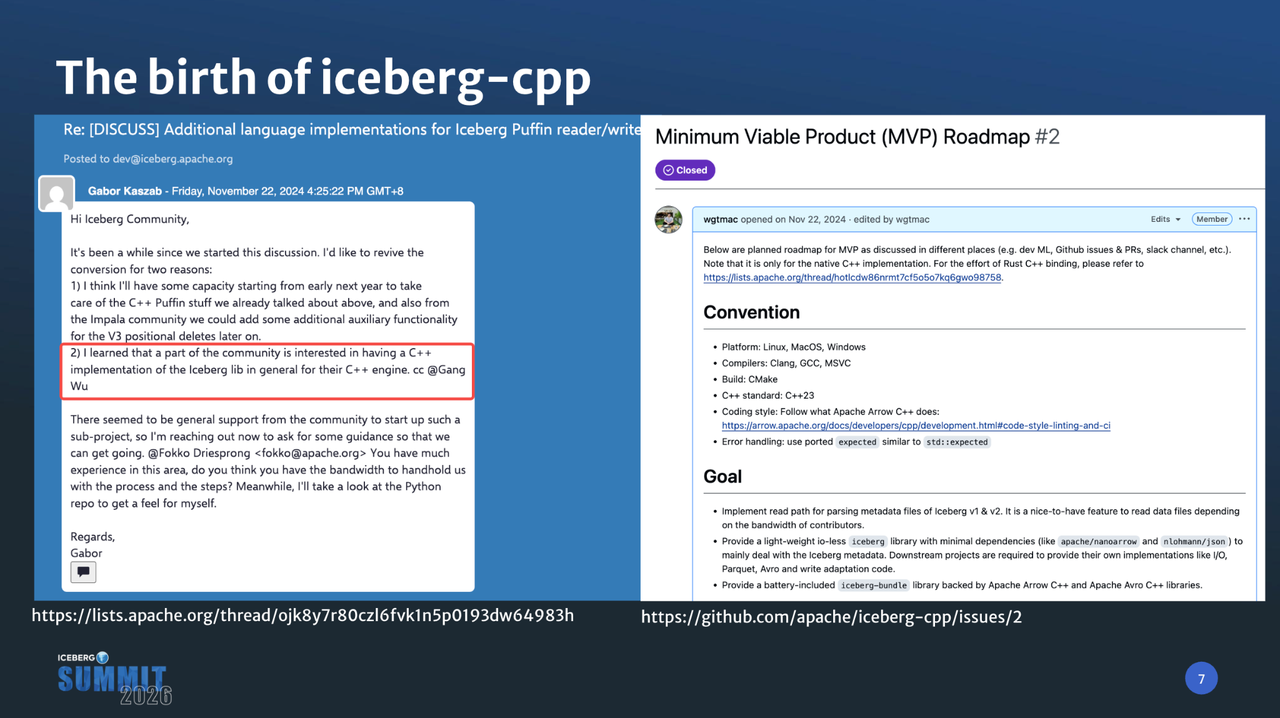
iceberg-cpp 项目的诞生始于社区对 C++ Puffin 实现的讨论。我表达了贡献全新 C++ SDK 的意愿,很快达成了共识。社区核心成员 Fokko 协助创建了项目,并在早期提供了指导。我发起第一个 Issue 收集需求和反馈,最终 iceberg-cpp 项目的轮廓得以确立。我们的使命是为所有 C++ 引擎提供一个共享、高性能的原生底座,其核心设计哲学围绕以下三大目标展开:
- 标准兼容: 我们严格遵守 Iceberg 官方的白皮书规范。更重要的是,对于规范中不清晰或存在歧义的部分,我们以 Java 实现作为隐式规范和”黄金标准”,实现无缝的跨语言迁移和后向兼容性。
- 可插件化: 鉴于不同的引擎拥有各自的 IO 模型、线程池、Catalog 设计和高性能 Parquet 实现等基础设施,我们采用了接口导向设计。通过将 Catalog、FileIO 和文件格式定义为纯接口,极大地简化了引擎的集成难度,方便它们快速插拔并复用自己的高性能组件。
- 开箱即用: 对于不需要使用 Apache Spark 等重量级引擎、只需简单读写数据的用户,我们提供了一个包含完整功能包的解决方案,方便他们快速上手。
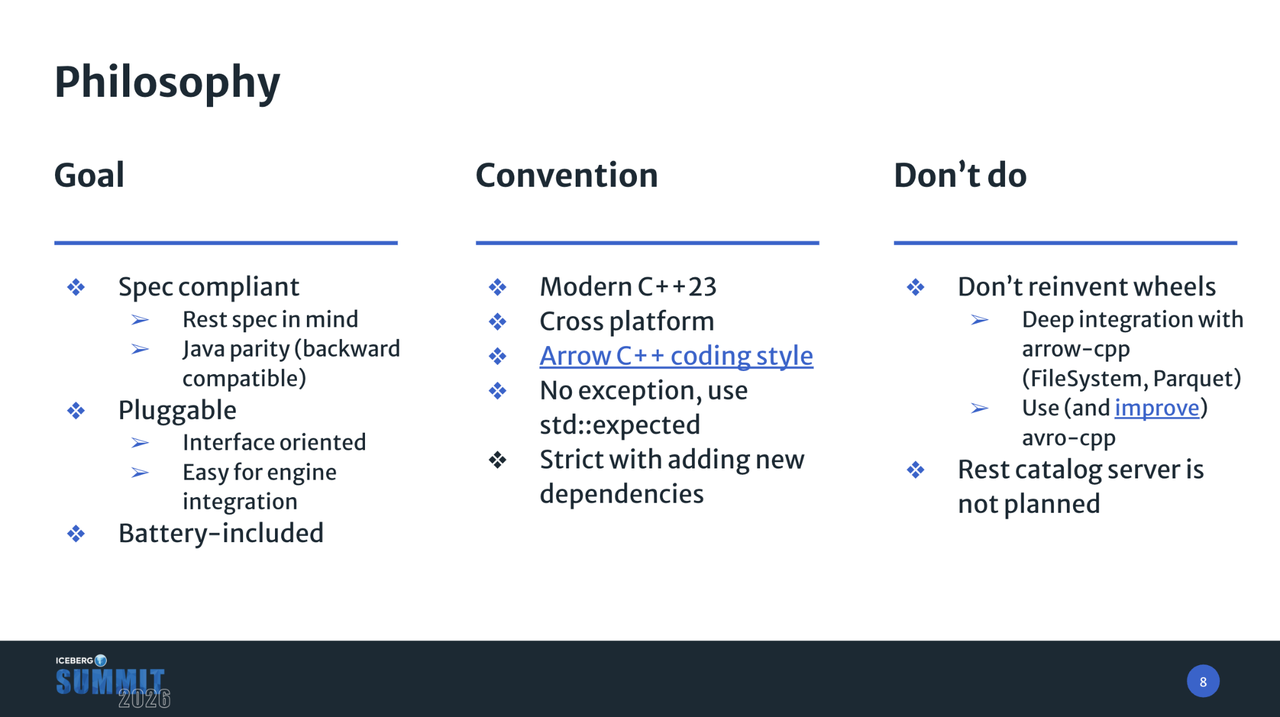
在项目实践中,我们借鉴了 Apache Arrow 的成功经验,制定了严格的技术准则:
- 拥抱现代 C++: 项目底层使用 C++23 标准,充分利用现代语言特性(如 std::expected、Ranges / Views 和 Concepts)来追求极致性能。同时,我们坚持使用 Status 返回码而非 Exception 进行错误处理,这是构建高性能系统的关键准则。
- 不重复造轮子: 我们避免重复开发已有的优秀开源组件。例如,为支持元数据读写,我们深入参与了 Apache Avro 项目,提交了 20 多个 Commit 以增强其 C++ 实现。我们还与 Arrow C++ 深度集成,复用其 FileSystem 和 Parquet 支持。
- 聚焦客户端: 我们明确不计划开发 REST Catalog 服务器,而是专注于构建一个高性能的 C++ 客户端。用户可以自由选择现有的开源 Catalog 服务器(如 Apache Polaris、Apache Gravitino),而 iceberg-cpp 可以作为构建 C++ 原生 Catalog 服务器的优质基石。
技术深挖:分层架构与高效解耦
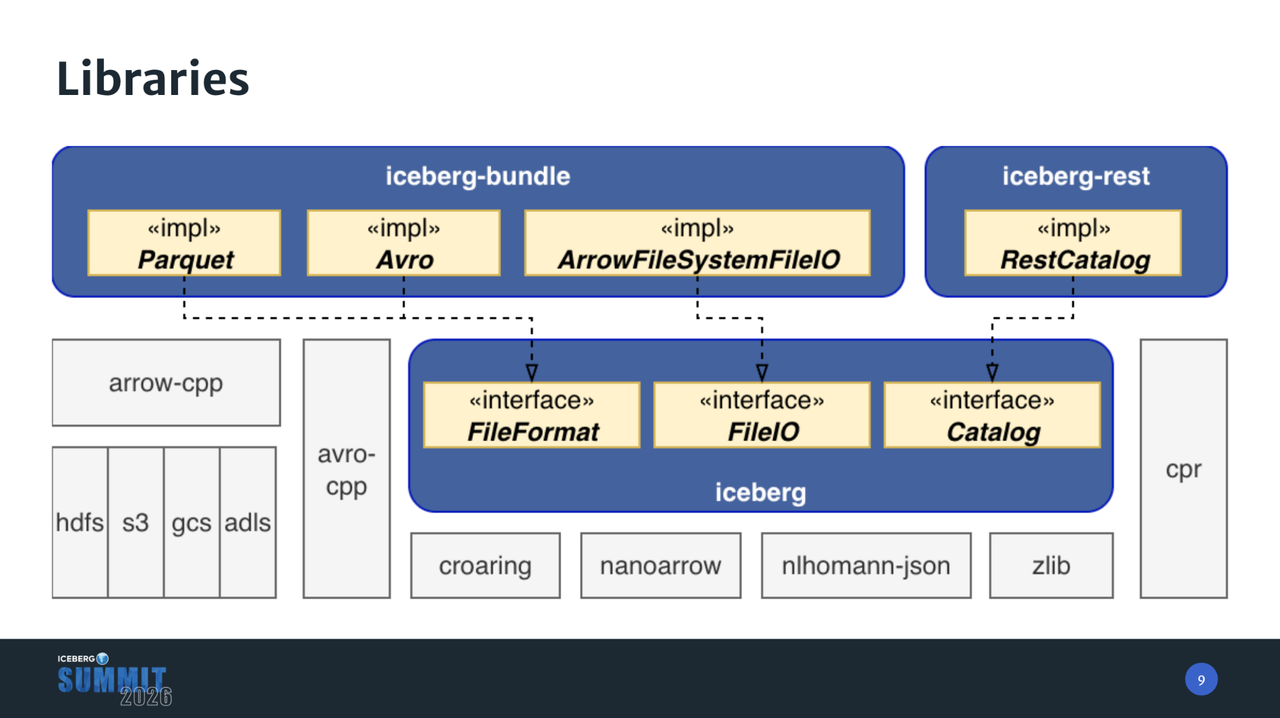
为平衡”轻量级元数据操作”和”功能完备性”的需求,iceberg-cpp 采用了清晰的三层解耦架构。每个库都专注于特定的功能,并拥有明确的依赖边界,旨在满足不同集成场景的需求。
iceberg-cpp 的架构由三个专注于不同功能且边界清晰的库组成:
- iceberg 核心库:这是项目的中心组件,专注于 Iceberg 规范(Table Spec、REST Spec 等)的实现。它采用接口导向设计,仅使用 Catalog、FileIO 和文件格式的接口,不强制绑定复杂的 I/O 逻辑,因此成为高性能引擎进行深度集成的理想基石。其主要依赖包括 ZLIB、nlohmann-json、nanoarrow 和 croaring,以确保极致的轻量级元数据管理。
- iceberg-bundle 库:该库构建在核心库之上,旨在提供”开箱即用”的完整功能包。它深度集成了 Arrow C++ 和 Avro C++,充分利用 Apache Arrow C++ 强大的 FileSystem 抽象层,为用户提供了文件格式支持以及连接云存储(如 S3/HDFS/GCS)的能力。
- iceberg-rest 库:这是一个独立的 REST Catalog 客户端。它使用 CPR 来处理 HTTP 连接和 Catalog 操作,并提供了可插拔的身份认证机制(如 OAuth2),适用于独立进行 Catalog 操作的场景。
互操作性:Arrow C Data 接口与极致插件化

数据交换的效率是衡量 SDK 价值的关键因素。我们选择 Arrow C Data Interface 作为核心数据交换标准。这套基于 C 结构体的接口,是列式数据布局的事实标准,实现了与外部计算引擎间的”零拷贝”数据通信。通过将 Arrow C Data Interface 用作写入器和读取器的数据 API,能够最大限度地提升互操作性,因为许多引擎已原生支持 Arrow 格式。
在具体实现 Arrow C Data Interface 时,为了同时满足对核心库极致轻量和对功能包完备功能的需求,我们采取了以下分层策略:
- 极致轻量(iceberg 核心库): 核心库选择了 nanoarrow,避免了引入额外的复杂依赖,从而最大限度地保持了库的轻量级。
- 功能完备(iceberg-bundle 库): 该库则构建在 arrow-cpp 之上,充分利用其强大的计算算子和丰富的文件系统支持。用户可以根据自身需求,选择最符合的 Arrow 库进行数据读写。
为实现真正的极致插件化,我们对 Catalog、FileIO、Reader 和 Writer 等核心接口广泛应用了注册模式。例如,Reader API 原生支持 Arrow 格式,返回 ArrowSchema 和 ArrowArray 的迭代器。用户只需向注册表注册自己的实现(如自研的 Parquet 读取器或专有文件系统),即可在不修改核心库代码的情况下,无缝接入。默认情况下,iceberg-bundle 库会注册 Parquet 和 Avro 的内置实现。
现状和未来蓝图
0.1.0 基础奠基
- 定义了 Schema、Partition Spec、Snapshots 等核心元数据模型的序列化。
- 实现了基础的表扫描计划(针对 CoW 表,暂不支持删除文件)。
- 实现了 Manifest 读取器和写入器。
- 全面支持 Parquet 和 Avro 文件格式。
0.2.0 能力跃迁
- 新增表元数据更新支持(Schema 演进、Partition Spec 演进和 Snapshot 管理)。
- 核心突破:支持了 V2 Delete 文件(Position/Equality deletes)的扫描计划与过滤。
- 实现了基础的 Append 写支持。
- 新增了基础的 REST Catalog 客户端(iceberg-rest 库)。
0.3.0 近期目标
- 完善表更新操作:覆盖写、更新等。
- 支持增量表扫描计划,这是实现通用增量计算的核心。
- 实现元数据检查表(Metadata Table inspection)。
- 完善数据文件写入器和 MoR V2 表的扫描任务读取器。
- 增强 REST Catalog 客户端的身份认证能力。
未来展望
- 支持 Table Spec V3/V4、View Spec、加密等。
- 支持表维护功能,包括分布式规划。
- 探索应用 C++20/23 的新特性(如 Modules, Coroutines, std::execution)以追求极致性能。
- 新增更多 Catalog 实现和命令行工具(CLI)。
实战应用:从简单读取到复杂引擎集成
案例一:开箱即用
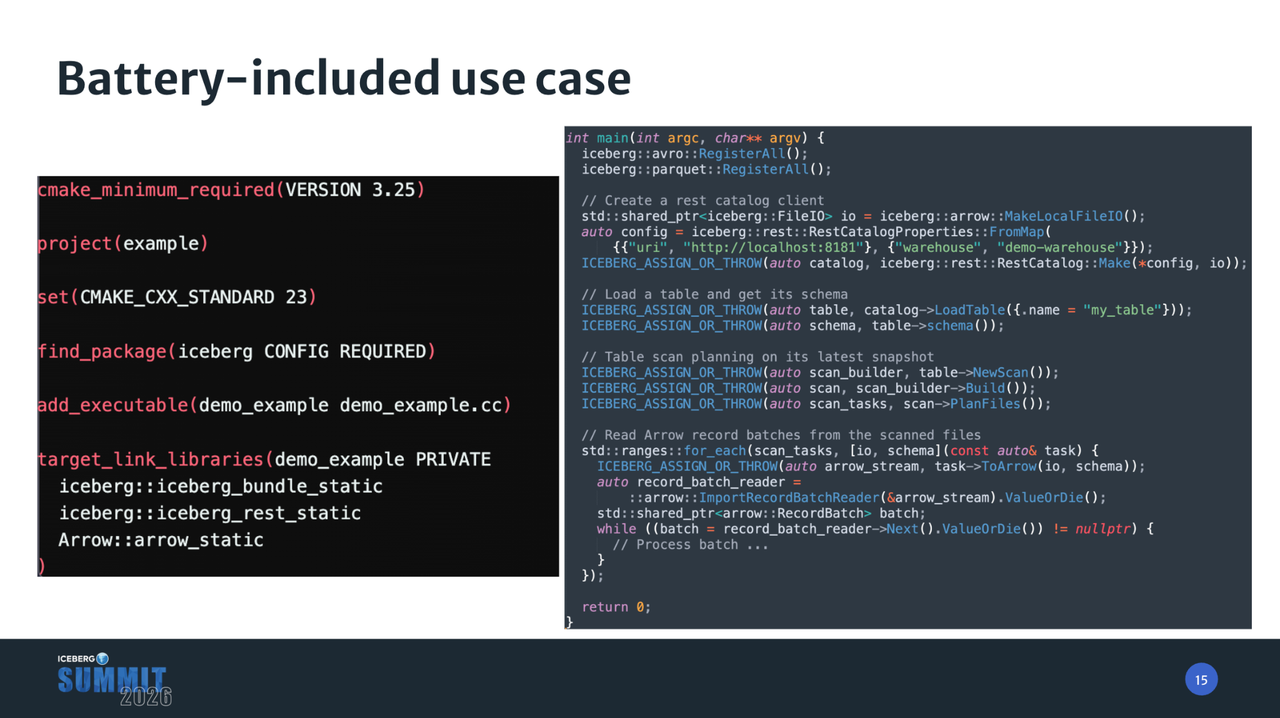
对于那些不需要 Apache Spark 等重量级引擎、仅需简单读写 Iceberg 数据的用户或工具而言,我们提供了”开箱即用”的集成方案。该方案的核心是 libiceberg-bundle 库与 libiceberg-rest 库的组合应用。首先,通过 iceberg-rest 库连接到 REST Catalog 服务器,获取目标表的元数据。随后,利用 iceberg-bundle 库提供的完整功能包,用户可以对表的最新快照执行扫描规划(Scan Planning)。
在数据读取阶段,为了方便用户处理列式数据,该方案演示了如何选择 arrow-cpp 库,将底层的 Arrow C Data Interface 输出转换为 C++ 的 Arrow RecordBatches,从而实现高效、简便的数据 I/O 操作。
案例二:云器科技深度集成
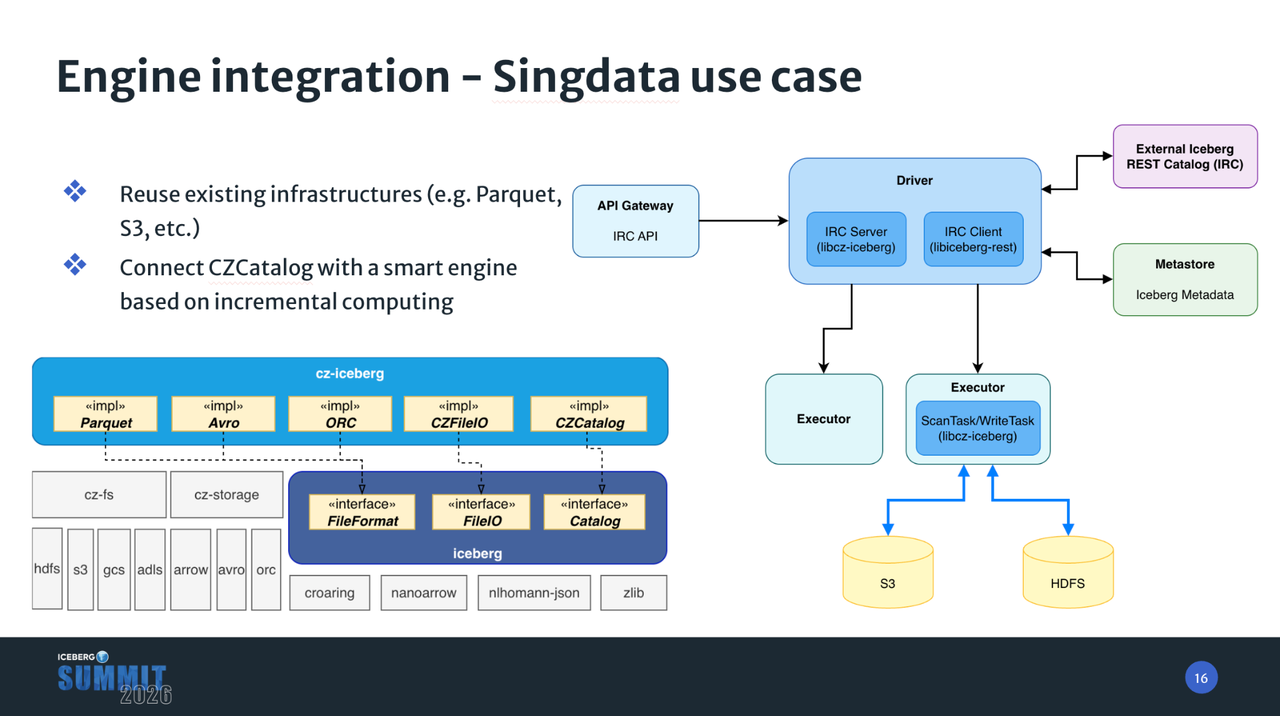
云器科技的 Lakehouse 架构采用了与 Apache Spark 类似的 Driver/Executor 模式。为了最大限度地复用我们已有的高性能基础设施(如自研的 FileSystem 抽象层、Parquet/Avro/ORC 等文件格式支持、以及内部的增量计算 Catalog),我们开发了一个名为 cz-iceberg 的扩展库。这里的 CZ 是 ClickZetta 的简称,这是云器科技 Lakehouse 产品的品牌名称。该 cz-iceberg 库构建在 iceberg-cpp 核心库之上,通过插入我们内部的 FileSystem、文件格式和 Catalog 实现,充当了连接器的角色,从而将我们优化的基础设施无缝接入 Iceberg 生态。
Driver 端负责复杂的跨 Catalog 规划逻辑。它使用 cz-iceberg 连接到我们的内部元数据存储,同时也利用 iceberg-rest 库连接到外部的 Iceberg REST Catalog。其核心职责是执行表扫描规划(Scan Planning)和所有的表元数据更新操作(Table Updates)。Executor 端负责高性能的数据 I/O。它通过调用 iceberg-cpp 库中的 Reader 和 Writer 接口,并借助 cz-iceberg 扩展库,插件化地接入了我们优化的文件系统(如 cz-fs)和文件解析器,以执行 Scan Task 和 Write Task。
值得一提的是,我们的 ScanTask 序列化设计实现了与 Java 实现的完全兼容。这意味着对于 Impala 或 Doris 等采用 Java 前端进行元数据规划的引擎来说,可以轻松搭建起一个”Java 负责 Driver 端规划,C++ 负责 Executor 端高性能数据 I/O”的混合架构。
愿景:共建 C++ 生态
尽管我们已经取得了阶段性的突破,但前行的道路上依然充满挑战。如何在 Apache Iceberg 规范飞速演进的浪潮中保持领先,不仅是功能实现上的赛跑,更是对兼容性保障能力的极致考验。欢迎订阅我们的邮件列表或在 GitHub 上提交您的贡献。让我们携手并进,在 C++ 生态中彻底释放 Iceberg 的原生动力,共同定义高性能 Lakehouse 的未来!
🎁 新用户专享福利
✅ 1 TB 存储 · 1 CRU时/天计算 · 1 年全托管体验
➤ 即刻访问云器官网领取:https://www.yunqi.tech/product/one-year-package

