导言
用户画像是大数据应用的重要场景。通过多维度数据建模,构建用户行为并转化为标签,建立完整的数字身份图谱。通过系统分析大量用户行为数据,给每个用户打上多样的标签。这些标签包括人口特征和兴趣爱好等多方面信息。用户画像帮助企业做个性化推荐和精准营销,已经成为企业数字化运营的基础工具。
在移动互联网环境中,用户数量和标签种类增长非常快。如何高效存储和实时查询数千亿级的标签数据成为了技术难题。传统方法常常依赖外部供应商,按照"数据对接→数据建模→ID映射→标签加工→标签圈选"的流程进行。但这种方法容易造成系统重复建设,形成新的数据孤岛。
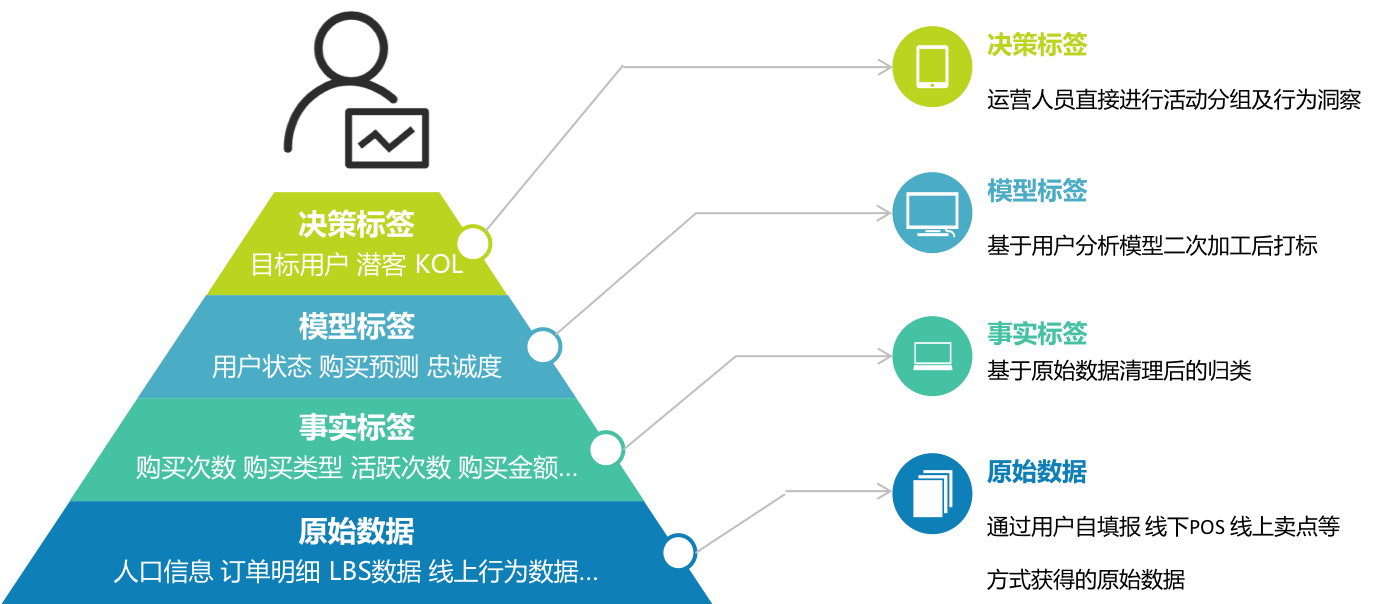
(图:用户标签体系)
许多企业考虑购买CDP(客户数据平台)等专门系统来实现用户数据分析。这些系统虽然功能全面,但往往需要大量投资,并且会与企业现有数据仓库形成割裂。数据需要重复采集、存储和处理,不仅增加了成本,还可能导致数据口径不一致。更重要的是,这种做法无法充分利用企业已经建立的数据资产。
本文提出了不同的思路:不需要购买额外的CDP系统,只利用现有数据仓库架构就能实现全面的用户数据分析。
业务场景
基于很多企业已经建立了完整的数据仓库。且企业的业务部门希望通过"用户画像"进行精细化运营。我们要解决的问题是:如何利用企业现有数据和数据平台能力,构建有效的"用户画像"服务。这正是本文主要讨论的内容。
用户画像的四个关键要素
要建立完整的用户画像系统,我们需要实现四个核心功能:
- 全面数据接入 :收集和整合来自各个业务系统和渠道的用户数据
- 统一用户ID :将同一用户在不同系统中的多个身份关联起来,形成统一视图
- 用户标签体系 :根据用户特征和行为创建多维度标签
- 用户圈选能力 :基于标签组合条件,快速筛选出目标用户群体
这四个要素缺一不可,它们共同构成了用户画像系统的基础架构。接下来,我们将介绍如何利用现有数据平台能力高效实现这些功能。
构建用户画像的挑战与问题
企业在构建用户画像系统时面临一个根本问题:如何避免创建新的数据孤岛?企业应该维护一套统一的数据仓库和指标体系,而不是购买更多独立的数据平台系统。
传统方法使用ETL和SQL构建用户画像时面临多重困难。首先是数据接入复杂。数据分散在各种系统中,包括MySQL、Oracle等关系型数据库,MongoDB等NoSQL数据库,各种SaaS服务和企业软件。这些数据形式多样,有结构化和半结构化数据。企业需要为每种数据源单独开发连接器并进行技术调试,这既费时又容易出错。
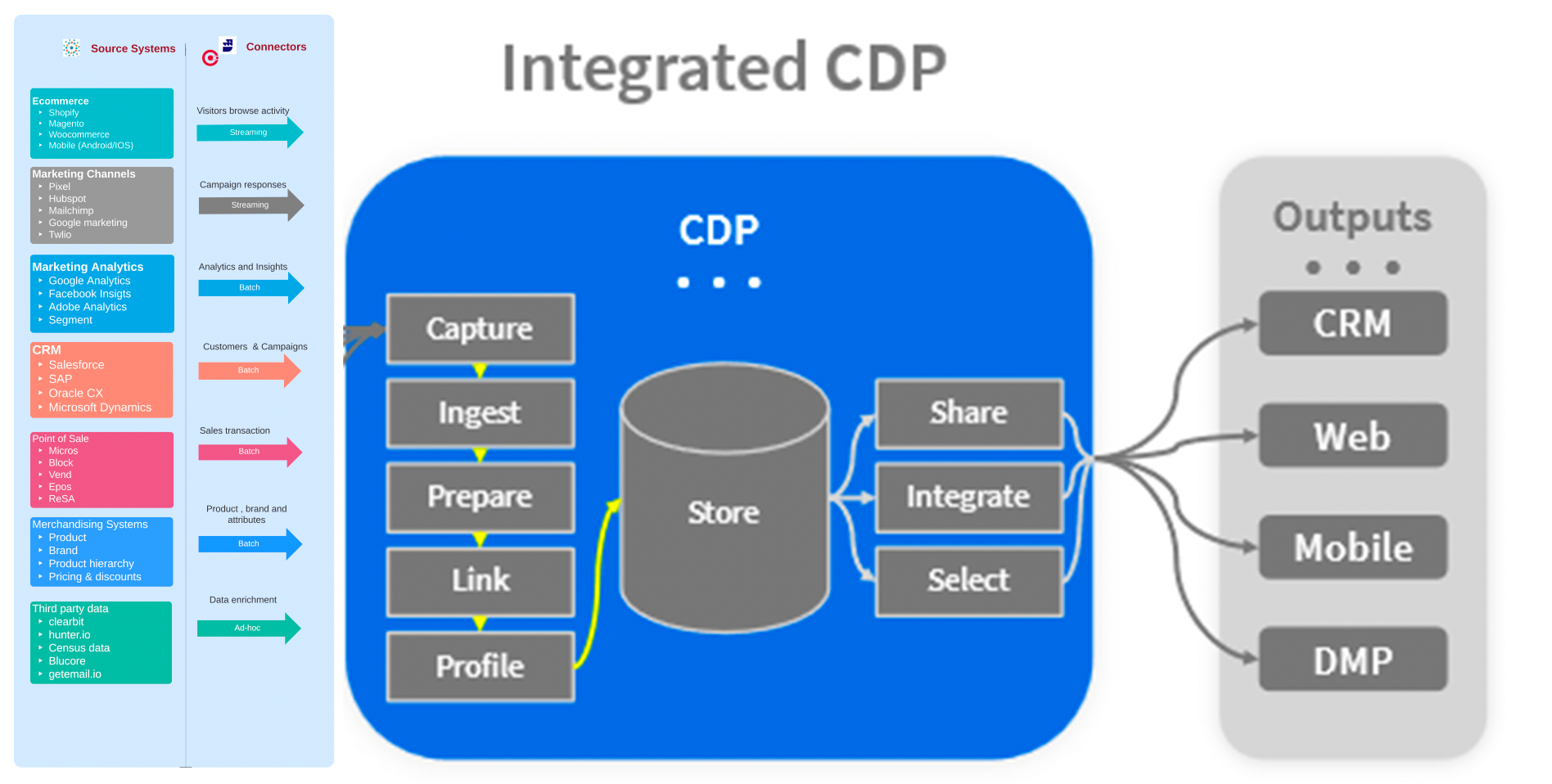
(图:多种数据源的对接)
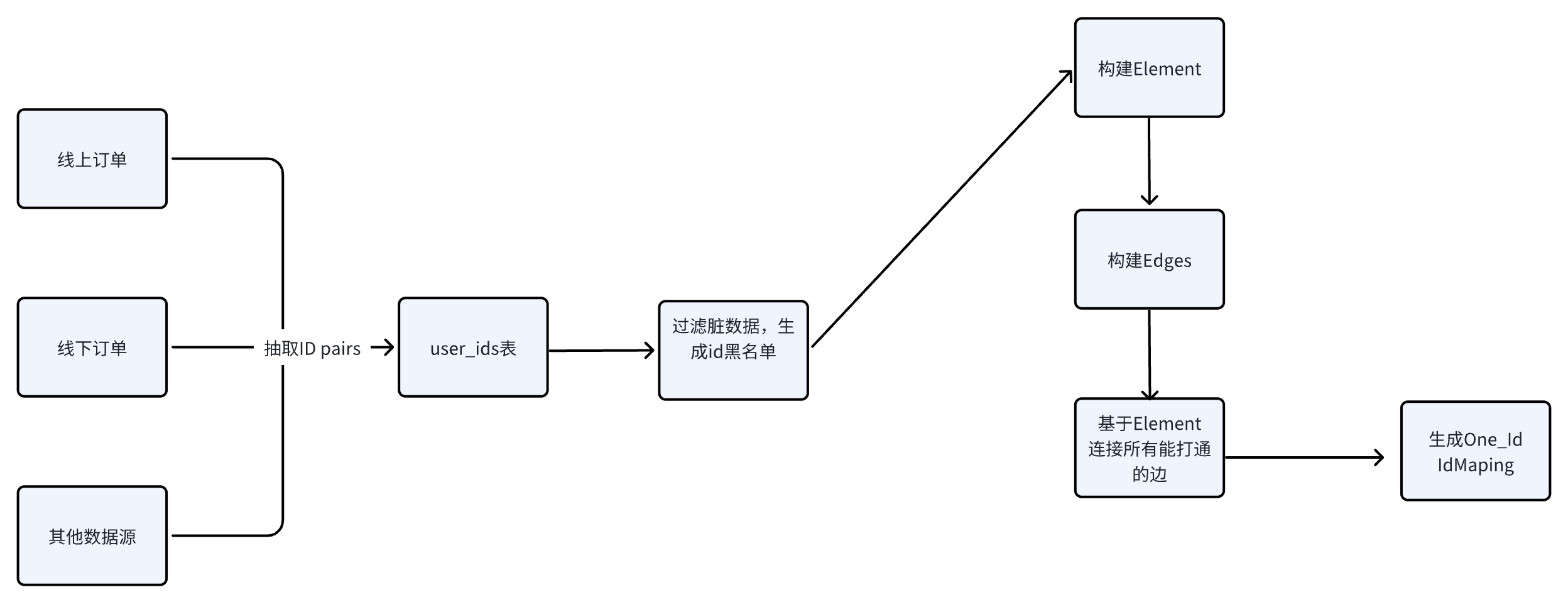
其次是用户ID统一的难题。用户在不同系统中可能有设备ID、手机号、邮箱、社交账号等多个身份。这些ID之间关系复杂,需要用图算法识别关联,计算量大。不同系统的数据标准也不一致,有些系统的数据质量较差,存在大量错误和重复。ID映射表可能包含数十亿条记录,传统平台难以支持高并发查询。
系统1: 统一用户视图:
ID: 1001 MasterID: M001
Name: "Rebecca Smith" Name: "Rebecca Smith"
Source: "CRM" ----> Sources: ["CRM", "ERP", "Purchases"]
IDs: {CRM: 1001, ERP: E123, Purchase: P456}
系统2:
ID: E123
Name: "R. Smith" ---->
Source: "ERP"
系统3:
ID: P456
Name: "Rebecca S." ---->
Source: "Purchases"
传统标签存储技术也有局限性。常用的位图技术虽然查询速度快,但只能存储是/否类型的数据,无法灵活扩展。企业通常需要提前规划标签结构,难以应对业务变化。
数据更新和用户圈选的效率也是大问题。标签计算通常采用次日更新模式,不够及时。如果要实时更新,就必须使用Flink等工具,但计算成本高。用户圈选需要复杂的逻辑运算,计算负担重,速度慢,无法支持实时业务分析。
最后,资源利用效率低也是严重问题。用户画像系统有两个典型峰值时段:大促期间和工作日高峰时段。为应对这些峰值,系统需要预留足够资源,导致至少一半资源长期闲置,造成浪费。
面对这些挑战,企业需要思考:如何利用已有数据和平台能力,构建高效的用户画像服务,而不引入额外系统?这正是我们接下来要解决的关键问题。
解决方案
基于云器Lakehouse构建用户画像和行为分析架构
依托Lakehouse统一数据架构原生构建用户画像与行为分析服务,实现数据资产复用率提升300%,通过标准化建模流程降低40%开发成本,同时支持实时多维洞察,深度释放企业数据资产价值。
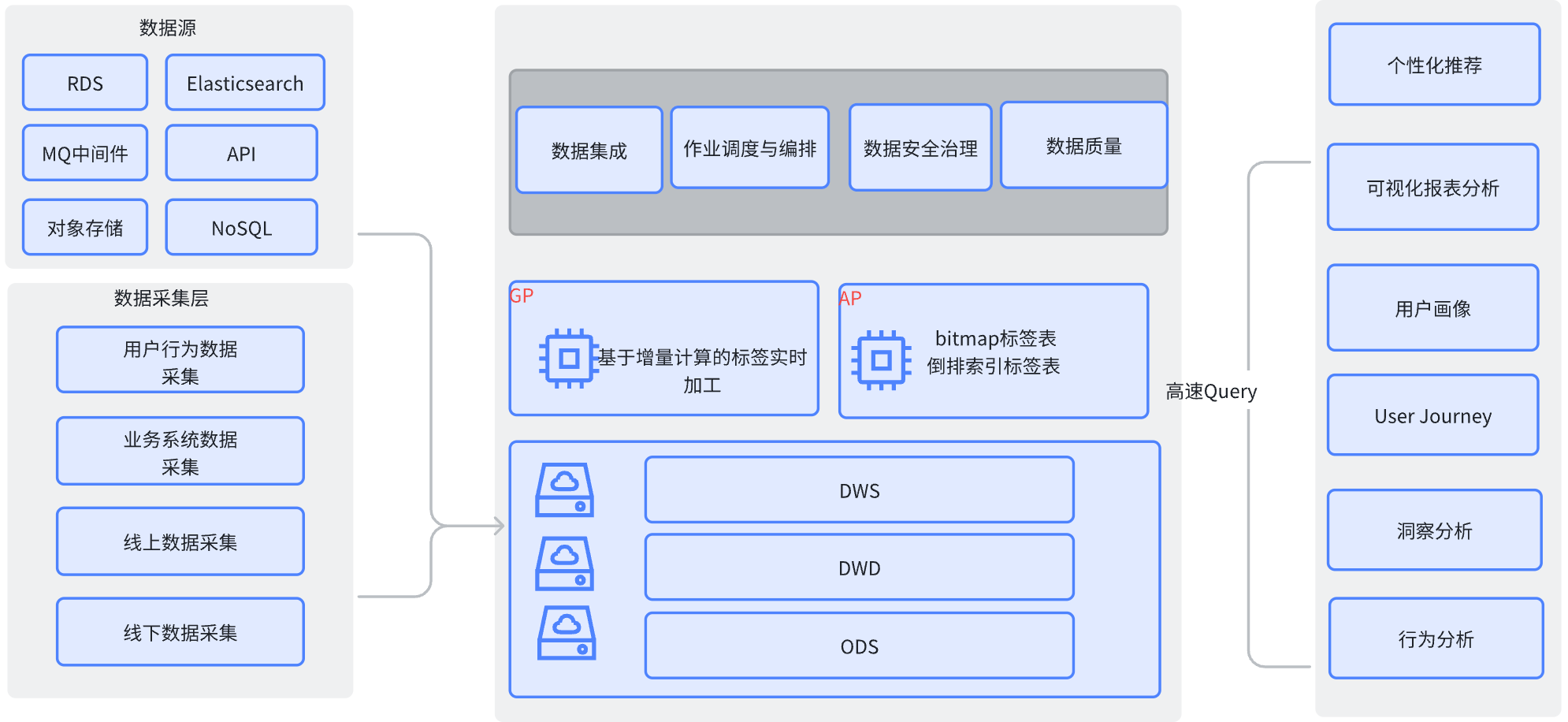
基于云器Lakehouse构建用户画像和行为分析
1. 复用已有数据平台的多源异构数据源的数据接入能力
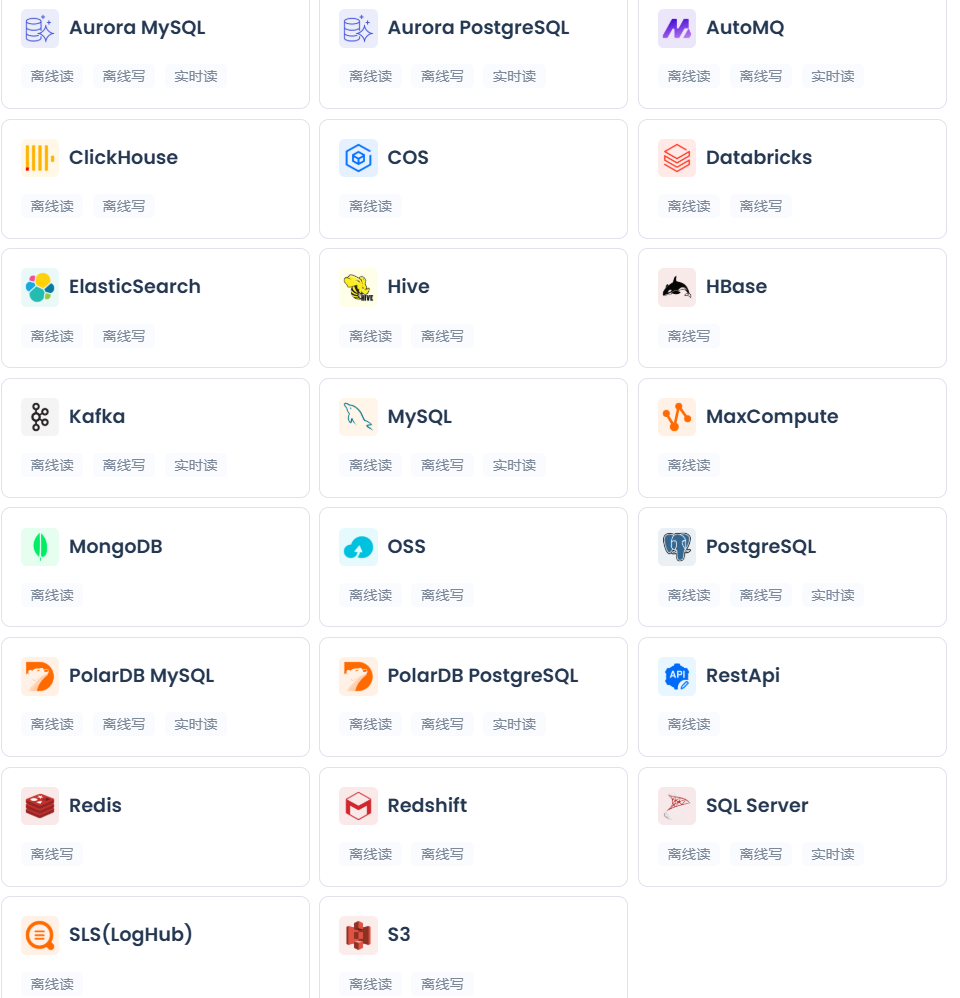
云器Lakehouse预集成50余种异构数据源连接器,涵盖关系型数据库、文档数据库、键值存储、消息中间件及对象存储等主流数据系统,通过可视化操作界面实现多源异构数据的离线批量采集与实时流式同步。

2. 为IDMapping提供timetravel的能力
OneID的构建和IDMapping的管理和历史数据对比分析是OneID服务中痛点和难点,云器Lakehouse在提供了Merge into和复杂的关联计算能力之外,同样提供了timetravel的能力可以回溯到历史的任一时间点,和历史OneID的版本进行对比分析。
3. 基于增量计算实现标签的实时加工
在云器Lakehouse上我们提供了增量计算引擎,可以低成本的替代Filnk的实现方案,在计算成本和画像分析的时效性上都取得了良好的收益。与此同时云器Lakehouse对于Json的存储和解析做了深度的优化,可以让用户标签可以在不变更表结构下无限扩展。
4. 提供bitmap和倒排索引的分群筛选能力
传统的的标签存储和标签计算的技术方案大家推荐都是基于bitmap,云器已经实现了对bitmap的内置支持,bitmap作为标签存储和筛选的虽然计算性能高,但是bitmap仅支持布尔型标签,无法存储数值型标签(如消费金额区间),云器Lakehouse同时提供了倒排索引的能力,可以在解决bitmap短板的情况下,同样提供秒级的的标签筛选能力。
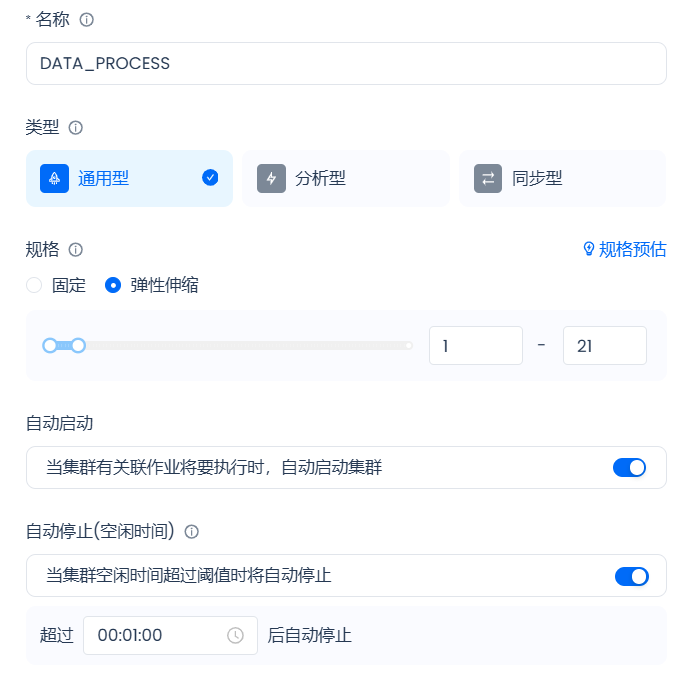
5. 充分利用云器Lakehouse极致弹性能力
在标签计算和分群计算场景这种典型的数据加工的场景,Lakehouse可以实现计算资源按照计算负载要求的垂直的弹性伸缩。在大促场景下随着数据峰值的到来,云器Lakehouse会基于真是的计算需求量提升计算资源以确保数据在业务需要的时间内加工出来,在大促过后数据量下降,计算需求量下降,云器回到到日常所需要的计算资源。
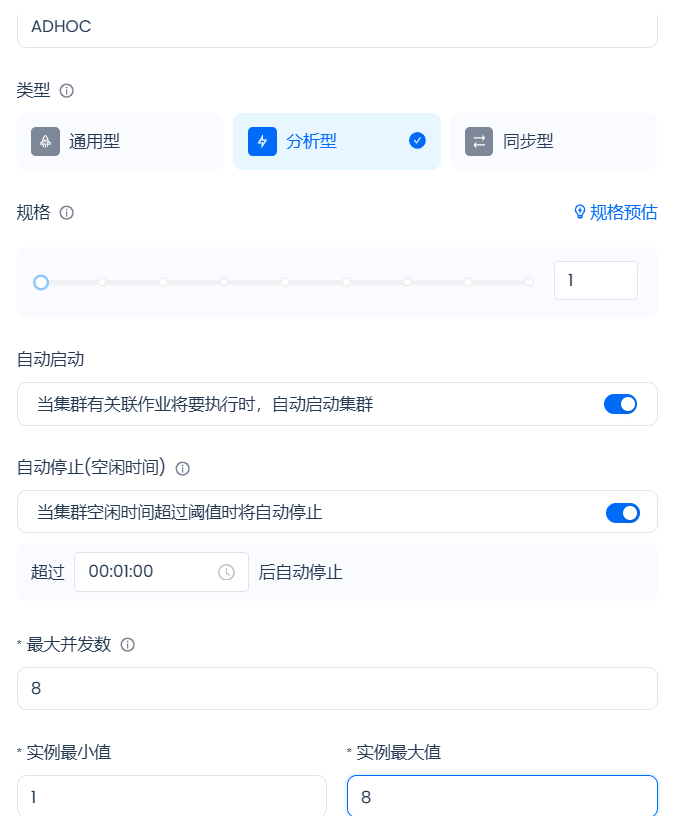
在人群画像和个体画像分析的这种Adhoc的计算场景下,Lakehouse提供基于用户并发请求量实现复制的水平弹性扩展能力。随着工作时间日常计算峰值的到来,云器lakehouse会基于用户的实际并发需求对分析类集群进行复制扩容,当工作时间结束,用户的实际并发需求下降,云器Lakehouse会对分析类集群进行缩容。
客户价值与收益
云器Lakehouse的解决方案为企业带来两方面核心价值:
数据资产价值最大化
基于企业主数据仓库构建用户画像分析体系,充分利用现有数据基础设施,包括数据平台、存储系统和可视化工具。这种方法有几个明显优势:
- 避免创建新的数据孤岛
- 实现数据口径统一,确保各系统间数据一致性
- 支持跨域数据分析,例如:
- 用户画像与财务数据结合,分析用户转化效率
- 用户画像与人力资源数据结合,评估员工投入产出比
- 用户画像与供应链数据结合,优化库存预测与产品规划
通过一次存储、多处使用的方式,企业可以全面挖掘数据的价值,支持更深入的业务分析。
技术性能与成本优势
云器Lakehouse平台在性能和成本方面具有显著优势:
- 数据处理性能比传统Spark快10倍,大幅缩短数据加工时间。
- 实时分析性能比ClickHouse提升30%,支持更快的业务决策。
- 基于增量计算的实时处理成本比Flink低10-1000倍,极大降低运营成本。
这些技术优势共同确保用户画像系统能够以低成本实现近实时数据加工,满足业务对实时性的要求,同时显著降低企业的总体拥有成本。
🎁 限时体验福利
✅ 新用户赠200元体验代金券
✅ 免费领取《云器Lakehouse技术白皮书》
➤ 即刻通过下方网址/扫描二维码体验:
