2024年巴黎奥运会作为第33届夏季奥林匹克运动会,不仅在体育竞技层面吸引了全球的目光,而且在数据分析方面也呈现出许多有趣和值得关注的话题。在Kaggle上,也找到了本届奥运会的完整数据集。
Kaggle数据集地址:https://www.kaggle.com/datasets/sajkazmi/paris-olympics-2024-games-dataset-updated-daily 。 记得给SYED SAJEEL HAIDER在kaggle点个upvote,据说这样Kaggle就可以给他发个金牌!
该数据集包含的有关 2024 年巴黎夏季奥运会的所有内容,在11个csv文件里包括了场地、团队、赛程、奖牌、奖牌获得者、赛事、团队、运动员、教练等方面的数据。

其中results目录里包含了45个项目的结果数据。
❓问题引入:如何以懒人的方式把这些数据加载进云器Lakehouse进行分析呢?去看看这里会有哪些有趣的数据发现?
懒人的方式:不想写建表的DDL语句,何况是要写12个表的DDL语句。那么能想到的最简单的办法是什么?
不想动手,那就要动动脑了。回顾一下,在玩US Funds dataset from Yahoo Finance数据的时候,用过的两种方式都是要写好建表DDL语句的。必须要想到新的办法,那就是用云器Zettapark来完成这个懒人任务。
✅Zettapark 是用于处理云器Lakehouse 数据的 Python 库。它提供了一个高级的 Python API,用于在云器Lakehouse 中执行 SQL 查询、操作数据和处理结果。Zettapark 使得在 Python 中使用云器Lakehouse 变得更加简单和高效。你可以使用 Zettapark 执行 SQL 查询、操作数据和处理结果,就像在 Python 中使用 pandas 一样。
下载数据到本地
从Kaggle数据集地址:https://www.kaggle.com/datasets/sajkazmi/paris-olympics-2024-games-dataset-updated-daily下载数据到本地,放在data目录下。
安装云器Zettapark
创建Zettapark会话
使用Zettapark的第一步是与ClickZetta Lakehouse建立会话。
懒人捷径:通过Zettapark的save_as_table方法一步实现目标表结构创建和数据导入
检查csv文件,进行分类处理,其中需要将results目录下的各类比赛项目的数据进行并表,增加一列sport用来代表比赛项目,就用文件名前缀即可。

代码如下:
在云器Lakehouse里查看zettapark save_as_table的结果
可以看到,刚才下载下来的csv文件里的数据,通过云器zettapark的save_as_table已经全部写进云器Lakehouse的表里了。这避免了要手写12张目标表的的DDL语句,大幅成就了懒人,并且效率极高,特别适合在大数据平台上玩小数据,省去了文件(比如csv文件)很多的情况下,文件数据进入云器Lakehouse的麻烦。

通过DataGPT分析数据
基于2024巴黎奥运会的数据集,我们可以进行多种有趣的分析,比如:
-
奖牌统计: 分析各国获得的金牌、银牌和铜牌数量,以及总奖牌数,从而了解各国在奥运会上的表现。
-
运动员表现: 研究不同运动员的成绩,包括他们的个人最好成绩、在本届奥运会上的表现以及与其他运动员的比较。
-
项目分析: 分析哪些项目最受欢迎或产生了最多的奖牌,以及哪些项目的竞争最为激烈。
-
时间趋势: 如果数据集包含历届奥运会的数据,可以分析奖牌分布随时间的变化趋势。
-
年龄和性别分布: 分析参赛运动员的年龄和性别分布,了解不同年龄段和性别在不同项目中的表现。
接下来我们就用云器Lakehouse的DataGPT来分析刚才通过zettapark save_as_table加载进来的数据。
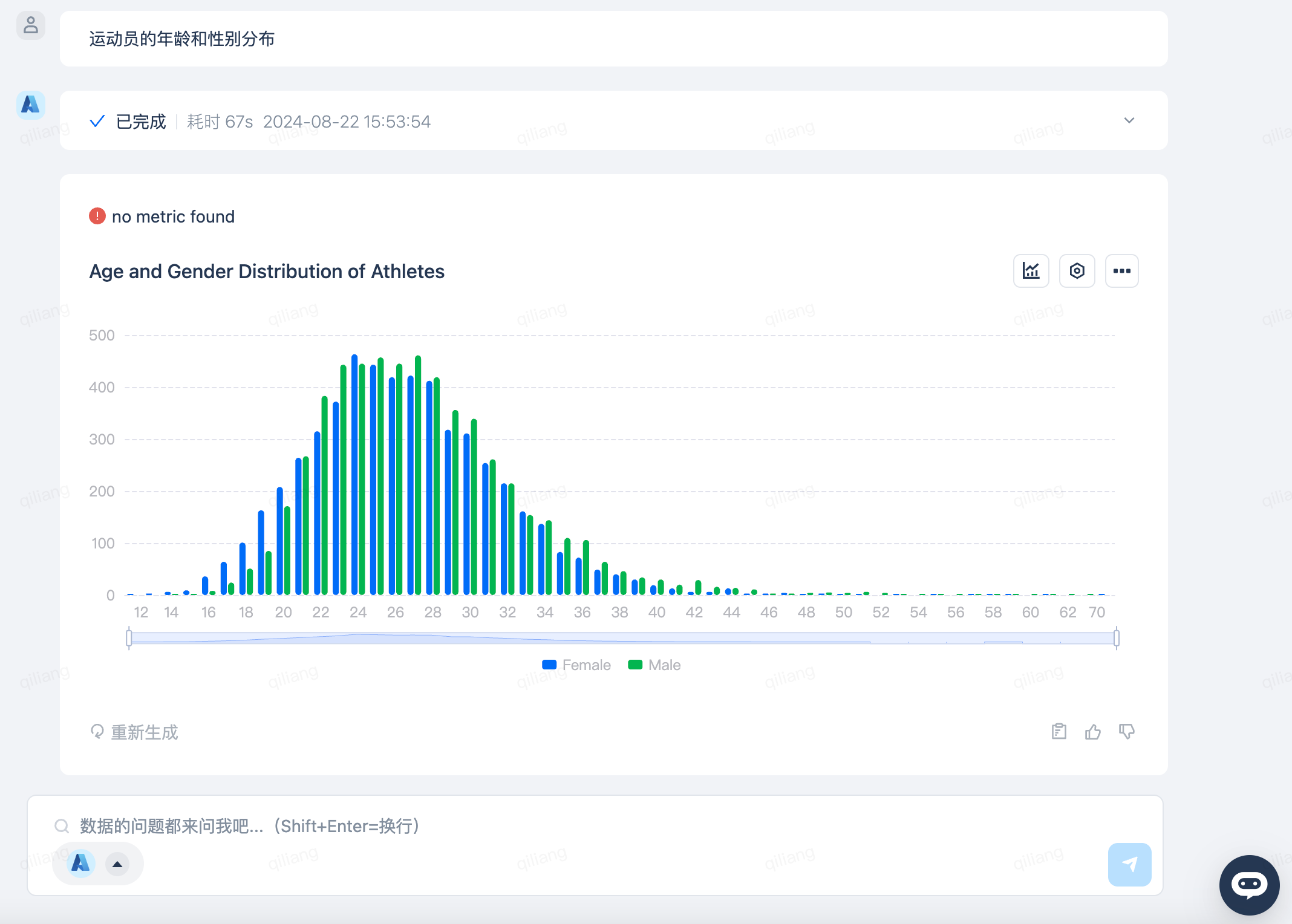
参赛运动员的年龄和性别分布
只需要向DataGPT提问“运动员的年龄和性别分布”,DataGPT就会生成如下的回答。从最幼者12岁到最长者70岁,生命不息,运动不止,满屏的奥运精神,此致敬礼!
在美好的青春岁月里做人生值得骄傲的事情,向青春的光彩致敬!
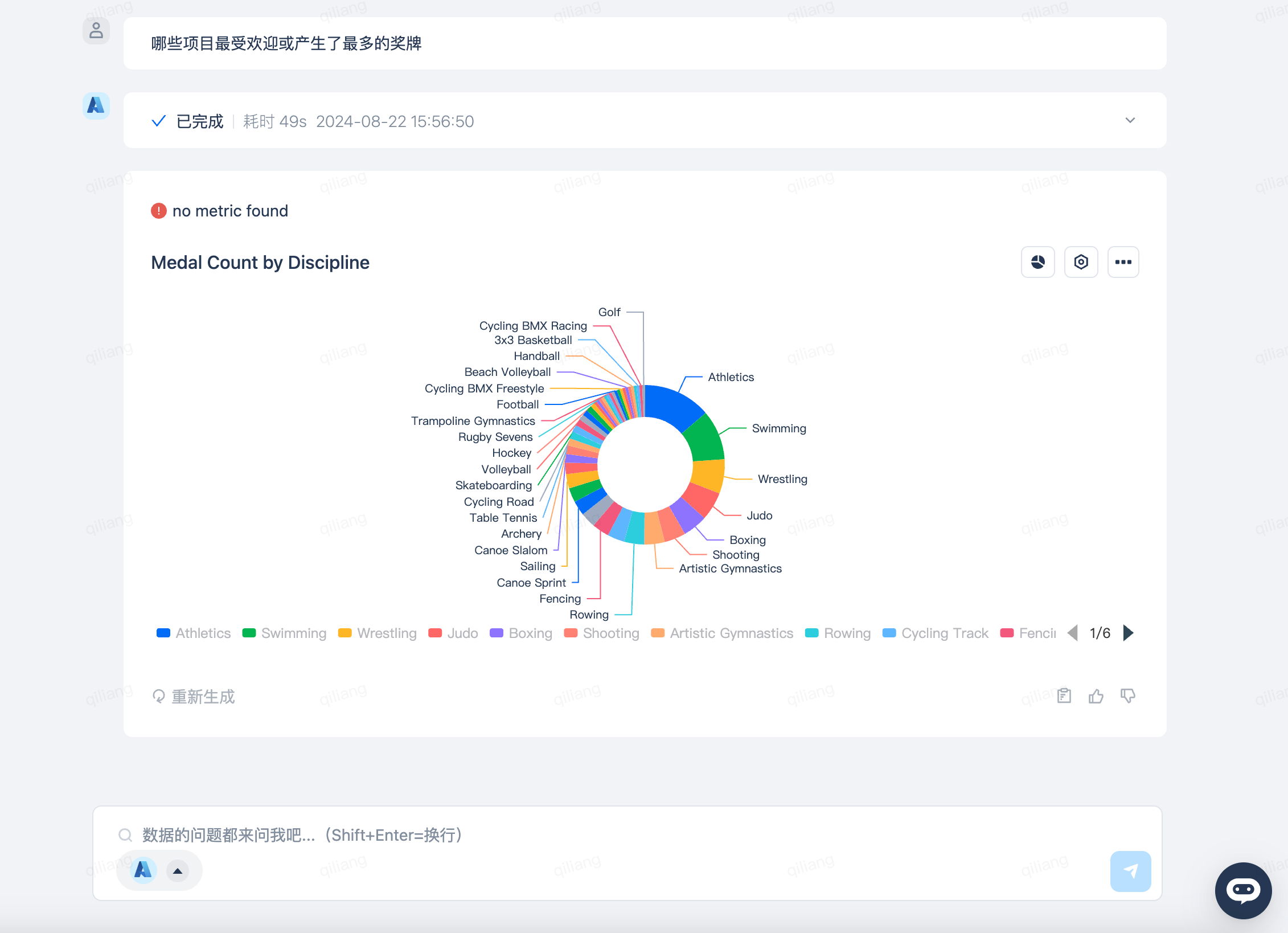
哪些项目最受欢迎或产生了最多的奖牌
只需要向DataGPT提问“哪些项目最受欢迎或产生了最多的奖牌”,DataGPT就会生成如下的回答。你喜欢的项目是哪一个?
每个国家的教练数
东道主就是东道主,教练数上是杠杠的Top1!

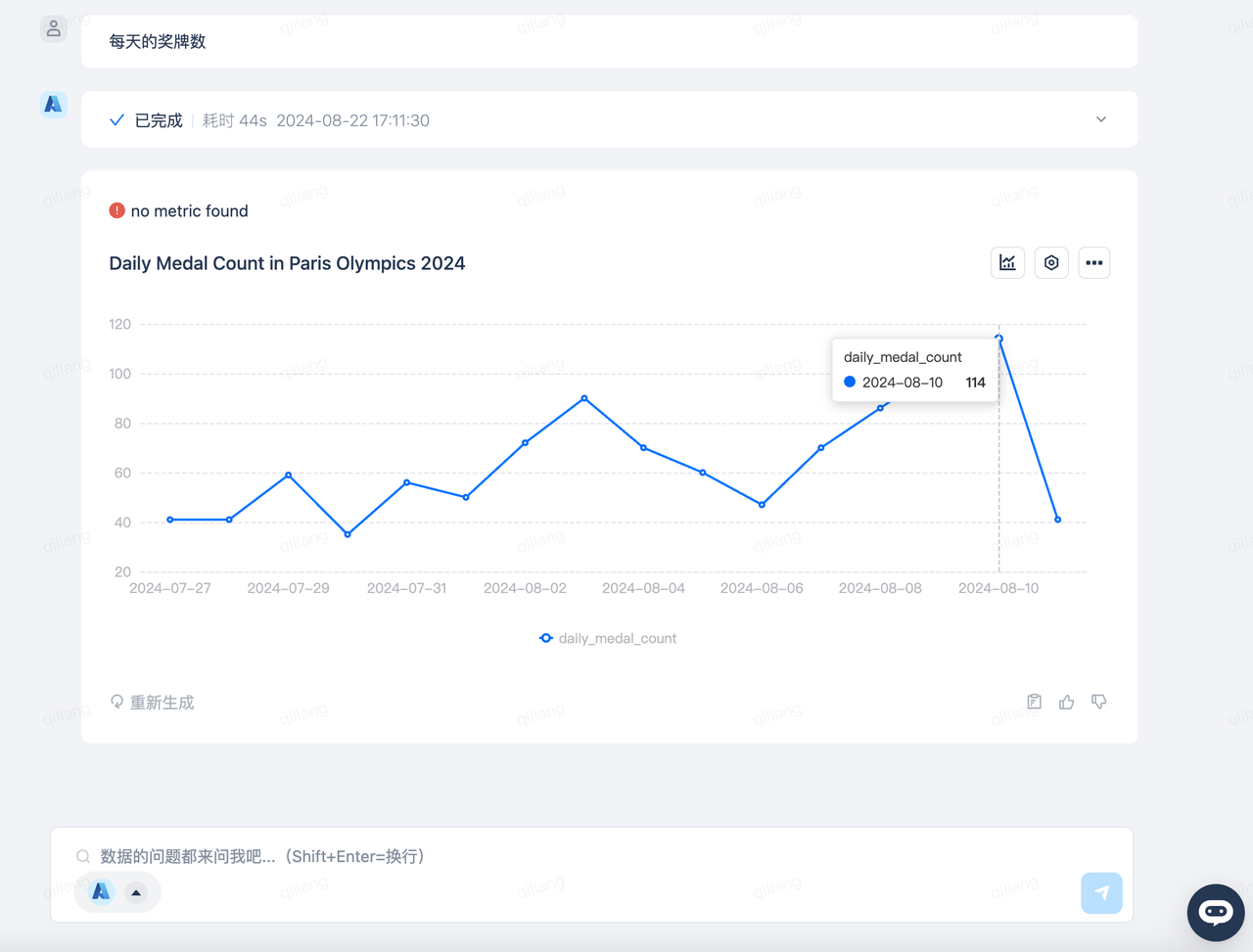
每天奖牌数
原来接近尾声的8月10日是产生奖牌数最多的一天,看来刚开始少点也不用着急哦!
总结
在云器Lakehouse上玩数据,总觉得数据是非大不可,否则就是杀鸡焉用宰牛刀了。本文尝试了Kagge上2024巴黎奥运会小数据集的场景,本方案省去了小数据集里对多个文件创建目标表建表的繁琐任务,从而大幅扫清了数据工程方面的麻烦事。通过DataGPT直接以问答的方式分析数据,从而可以使得更多非技术人员玩转数据,喜欢上数据分析,帮助企业数据文化走向大众化。
你还有哪些感兴趣的数据问题?快来用云器Lakehouse耍起来吧!
