导读
在数字化浪潮席卷汽车行业的当下,车联网数据平台正在经历一场深刻的架构变革。本文基于 云器科技资深大数据架构师刘俊的实战分享,深入剖析车联网数据平台在建设过程中遇到的典型困境,并通过长安汽车、长城汽车、安凯汽车三个真实案例,展现架构“去繁就简”的演进路径。这不仅是一次技术优化,更是一场从成本中心向价值引擎的转型实践。
车联网数据的”表”与”里”:不只是量大那么简单
当提到车联网数据平台的核心挑战时,很多人的第一反应是”数据量大”。这个判断并非没有道理——一辆智能网联汽车每天产生的数据量可以达到1-2TB,头部车企拥有数百万台车在路上奔跑,每天的数据增量轻松达到数十TB甚至EB级。这样的数据规模,确实让许多通用大数据架构捉襟见肘,问题频发。
但在刘俊看来,数据量大只是表象。车联网数据真正的技术挑战,来自于四个更本质的特性。

首先是高并发的写入压力。数百万车辆同时在线,按照表级采集频率(从百毫秒级到秒级不等),TPS(每秒事务处理量)动辄达到千万级。这对数据入湖能力是一个巨大的考验,就像在高速公路的收费站,必须确保所有车辆都能顺畅通过,而不能造成拥堵。
其次是极低的数据价值密度。车辆在路上正常行驶、电池正常充电、系统正常运行,这些”正常数据”占据了总体数据量的99%以上。真正有价值的往往是那些异常数据——可能是突然的电池温度异常,可能是驾驶行为的突变,而这些异常数据可能只占总量的千分之一甚至万分之一。但问题的关键在于,企业不能只存储异常数据,就像大模型需要上下文一样,数据分析同样需要完整的背景信息才能做出准确判断。
第三个挑战是极致的时效要求。车辆的远程诊断、预警推送、智能驾驶决策,都需要分钟级甚至秒级的数据响应能力。如果数据链路还停留在传统的”T+1”模式(今天的数据明天才能看到),那么许多实时业务场景根本无法运转。想象一下,当车辆电池出现异常时,如果系统要等到第二天才能发现并推送预警,这样的响应速度显然无法满足安全需求。
第四个特性是巨大的流量波动。早晚高峰、节假日出行高峰与平峰时段相比,数据流量波动可以达到5-10倍甚至更高。这意味着如果按照峰值配置资源,那么在低峰期将有大量计算资源闲置;而如果按照平均值配置,则高峰期系统可能直接崩溃。
这四个特性交织在一起,构成了车联网数据平台独特而严峻的技术挑战。许多车企在平台建设初期都做了充分的调研和论证,研究了成本、性能以及未来的扩展性。但随着车辆保有量增长和业务需求的复杂化,原本精心设计的架构开始”起烟囱”——每来一个新场景,就得新建一条数据链路;每建一条新链路,又要引入新的组件。数据平台逐渐从驱动创新的引擎,变成了一个不断吞噬资源的成本中心,技术团队也从架构师变成了救火队员。
三大典型问题:从理性选型到复杂度爆炸
刘俊在过去四年服务多家头部车企的过程中,反复遇到三个典型问题。这些问题并非某一家企业的个案,而是行业通病。
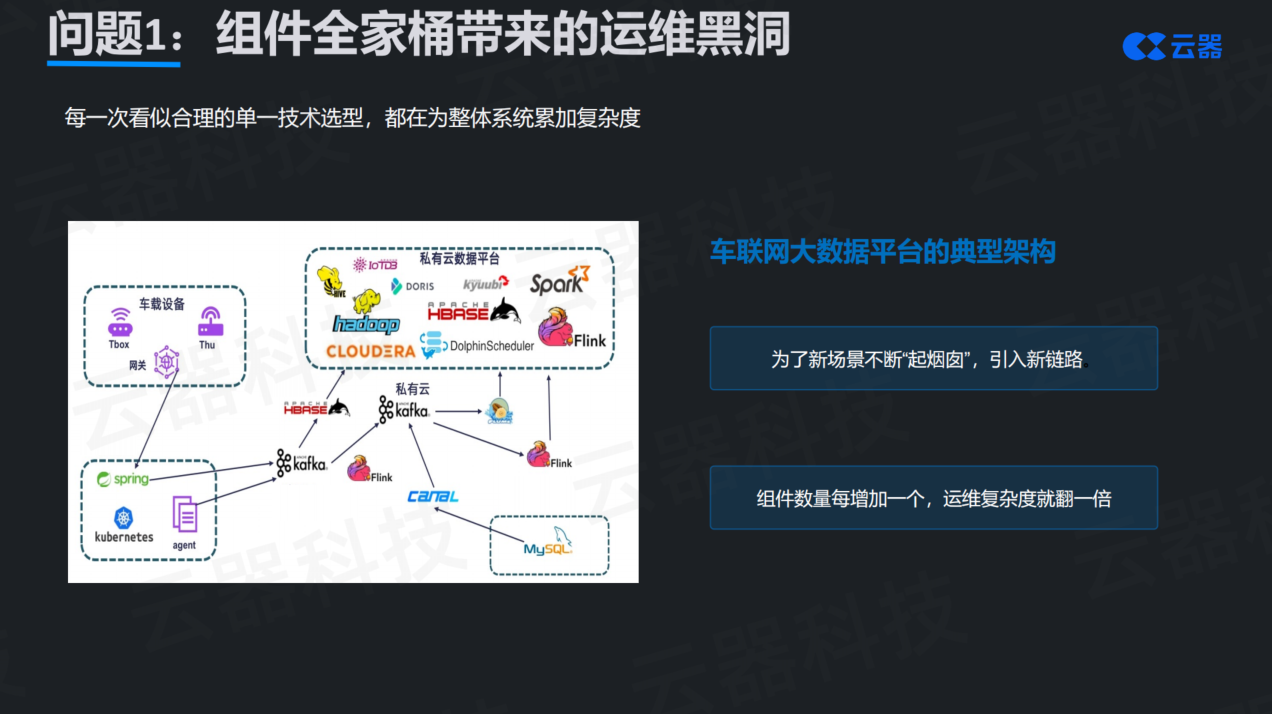
第一个问题是组件全家桶带来的运维黑洞。 典型的车联网数据平台架构图上,往往布满了各种组件:最前端是Kafka做消息队列,中间用Flink做流式采集,数据存储在HDFS或对象存储上,格式可能是CSV、Parquet或ORC。离线计算层有Spark引擎,查询层引入ClickHouse或Presto,元数据管理用Hive Metastore,任务调度采用Airflow或DolphinScheduler,有些企业甚至还有自研的调度系统。
单独看每一个组件,都是业界主流方案,技术选型无可厚非。但问题在于,当六七个甚至更多的组件拼在一起时,运维复杂度呈指数级上升。这并非危言耸听,而是血淋淋的现实教训。组件数量每增加一个,整个系统的运维复杂度就翻一番。版本兼容性、组件间通信、故障排查、性能调优,每一项都是巨大的挑战。更糟糕的是,这些组件往往由不同的开源社区维护,技术栈各异,团队需要掌握多种技术才能驾驭整个系统。

第二个问题是存算一体架构的”捆绑消费”。 早些年许多企业选择传统的存算一体架构,这种架构的优势是数据本地性好,查询延迟低。但它有一个致命缺陷:扩容时存储和算力必须同步增加,无法独立伸缩。
车联网场景下有一个非常典型的需求——单车明细查询。输入一个车架号,查出这辆车在某个时间段内所有上报的数据。这个查询看起来简单,但性能要求苛刻:业务部门通常要求在一秒左右返回结果,因为这些查询往往来自车辆开发测试或售后系统,响应慢了就会影响工作效率,引发客诉。
这种场景的QPS(每秒查询次数)并不高,但随着车辆保有量上升,存储需求持续增长。在存算一体架构下,每个节点既承载算力又承载存储,想提升存储空间就不得不为CPU买单。云器科技曾经接触过一个客户,集群有两三百个节点,实际CPU利用率长期只有30%左右,但存储已经快满了。想扩容?那就得继续买CPU,而这些CPU根本用不完。想做数据迁移?发现架构设计时根本没考虑冷热分层和迁移机制,改造工程量巨大。最终只能”忍着”,眼睁睁看着资源浪费。

第三个问题是实时与离线的两条冗余链路。 Lambda架构曾经是大数据领域的经典设计模;式一条离线链路保证数据的最终一致性,再用一条实时链路满足低延迟场景需求,最后在服务层做合并。这个设计的初衷是好的,但在车联网场景下,问题会越来越明显。
首先是开发成本翻倍。同样的业务逻辑,需要在Spark里写一遍批处理代码,再用Flink写一遍流处理代码。两套代码、两套测试、两套上线流程。云器科技曾经见过一个指标加工作业,离线版本是500行的Scala代码,实时版本是700-800行的Java代码,功能完全一样,维护起来却是两倍的人力投入。
其次是数据一致性难题。两条链路的计算逻辑理论上应该完全一致,但实际执行中难免有差异。一旦出现不一致,排查工作异常痛苦:到底是离线逻辑有问题,还是实时逻辑有问题,还是数据合并时出了问题?每次排查都像大海捞针。
最后是成本压力。实时链路需要24小时不间断运行,资源持续占用。对于那些并不需要极低延迟的场景,这种成本开销纯属浪费。但在Lambda架构下,系统没有给你折衷选项:要么忍受T+1的离线延迟,要么承担实时链路的高昂成本,只能二选一。
这三个典型问题,在云器科技接触的多家车企中反复出现,它们不是技术团队不努力,而是架构本身的局限性所致。破局的关键,在于架构层面的重新思考。
四个迭代方向:从复杂到简洁的演进路径
面对这些困境,车联网数据平台的架构演进找到了四个关键方向。这些方向并非纸上谈兵,而是在多个头部车企实战中验证过的有效路径。
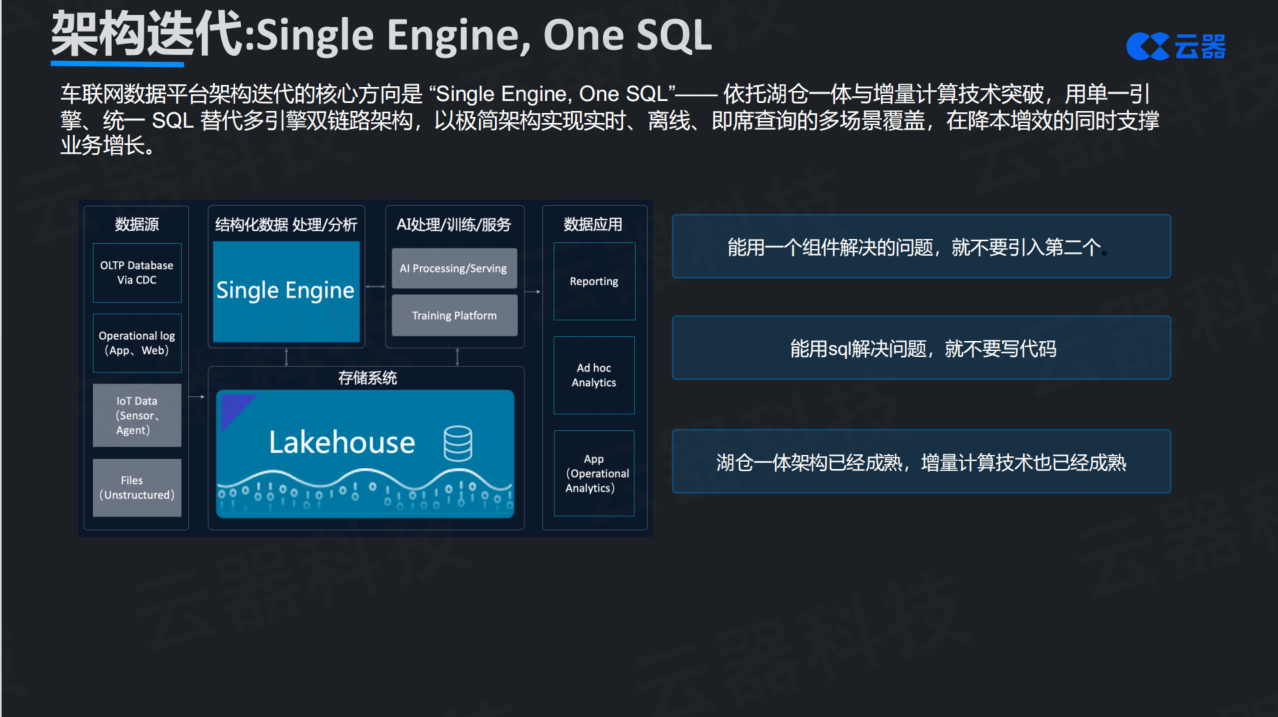
第一个方向是Single Engine,One SQL——用一个引擎统一多场景。 核心思想非常简单:能用一个引擎解决的问题,就不要用两个;能用SQL表达的逻辑,就不要写需要编译的代码。这听起来像是奥卡姆剃刀原理在架构设计中的应用,但很多人会质疑:一个引擎怎么可能满足实时、离线、即席查询这些完全不同的需求?
答案在于湖仓一体架构的成熟和增量计算技术的突破。传统离线计算采用全量模式,每次任务都要扫描全部数据、重算全部指标。当数据量达到EB级时,这种模式完全跑不动。而增量计算只处理新增或变化的数据,只更新受影响的结果,可以用接近实时的成本实现近实时的时效性。
举个具体例子。假设要计算过去七天每辆车的平均能耗。传统做法是每天凌晨跑批处理,扫描过去七天的所有数据。如果有100万台车,每台车每天1万条数据,那么一次计算就要处理700亿行数据,跑几个小时很正常。而增量计算的做法完全不同:只处理今天新增的数据,把今天的结果和历史结果做合并。每天只需处理新增的那一天数据,计算量大幅下降,几分钟就能跑完。更进一步,可以把按天调度改成五分钟一次,这样不仅时效性从T+1变成五分钟,而且原本一天的计算资源被分散到288个五分钟窗口中,单次所需资源反而更少。
这就是增量计算的魔力:打破了”要实时就得用Flink,成本高”的二元对立,提供了一个新的可能性——用接近离线的成本,实现接近实时的效果。
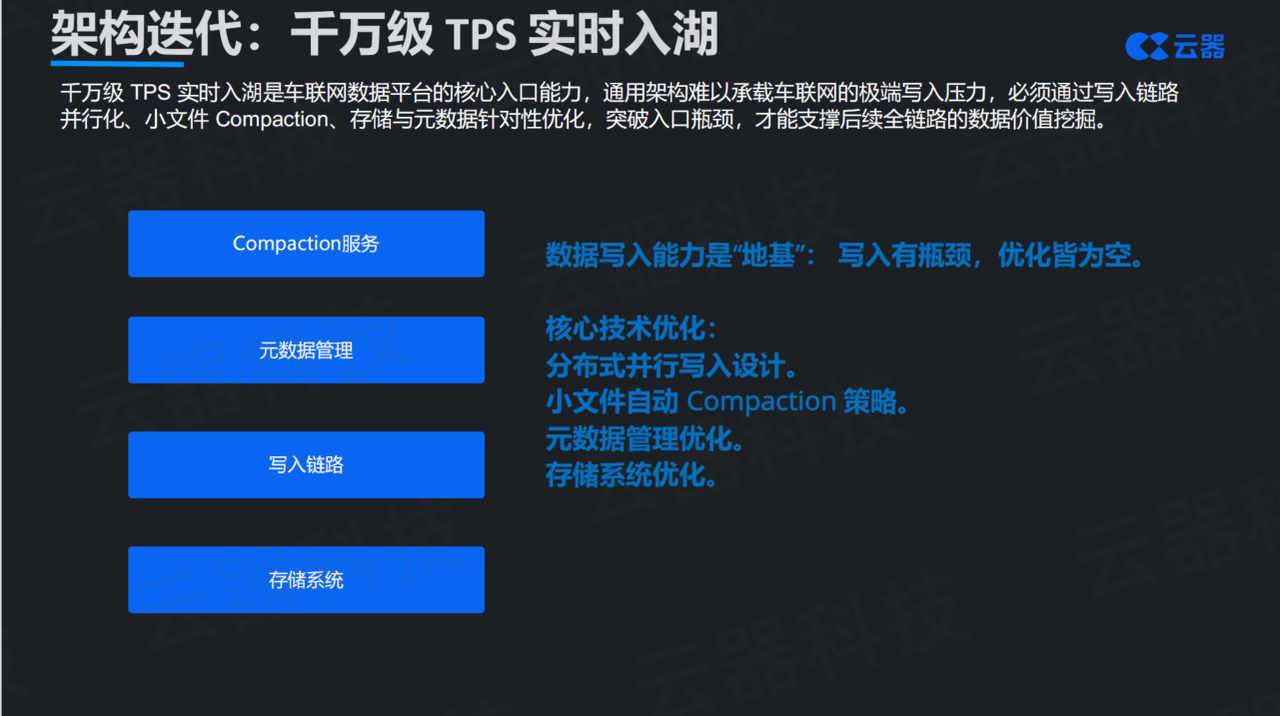
第二个方向是高并发实时入湖能力的提升。 前面提到,车联网的TPS可以达到千万级,而且需要分钟级可见。这个写入压力,传统平台确实扛不住。虽然开源组件也在不断优化迭代,但它们的设计目标是通用场景,没有为车联网这种极端场景做专门优化。
要做到千万级TPS的稳定入湖,需要在四个方面做专项优化:写入链路的分布式并行化设计、小文件自动Compaction策略、元数据管理优化、存储系统针对性优化。这些细节展开可以讲一个专场,本次就不进行详述。本品内容想强调的核心观点是:入湖能力是整个数据平台的地基,如果这里有瓶颈,后面的一切优化都是空谈。
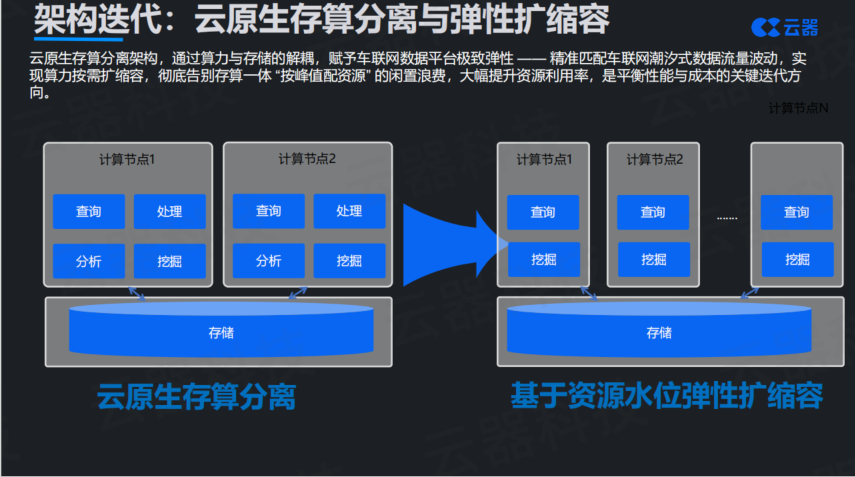
第三个方向是云原生存算分离架构。 存算分离这个概念提了很多年,但真正做到好用、稳定、成本低,还是最近几年云技术成熟之后的事。对于车联网场景,存算分离有着特别重要的价值。
车联网数据流量的潮汐特性非常明显:早晚高峰的数据量是平峰的3-5倍,节假日出行高峰甚至能到平时的10-20倍。如果采用存算一体架构,资源配置只能按峰值来,否则高峰期系统就会崩溃。但这意味着平峰期有大量资源闲置,就像为了应对春节的客流高峰,火车站全年都按春运标准配置检票口,显然不经济。
存算分离之后,算力可以按照负载动态伸缩。高峰期自动扩容,低峰期自动缩容,用完即释放。这样可以把资源利用率从传统架构的30%-38%提升到90%以上,对成本控制的效果立竿见影。
第四个方向是极致压缩与冷热数据分层。 主流车企的车联网平台日新增数据都在数十TB量级,存储成本是无法回避的问题。这里有两个优化方向特别有效。
首先是压缩。车联网数据有个显著特点:pattern(模式)非常重复。同一款车在同一时期上报的数据结构是相对固定的,信号值的取值范围也很有限。可以利用这些特点设计专门的压缩算法,配合数据排布优化,压缩比可以比通用算法高出很多,达到1:15甚至更高。
其次是冷热分层。车联网数据的访问模式非常明显:最近几天是热数据,访问频繁;几个月以前的是冷数据,偶尔才会查询,而且可以接受更高的延迟。根据这个特点,可以把热数据放在高性能存储(如SSD)上,冷数据放在低成本存储(如对象存储)上,再配合自动化的生命周期管理,可以在不影响业务的情况下大幅降低存储成本。通过这两个手段的组合,存储成本降低50%以上完全可以做到。

这四个迭代方向,构成了车联网数据平台架构演进的完整路径。但理念再好,也需要实战验证。接下来的三个真实案例,展现了这些理念如何在头部车企落地,以及带来了怎样的实际效果。
案例一:长安汽车——从Lambda到湖仓的架构收敛
长安汽车是国内自主品牌的头部车企,车辆保有量名列前茅。他们的车联网平台日新增数据达到数十TB,TPS峰值接近千万级。原有架构是典型的Lambda架构,前面提到的那些问题——组件多、运维复杂、实时离线两张皮、存储成本高——一个不少。
最直接的业务痛点是数据时效性。整体数据是T+1可见,业务部门想做一些实时场景基本不可能。这并非技术团队不努力,而是架构本身不支持。就像一辆汽车的发动机功率只有50马力,你怎么踩油门都跑不快,因为物理极限在那里。
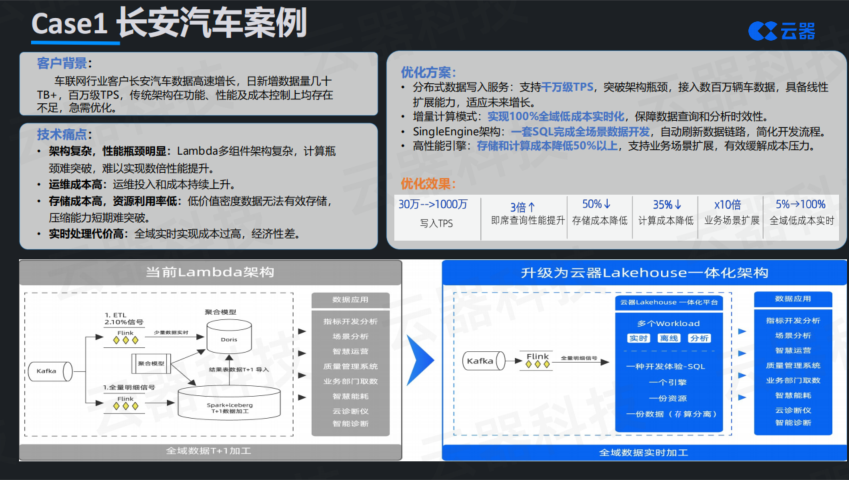
架构重构的核心思路是”精简”。把原来Lambda的多组件架构,收敛到一个一体化的湖仓平台上。数据的入湖、加工、分析、服务,全部在一套系统里完成。这样做最直接的好处是什么?数据不用在多个组件之间搬来搬去,元数据只有一份,不用担心数据一致性问题。运维人员也只需要对付一个系统,复杂度大大降低。
在入口层面,通过专门优化,写入TPS从原本的30万提升到1000万。这个能力意味着即使车辆保有量翻倍,入湖环节也不会成为瓶颈。在计算层面,全面引入增量计算模式,原来T+1才能产生的数据,现在分钟级就可以看到。
这个时效性提升对业务的意义非常直接。比如车辆故障预警这个典型场景,以往只能基于T+1的数据来判断,很多故障虽然有前兆,但等发现时往往已经晚了。现在能够在几分钟内发现异常征兆并推送预警,用户体验和安全性都大幅提升。
在查询层面,由于架构统一,即席查询不再需要额外的组件和链路。业务侧可以直接用SQL查询最新数据,响应时间从原来的几个小时缩短到几秒钟或几分钟。最终效果是:即席查询性能提升3倍以上,存储计算成本降低50%,更重要的是大数据团队从救火队员状态中解脱出来,可以把更多精力放在业务价值创造上。
案例二:长城汽车——单车明细查询的极致优化
长城汽车的案例聚焦在一个更具体的场景:车况大数据平台的单车明细查询。这个场景看起来简单——提供实时查询单车状态和历史轨迹的能力——但技术挑战很高。因为查询的是单车明细而非聚合指标,没法通过预聚合加速。数据量又很大:数百万台车,近百万台实时在线,累计数据达到万亿级别。在这个量级上要实现百毫秒级的查询响应,同时还要控制成本,对架构设计要求很高。
原有架构为了满足性能要求,采用HBase和InfluxDB这类专用数据库。但问题在于这两个组件都是存算一体架构。车子卖得越多,数据采集量越大,存储需求持续增长。存储不够了只能扩容,但扩容必须同时增加计算资源,而实际上计算需求并没有增长,导致严重的资源浪费。
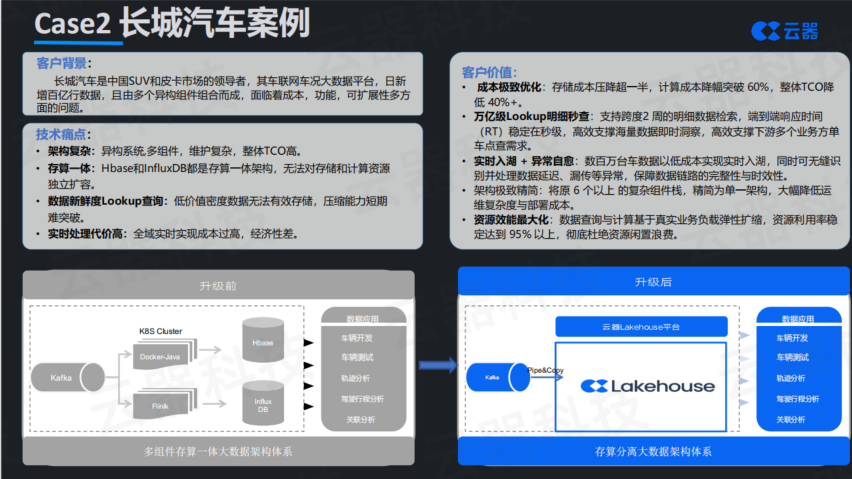
架构重构的思路是如何平衡查询性能和成本。具体技术手段包括:基于车架号做数据分桶,结合时间分区,让查询快速落到数据所在位置;构建多层缓存体系,元数据变更主动通知,热数据放内存缓存,温数据放SSD缓存,冷数据只保留在对象存储;查询优化器专门设计,能够识别点查模式并选择最优执行路径。
最终效果令人印象深刻:单车明细查询稳定在百毫秒左右返回,同时还能在同一套组件上跑复杂的关联分析。存储成本降低50%以上,计算成本下降60%以上。这个案例说明,成本优化和性能保证并非对立,关键在于数据模型设计、执行引擎优化以及架构选择。
案例三:安凯汽车——商用车场景的SaaS化路径
安凯汽车的案例和前两个有所不同。长安、长城是头部乘用车企业,车辆保有量大、数据量大、预算也相对充裕。而安凯是商用车企业,规模相对没有那么大量,但面临的问题同样真实。
商用车企的典型特点是:数据量没有乘用车那么夸张,但该有的场景一个不少——离线分析、实时处理、MPP查询全都需要。问题是预算有限,团队也很小,不可能像大厂一样配置二三十人的大数据团队。更麻烦的是,商用车涉及客运,监管对安全要求非常严格,等保测评等合规要求一项不能少。
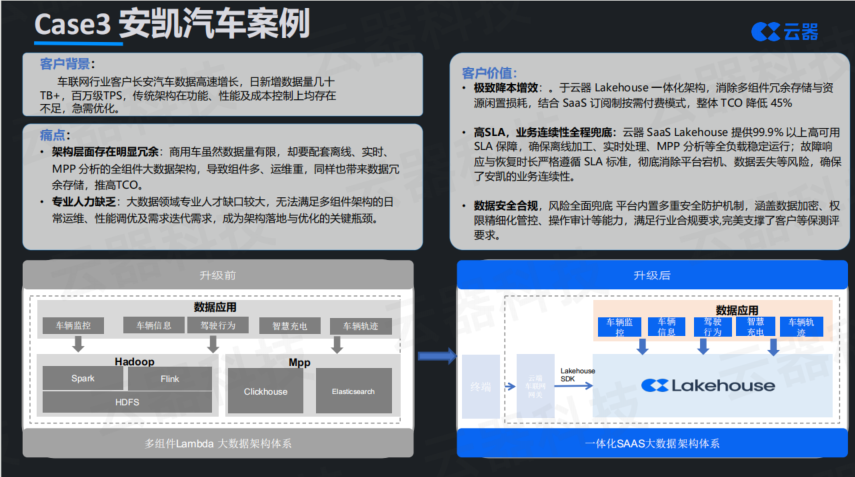
这种情况下,自建大数据平台显然不现实。架构重构的思路是托管优先,采用SaaS化的湖仓平台。一方面通过一体化架构消除多组件冗余存储和资源闲置,另一方面采用订阅制按需付费模式,整体TCO(总拥有成本)降低45%。
更重要的是,SaaS平台提供99.9%以上的高可用SLA保障,确保离线加工、实时处理、MPP分析等全负载稳定运行,故障响应与恢复时长严格遵循SLA标准,彻底消除平台宕机、数据丢失等风险。平台内置多重安全防护机制,涵盖数据加密、权限精细化管控、操作审计等能力,完美支撑了客户的等保测评要求。
这个案例的价值在于,它展示了一条适合中小规模车企的路径:不是所有企业都需要自建复杂的大数据平台,通过SaaS化的方式,同样可以获得先进的数据能力,而且成本更低、风险更小。
未来趋势:AI时代的数据平台
随着AI大模型在汽车行业的应用深入,数据平台将面临新的挑战和机遇。
一方面,大模型应用(智能客服、智能诊断)需要高质量、可被快速访问的数据。数据平台是AI时代的基础设施,就像电力是工业时代的基础设施一样。没有高质量的数据底座,再先进的算法也是空中楼阁。
另一方面,随着智能驾驶技术的演进,EB级时代正在到来。点云、图像、视频等非结构化数据与传统结构化数据融合,数据形态更加复杂。如何在EB级规模下优化存储消耗和算力管理,将是下一阶段的核心命题。

但无论技术如何演进,架构设计的第一性原理不会变:如无必要,勿增实体。能用一个引擎解决的问题,就不要用两个。真正优秀的架构师,不是维护最多组件、搭建最复杂系统的人,而是能用最精简的架构支撑业务增长的人。这是从救火队员到效能提升的关键转变,也是车联网数据平台架构演进的核心价值所在。
🎁 新用户专享福利
✅ 1 TB 存储 · 1 CRU时/天计算 · 1 年全托管体验
➤ 即刻访问云器官网领取:https://www.yunqi.tech/product/one-year-package

