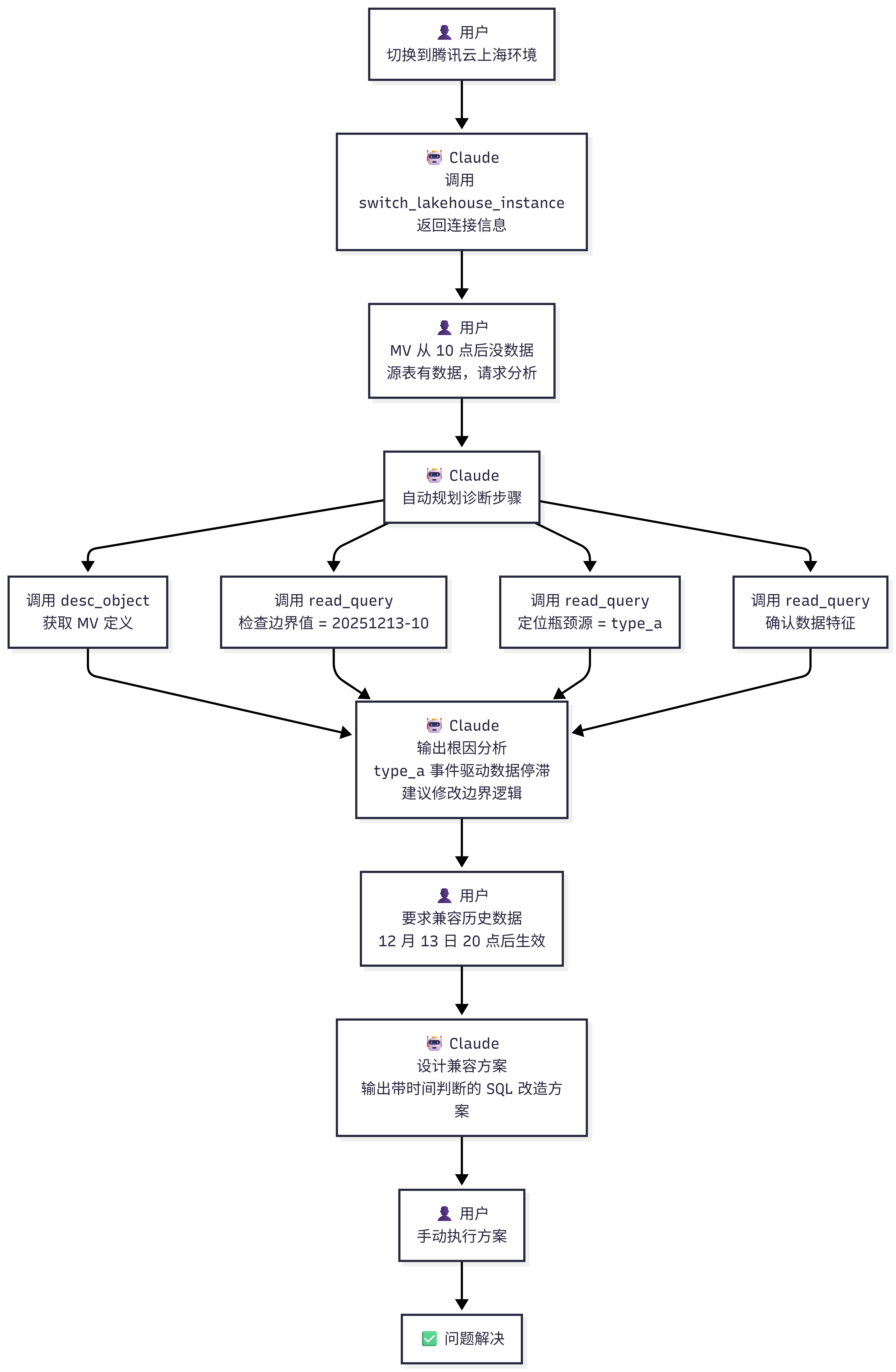
-- Claude 自动执行
DESC TABLE EXTENDED report_schema.daily_summary_mv
Claude 从返回的
view_text
view_text
中识别出关键逻辑:
📍 发现关键线索!
物化视图中有一个 MaxDateHour 的边界控制逻辑,它取两个数据源的最小值作为边界:
WITH MaxDateHour AS (
SELECT MIN(max_ts) AS max_ts -- ⚠️ 取最小值!
FROM (
-- 第一路数据
SELECT MAX(CONCAT(ds, '-', hh)) AS max_ts
FROM event_details WHERE event_type = 'type_a'
UNION ALL
-- 第二路数据
SELECT MAX(CONCAT(ds, '-', hh)) AS max_ts
FROM metrics_data
) t1
)
诊断步骤 2:检查边界值
-- Claude 自动执行
SELECT MIN(max_ts) AS current_boundary
FROM (
SELECT MAX(CONCAT(ds, '-', hh)) AS max_ts
FROM raw_schema.event_details WHERE event_type = 'type_a'
UNION ALL
SELECT MAX(CONCAT(ds, '-', hh)) AS max_ts
FROM raw_schema.metrics_data
) t1
-- Claude 自动执行:分别检查两个数据源
SELECT 'source_a (type_a only)' AS source, MAX(CONCAT(ds, '-', hh)) AS max_ts
FROM raw_schema.event_details WHERE event_type = 'type_a'
UNION ALL
SELECT 'source_a (all types)' AS source, MAX(CONCAT(ds, '-', hh)) AS max_ts
FROM raw_schema.event_details WHERE event_type IN ('type_a', 'type_b', 'type_c')
UNION ALL
SELECT 'source_b' AS source, MAX(CONCAT(ds, '-', hh)) AS max_ts
FROM raw_schema.metrics_data
ORDER BY source
-- Claude 自动执行:查看各类型的数据分布
SELECT event_type, MAX(hh) as max_hour, COUNT(1) as record_count
FROM raw_schema.event_details
WHERE ds = '20251213' AND event_type IN ('type_a', 'type_b', 'type_c')
GROUP BY event_type
ORDER BY event_type
💡 迭代技巧:AI 给出的初步方案可能不完全符合业务需求。业务需求的背景知识并不存在于 AI 这次对话的上下文中,所以必须由人来充分考虑,并将这种业务约束补充给 AI。在使用 AI 来协助运维和解决问题时,不能放弃思考,无脑遵循 AI 给出的建议来执行。尤其需要提供的是“为什么有这个约束”,这样更能发挥 AI 的思考、推理能力。
通过追加约束条件,让 AI 生成更精准的方案:
📌 明确约束:不能影响历史数据
📌 给出边界:从什么时间点开始生效
📌 说明原因:为什么有这个约束
Claude 输出:兼容性改造方案
Claude 理解了业务约束后,设计了一个向后兼容的方案:
设计思路
需要修改 MaxDateHour 的逻辑,使其:
- 2025年12月13日20点之前:继续使用原来的 type_a 边界(保护历史数据)
- 2025年12月13日20点及之后:使用新的全类型边界
兼容性改造 SQL
WITH MaxDateHour AS (
SELECT
SPLIT(t2.max_ts, '-')[0] AS max_ds,
SPLIT(t2.max_ts, '-')[1] AS max_hh,
t2.max_ts
FROM (
SELECT MIN(max_ts) AS max_ts
FROM (
-- 数据源 A(兼容历史逻辑)
SELECT GREATEST(
-- 原逻辑:只用 type_a(保护历史数据)
(SELECT COALESCE(MAX(CONCAT(ds, '-', hh)), '19700101-00')
FROM raw_schema.event_details
WHERE event_type = 'type_a'),
-- 新逻辑:全类型边界,仅在 >= 切换时间点后生效
(SELECT CASE
WHEN MAX(CONCAT(ds, '-', hh)) >= '20251213-20'
THEN MAX(CONCAT(ds, '-', hh))
ELSE '19700101-00'
END
FROM raw_schema.event_details
WHERE event_type IN ('type_a', 'type_b', 'type_c'))
) AS max_ts
UNION ALL
-- 数据源 B(保持不变)
SELECT MAX(CONCAT(ds, '-', hh)) AS max_ts
FROM raw_schema.metrics_data
) t1
) t2
)
逻辑说明
| 场景 | type_a 边界 | 全类型边界 | GREATEST 结果 | 效果 |
|------|-------------|------------|---------------|------|
| 历史数据 (< 切换点) | 20251213-10 | 返回最小值 | 20251213-10 | ✅ 保持原逻辑 |
| 新数据 (≥ 切换点) | 20251213-10 | 20251213-18 | 20251213-18 | ✅ 使用新逻辑 |
第四步:根据Claude建议的方案,对线上逻辑进行修复(2分钟)
在这个案例中,直接按照上述逻辑在线上环境中手动更新了MV的DDL,重建MV后,成功修复了线上问题。
其实也可以直接要求 Claude 根据上述方案操作修改该 MV 进行修复,现有工具能力完全可以实现。但考虑到线上环境较为复杂,为了避免大模型幻觉造成操作失误并引发其他问题,个人对于线上数据和表的修改、写入、重建等操作,还是倾向于采用更稳妥的人工执行方式。
还有一种方式是让 Claude 根据上述方案创建一个临时视图,然后自动比对两个视图的数据,验证无误后,再更新原 MV 的 DDL。这样会更加稳妥。这个案例中的问题比较直白,为了快速修复,就省去了这一步骤。