
Lakehouse作业历史
概述
Lakehouse 作业历史页面(Job Profile)为你提供了一个直观的方式来查看过去 7 天内在 Lakehouse 账户中执行的查询的详细信息。你可以通过该页面查看包括使用 JDBC 接口提交的任务、Studio 临时查询、Studio 周期调度任务在内的历史作业列表。本指南将帮助你分析运行出错或运行缓慢的作业,并提供相应的解决方案。
作业历史搜索
- 支持根据 SQL 作业的作业 ID 进行搜索。
- 支持根据状态搜索:
- setup: SQL 初始化阶段,包含编译优化等操作。
- resuming_cluster: 等待启动 VC 耗时,如果长时间未拉起,请联系技术支持。
- queued: 作业排队等待资源,如果耗时较长,建议查看 VC 资源是否占满,或考虑扩容 VC。
- running: SQL 处理数据时间,可以点击诊断查看每个算子耗时。
- finish: 运行结束,部分作业可能在这一阶段进行清理过程,会产生耗时。
- 支持按耗时筛选
- 支持按时间筛选,目前最多能查询到近七天的 10,000 条作业。
- 支持按作业运行的集群名称进行筛选
- 支持按作业的提交人进行筛选
- 支持根据 queryTag 筛选
用户在提交 SQL 时,可以通过命令
来标记作业来源或为作业打标,并在此界面进行过滤。set query_tag=""- 在 Studio 界面设置 query_tag,选中两条 SQL 同时执行:
- 在 JDBC URL 中添加 query_tag,这样提交的每条 SQL 都会带上 query_tag 用来标识来源,可以在页面中进行过滤。
- 在 Python 代码中设置 query_tag
- 作业的默认 Schema(即提交 SQL 时运行的上下文环境),可以通过
获取。select current_schema()
分析运行出错的作业
当作业运行失败时,你可以通过作业的 Job Profile 中的详情来查看失败原因。以下是一些常见的失败原因及解决方法:
SQL语法错误
错误示例:
错误码 CZLH-42000 表示与 SQL 语言解析相关的错误。[1,15] 表示错误发生在 SQL 的第 1 行第 15 列。在这个例子中,原因是
ttt分析运行缓慢的作业
运行缓慢的作业可能在编译阶段、Virtual Cluster 拉起阶段或执行阶段出现问题。以下是针对这些阶段的分析和解决方法:
编译阶段
问题现象:作业状态显示为“初始化”。
可能原因及解决措施:
- 执行计划复杂:作业可能需要较长时间进行优化。请耐心等待,正常情况下不会超过 10 分钟。
- 编译资源被占满:如果你一瞬间提交了大量 SQL,可能导致编译资源不足。请减少提交 SQL 的频率。如有大量高并发查询需求,请提交工单寻求帮助。
拉起virtual cluster阶段
问题现象:作业状态显示为“集群启动中”。(当前状态为正在拉起计算集群)
等待执行阶段
问题现象:作业状态显示为“等待执行”。
可能原因及解决措施:
- 当前集群的计算资源不足:你可以通过界面筛选查看当前正在运行的作业。可能因大量作业正在运行导致资源等待。可以考虑扩容资源,或者终止正在运行的大作业以释放资源。
执行阶段
问题现象:作业状态显示为“正在执行中”。在这一阶段,你可以点进去查看每个算子的执行情况。
可能原因及解决措施:
- 等待资源:作业可能在等待资源分配。请检查资源使用情况,如有需要,请提交工单寻求帮助。
- 数据读取速度慢:作业可能因为数据读取速度慢而导致执行缓慢。请检查数据存储和读取策略,如有需要,请优化数据存储结构或调整读取策略。
分享给其他人诊断
进入作业详情页面后,点击“分享”按钮,即可将作业分享给其他人。接收者无需登录即可查看内容。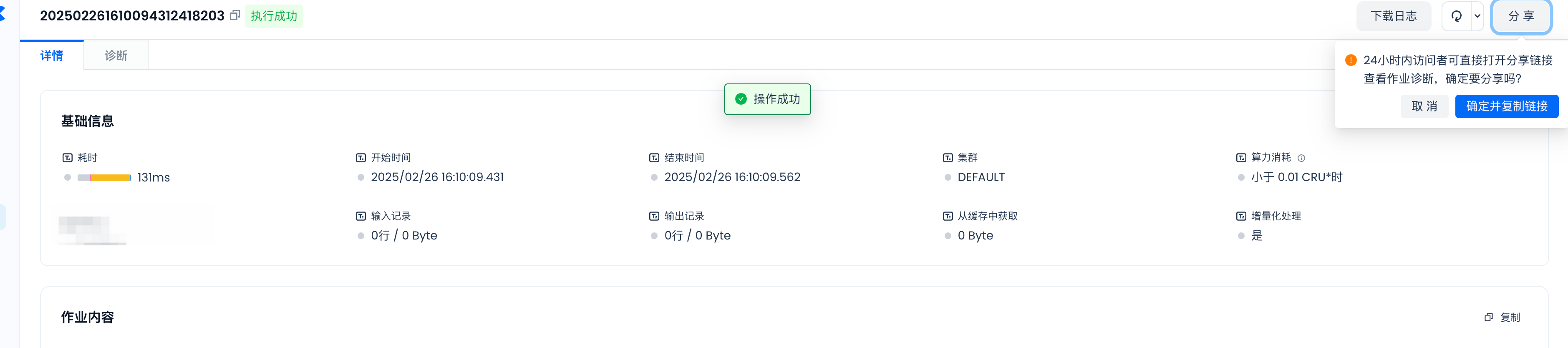
如有疑问或需要进一步帮助,请复制上方链接并联系 Lakehouse 团队,我们将为你诊断并解决问题。
查看执行计划和Operator详情
在执行阶段,你可以通过点击正在执行的 Operator 来查询具体的步骤和策略。例如,将鼠标悬停在具体的 Operator 上,可以对应到 SQL 中具体执行的算子。这有助于你发现具体是哪个 Operator 导致作业缓慢。
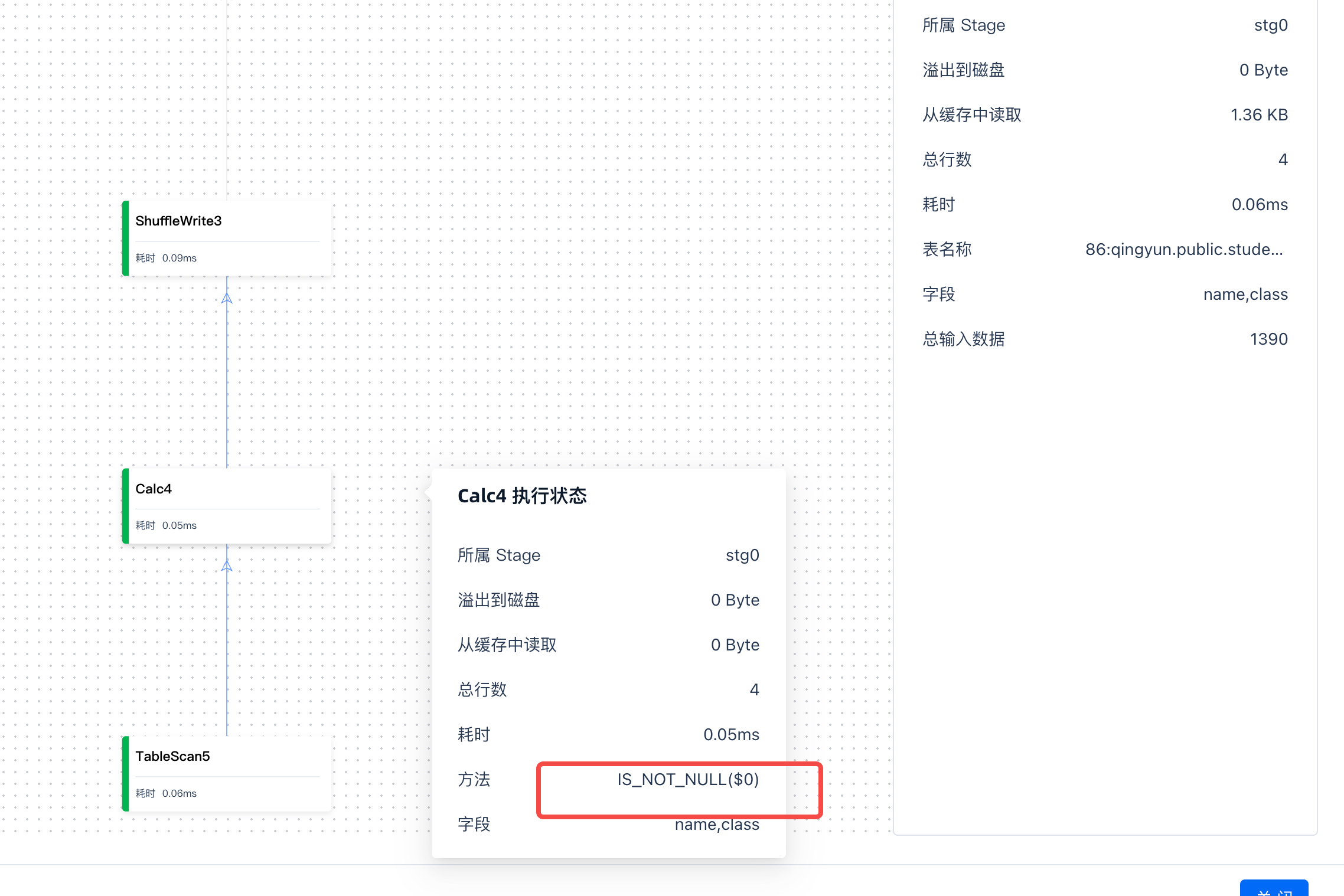
联系我们