
在云器 Lakehouse 的同一张表中进行向量和标量检索
数据准备
GitHub 提供 15 多种事件类型,包括新提交和分叉事件、打开新工单、评论和向项目添加成员等。这些事件会汇总到每小时存档中,您可以使用任何 HTTP 客户端从 https://www.gharchive.org/ 上访问这些存档。
- 通过 wget 从 https://www.gharchive.org/ 将归档的 json.gz 文件下载到本地。本文下载了 2025-01-01 一天的 24 个文件。
- 通过 Lakehouse 的 PUT 命令,将数据 PUT 到用户卷 (USER VOLUME) 上。
- 通过 SQL 直接读取用户卷 (USER VOLUME) 目录里的文件,然后将 IssuesEvent 类型的事件写入
github_event_issuesevent表中。 - 将数据从 github_event_issuesevent 写入到目标表 github_event_issuesevent_embedding 中。
数据向量化
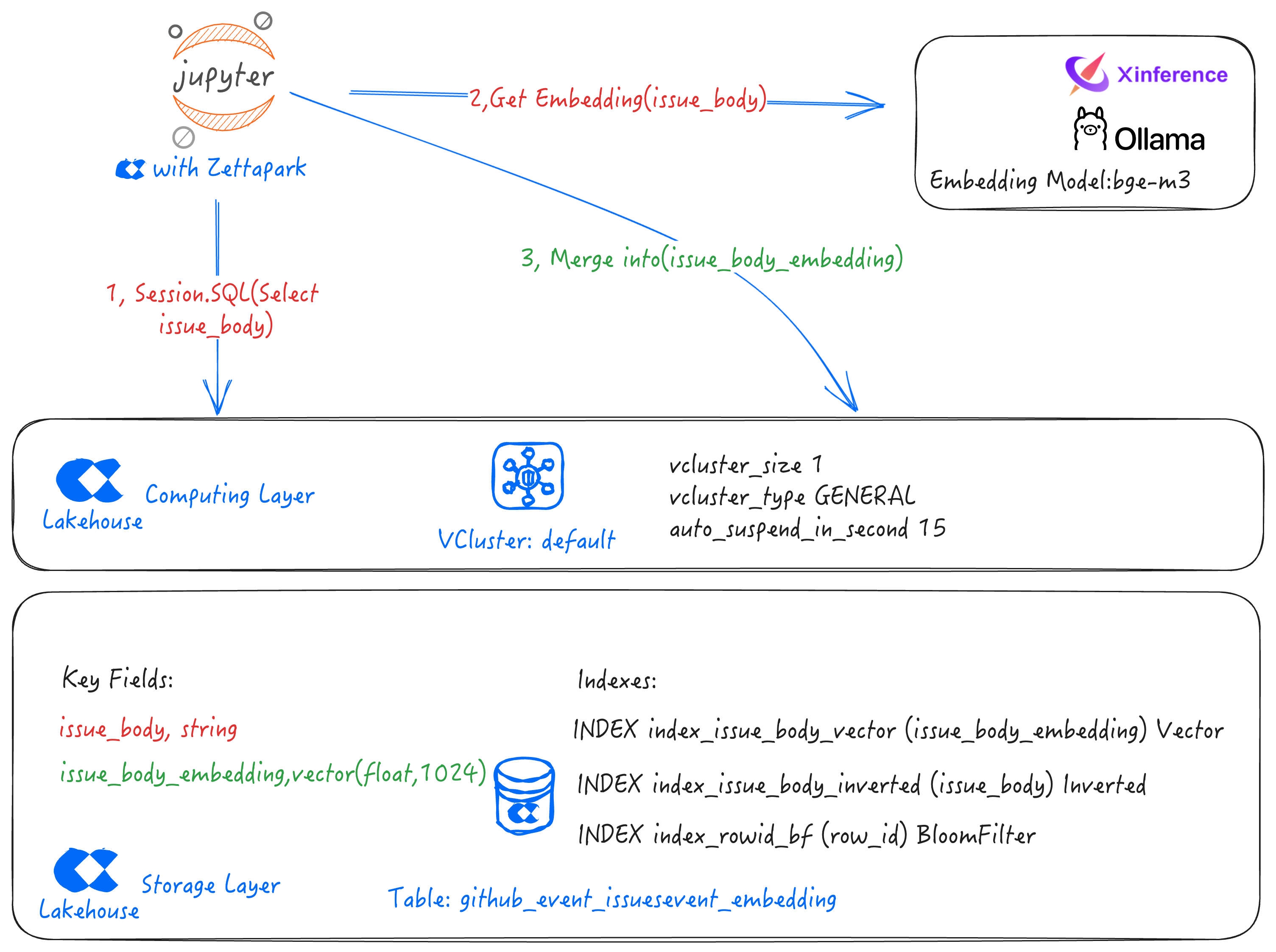
云器 Lakehouse 的 github_event_issuesevent_embedding 表中保存了文本字段,需要对该文本字段进行向量化,并保存在同一张表的向量字段里,方便进行向量和标量的融合检索。
该方案在同一张表、同一个 VCluster 中,同时支持文本数据、向量数据以及倒排索引和向量索引的存储。与传统方式相比,不再需要三套系统(数据仓库、文本检索数据库、向量数据库),最大程度地降低了数据副本数量,避免了数据在三套系统之间的同步。
用到的云器 Lakehouse 关键特性
- 向量存储:原生的Vector数据类型,在普通表里直接增加Vector类型的字段;
- 向量索引:对Vector类型的字段建立索引,加速向量检索的速度;
- 倒排索引:对文本字段建立倒排索引,加速文本检索的速度;
- bloom_filter索引:对ID字段建立索引,加速ID过滤;
- Zettapark
模型服务
- xinference,本地部署xinference,提供embedding和rerank模型服务;
- 本方案采用 1024 维的向量表示。
测试数据集介绍
- 数据来源是 GitHub 的 IssuesEvent 事件,全文检索字段为其中的
issue_body。 - 向量字段存储的是
issue_body对应的向量化数据。 - 全表有 1.9 亿条记录。
数据说明
- 表名:
github_event_issuesevent_embedding - 文本字段:
issue_body,string 类型 - 向量化字段:
issue_body_embedding,vector(float,1024) 类型 - 向量化方法:
issue_body_embedding的初始值为 NULL。调用 xinference/ollama 本地服务,用 bge-m3 模型对issue_body字段的文本进行向量化,然后保存到issue_body_embedding字段。
issue_body_embedding字段更新方法
-
单条 Update 方法
- 符合传统数据库开发者的习惯,数据更实时,达到秒级数据新鲜度。但是在大数据平台上用 SQL 进行频繁的 UPDATE,会带来明显的弊端:
- 带来大量的小文件需要及时进行合并,以优化性能。
- 需要一直启动 VCluster,造成计算成本高。
- 符合传统数据库开发者的习惯,数据更实时,达到秒级数据新鲜度。但是在大数据平台上用 SQL 进行频繁的 UPDATE,会带来明显的弊端:
-
批量 Merge Into 方法
- 牺牲了数据新鲜度,从秒级到分钟级。
- 规避了小文件急剧增多的问题。
- 大幅降低了计算成本,每 5 分钟 MERGE INTO 一次,计算成本下降幅度可达 80%,大幅提升了数据向量化的性价比。这对大数据量的向量化非常重要。
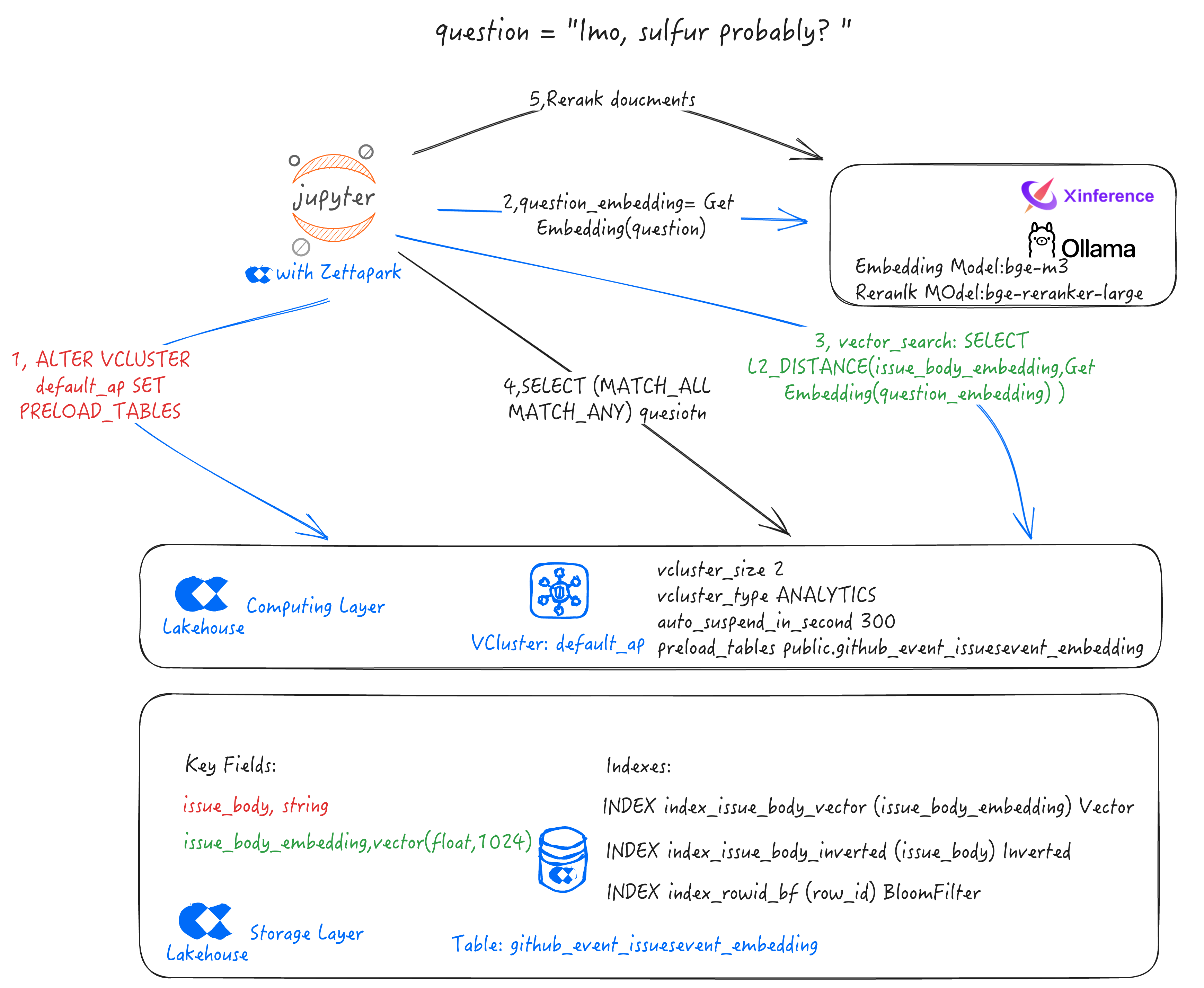
融合检索
- 参考并已完成在云器 Lakehouse 的同一张表中进行向量和标量存储。
- 检索过程
源代码
本文提供了 GitHub 上基于 Notebook 的源代码如下:
参考资料
联系我们