
使用Lakehouse计算集群
一、概述:为什么需要“计算集群”?
在云器Lakehouse中,无论是执行离线/实时数据集成,进行复杂的ETL任务,还是进行实时/离线的交互式查询,都需要使用Lakehouse提供的计算集群(Virtual Cluster,简称Vcluster)。计算集群支持:
- 按需启动与停止:无查询或作业时可自动停止,避免资源闲置带来的成本浪费;有新作业或查询到来时可自动启动,保障及时处理。
- 灵活规格选择:可根据作业负载和并发度,快速“垂直扩容”或“水平扩展”。
- 多种使用方式:可通过Web界面或SQL DDL命令方式完成集群创建、启动、停止、调整大小、权限管理等操作。
这份文档将结合Lakehouse计算集群的特性与操作方法,结合实际应用场景给出一些应用示例和最佳实践。
二、核心概念与主要功能
1. 集群名称
每个云器计算集群都有唯一名称,在其所在的工作空间下不可重复。计算集群一旦创建,名称不可更改。
2. 规格
在Lakehouse中,规格以 “CRU(Compute Resource Unit)”为单位,如(1CRU,2CRU,4CRU...直至256CRU)。根据需求可选择通用型/分析型/同步型集群,并配置对应的集群大小。
注意:更大规格的集群意味着更高的负载能力和查询性能,同时也会产生更高的成本。可根据业务负载和成本预期,在使用过程中调整、优化集群规格。
3. 集群类型
Lakehouse计算集群分为通用型(General Purpose 简称:GP)、分析型(Analytics Purpose,简称AP)和同步型(Integration Purpose,简称:Integration)。
- 通用型(GP):适合离线作业或综合场景,同一计算集群中的作业资源共享、公平调度。可自动弹缩规格大小(纵向扩缩容)。
- 分析型(AP):适合ad-hoc和高并发在线作业场景,同一计算集群中的作业独占资源,根据作业先后排队执行。可根据并发负载自动弹缩副本数(横向扩缩容)。
- 同步型(Integration):适合实时/离线数据集成等同步任务,多个集成任务可共用一个实例,可根据负载自动弹缩规格大小(纵向扩缩容)。
4. 自动启动 & 自动停止
自动启动:当有新的查询作业提交到集群时,若集群处于“停止运行(suspended)”状态,则自动启动以执行任务。
自动停止:在集群配置的自动停止时间内无作业/查询任务后,集群自动停止并释放计算资源,不再产生计费。
5. 多实例弹缩
Lakehouse的分析型计算集群可设定“实例最小值”和“实例最大值”,在并发请求高时自动加实例,并发请求下降后自动回收实例,满足查询业务需求的同时,节省资源成本。
6. 计费方式
按照计算集群的实际运行时间计费,精确到秒,最小计费周期1分钟。通过合理设置计算集群规格以及自动停止、自动启动等策略,可有效节省计算成本。
三、常见使用场景与使用示例
场景 1:离线ETL作业负载
需求:每天或每小时执行数据清洗/转换,数据规模较大,耗时几十分钟到数小时,但在作业空闲期不希望一直空耗计算集群成本。 解决方案:
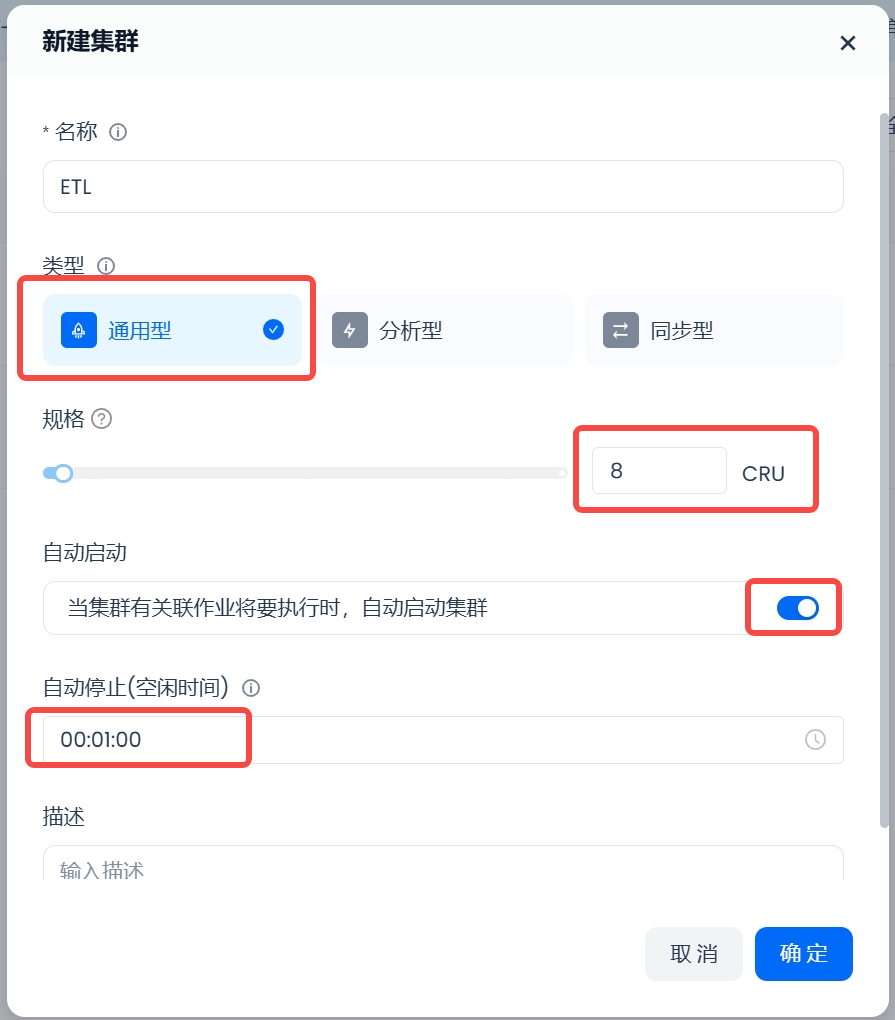
1. 创建通用型计算集群
在需要执行ETL作业的工作空间内,创建一个通用型计算集群。根据数据量和作业完成预期配置集群规格大小,可参考计算集群中的下表进行估算和配置:
| 业务场景 | 负载类型 | 执行频率 | 作业并发 | 处理数据规模 | VCluster类型 | 作业时延SLA | VCluster 规格 |
|---|---|---|---|---|---|---|---|
| ETL调度作业 | 近实时离线处理 | 小时 | 1 | 1 TB | 通用型 | 15 分钟 | 4 |
| ETL调度作业 | T+1离线处理 | 天 | 1 | 10 TB | 通用型 | 4 小时 | 8 |
假设需要处理的数据为10TB,预期4小时内需要完成。则需要创建一个规格为8 CRU的通用型计算集群。
2. 配置自动停止时间设置为1分钟,确保作业结束后能及时释放资源。
3. 开启“自动启动”配置,当每次ETL调度任务启动时,能够自动拉起该计算集群。
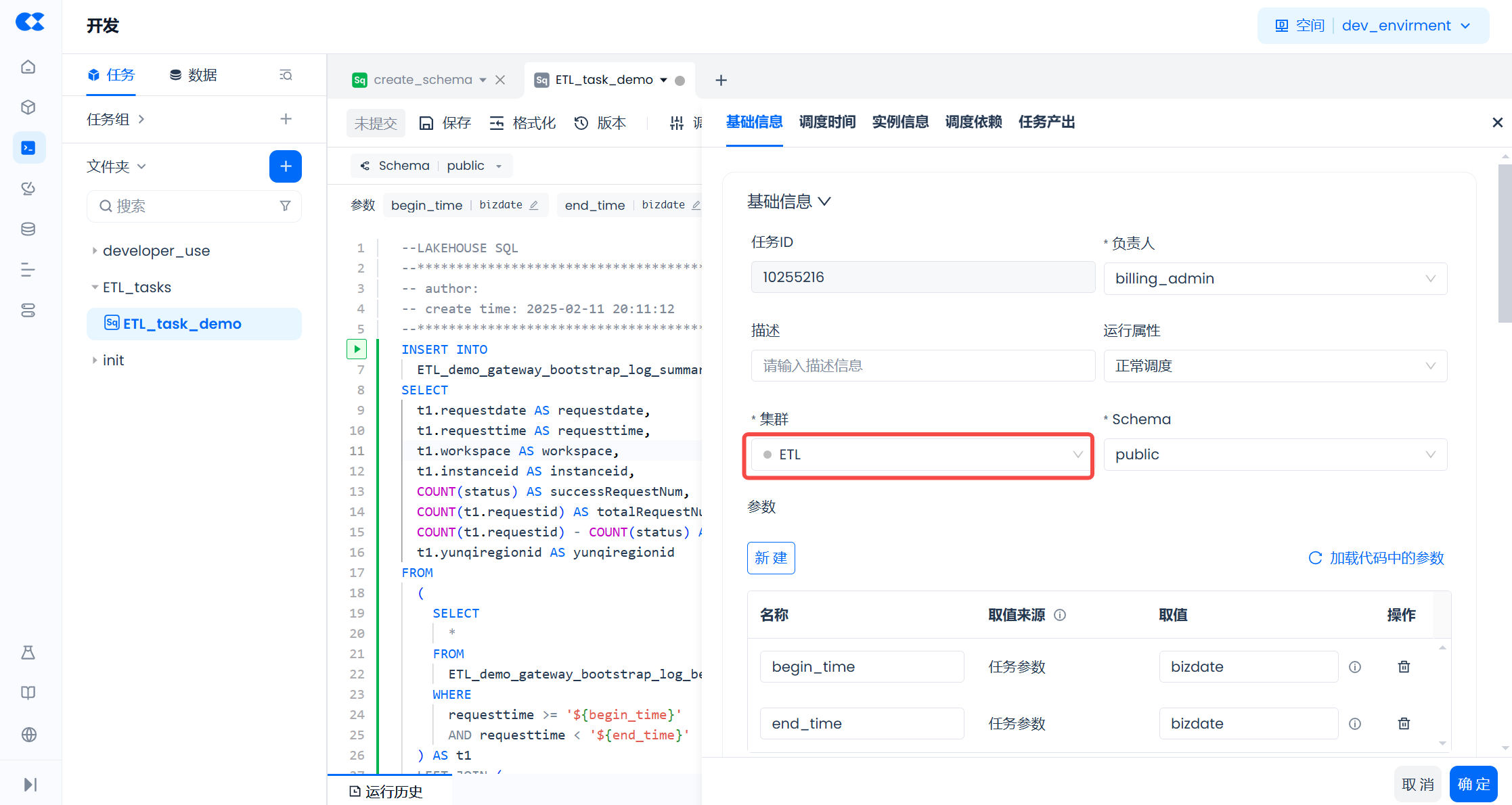
4. 在ETL任务(ETL_task_demo)的调度配置中,将任务执行的计算集群配置为上一步设置的ETL集群。更多调度配置的操作可参考任务开发与调度文档中的相关内容。
效果:
1. 当ETL任务(ETL_task_demo)开始执行时,通用型计算集群ETL 会自动启动。
2. 当ETL任务(ETL_task_demo)执行结束后,通用型计算集群ETL会在空闲1分钟后自动关闭。
场景 2:在线报表+实时查询
需求:每天工作时段,多个业务人员/分析师同时开始通过APP或BI进行业务查询,要求查询结果返回的延迟低、等待队列短。且为了提高资源使用效率,希望计算集群的资源消耗能够随着业务人员使用的规模动态弹缩,在无业务时能够自动关闭集群,节省成本。 解决方案:
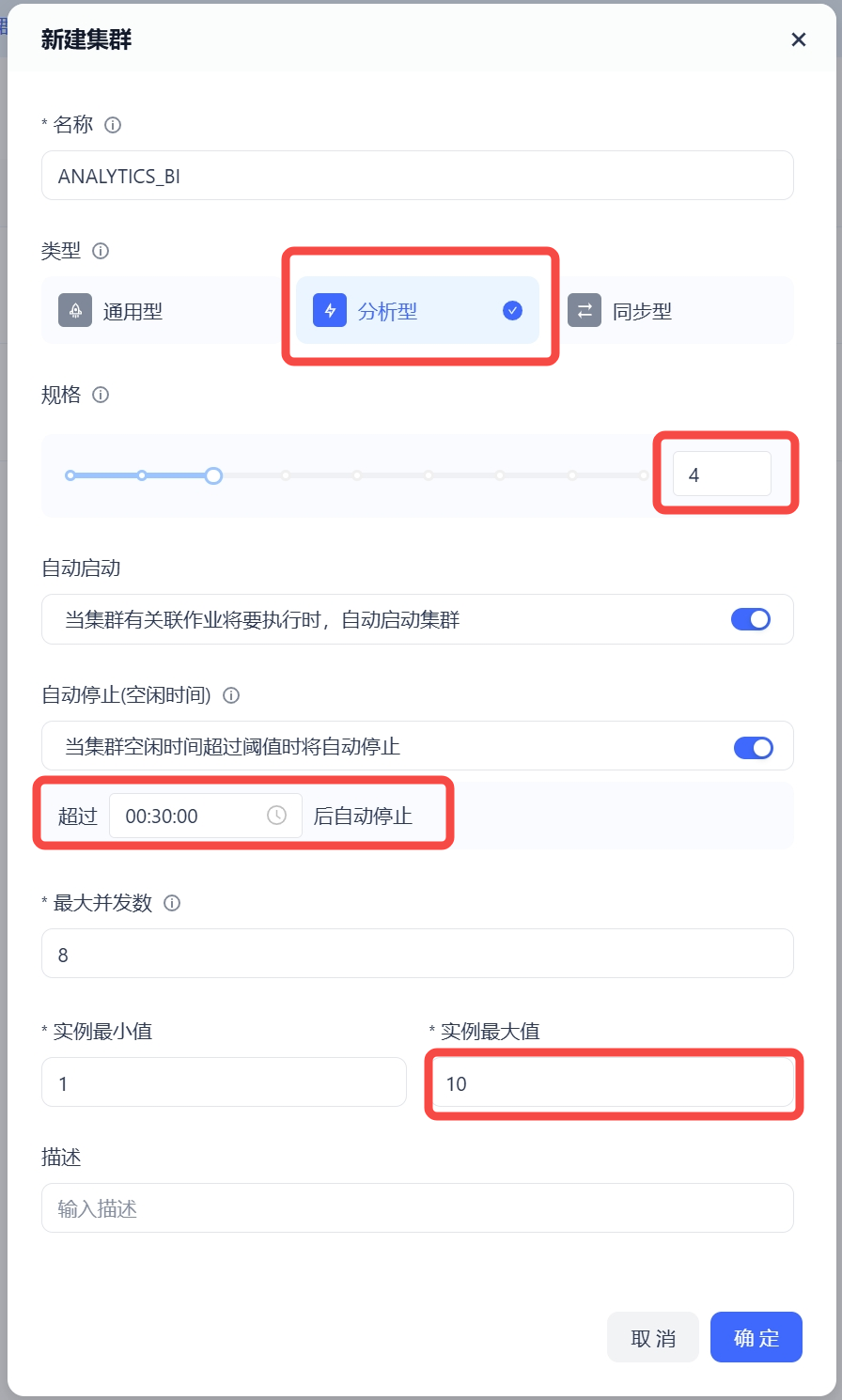
1. 创建分析型计算集群,并设置:
实例规格为4 CRU;
实例最小值为1,最大值为10;
每实例的最大并发数为8;
开启自动启动;
自动停止时间为30 分钟。
这样预期100GiB数据量的复杂查询,能在3秒内返回查询结果。计算集群运行时,最小规模下可以支持8并发,最大可以支持80并发的查询。超过80并发时,新增的并发请求会开始排队。超过30分钟空闲后,该计算集群将自动关闭,停止产生计算成本。关机时间延长至30分钟而非1分钟,可尽量减少频繁重启对查询体验的影响,也能保留缓存更快响应后续查询,兼顾成本和查询效果。如需主动将热点表预加载到集群缓存,参考计算集群缓存。
2. 在APP或BI链接Lakehouse执行查询作业时,配置使用ANALYTICS_BI这个计算集群执行查询任务。以JDBC为例,连接串如下:
以virtualCluster=ANALYTICS_BI参数指定执行查询任务的计算集群为ANALYTICS_BI。
效果:
实时查询处理效率高,当用户查询量激增时,会自动扩容新实例,避免排队。保证高并发下依然有良好性能。空闲时则缩容节省成本。
场景 3:临时分析/数据探索
需求:数据科学家对大规模数据做探索性分析,包括反复多表Join和高级聚合。需要能够在复杂查询时快速返回查询结果。 解决方案:
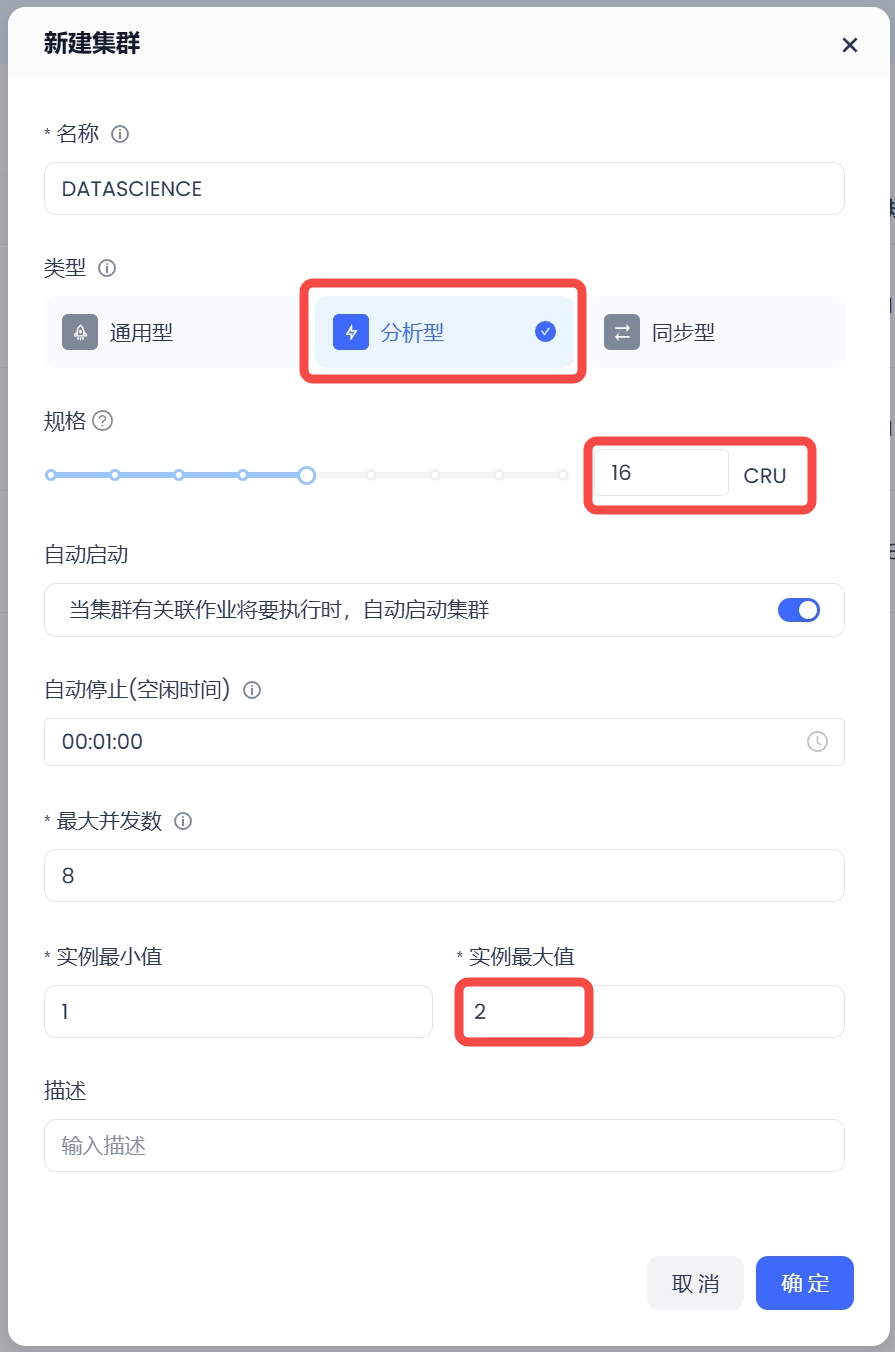
1. 创建一个大规格的分析型计算集群,如16 CRU,提升计算并行度,缩短查询时间。实例最小值1,实例最大值2,以控制成本。
2. 分析阶段可关闭自动停止或将自动停止时间设置成30分钟以上,保留缓存,以在反复查询时大幅提升速度。如需主动将常用表预加载到集群缓存,参考计算集群缓存。
3. 分析结束后手动停止或重新缩短自动暂停时长至1分钟,以节约成本。
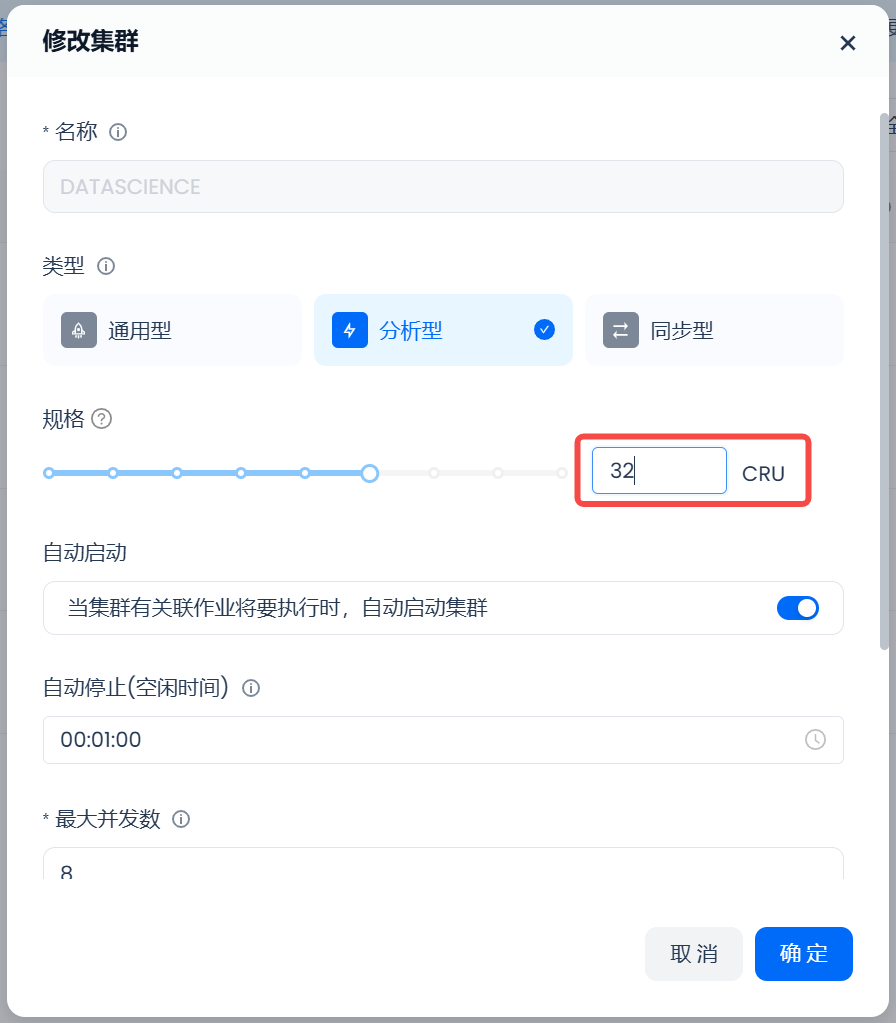
4. 若使用中发现性能不足,可随时“手动调整”计算规格,以获得更好的查询性能。
效果:
- 大规格的分析型计算集群,对大批量、复杂SQL的处理更快,分析周期更短。
- 无需一直占用大规格资源,可随时手动调整集群规格和自动启停时间,而不影响正在进行的分析作业。
场景 4:多任务隔离
:-: 需求:同一部门里既有周期性ELT任务,也有Ad-Hoc分析,还有在线报表请求,希望相互之间资源不互抢、资源不浪费。
解决方案:
- 创建多个集群:
- ETL专用集群:使用通用型计算集群,根据业务使用需要,配置符合作业SLA预期的规格,自动暂停时间较短,以便作业执行完成后及时关闭集群,降低费用。可以创建多个ETL专用集群,将拥有不同SLA保障需求的ETL任务分配到不同的集群上执行,避免多个ETL任务在同一集群内争抢资源,影响重要任务的SLA。
- 在线报表集群:使用分析型计算集群,启用多实例模式,使计算集群可随并发数增减而自动扩缩容,并适当延长自动停止的时间,以利用缓存提高响应速度,提供稳定的在线服务。
- Ad-Hoc 分析集群:使用分析型计算集群,配置较大规格,为复杂查询提供更好的查询性能。根据实际查询需要,在使用过程中手动调整集群规格。配置较长的自动停止时间,以保留缓存,进一步提升查询性能。
- 为不同的调度任务、分析查询、在线报表配置各自专用的集群,隔离不同任务的负载。
效果:
- 工作负载之间互不干扰,同时实现资源利用最大化。
- 不同场景的SLA都能得到保障,避免“一个大作业拖慢其他全部查询”或“在线查询挤占离线任务”的情况。