
数据表
云器 Lakehouse 的数据表是存储和处理数据的核心对象。普通表、动态表采用 Parquet 列式存储,查询时只读取需要的列,适合大规模分析型查询;与 MySQL 等行式数据库不同,写入时自动按列组织并压缩,大幅减少 I/O。与 Hive 的静态分区不同,Lakehouse 采用类似 Iceberg 的隐藏分区机制,分区策略可以在不影响数据的情况下修改。
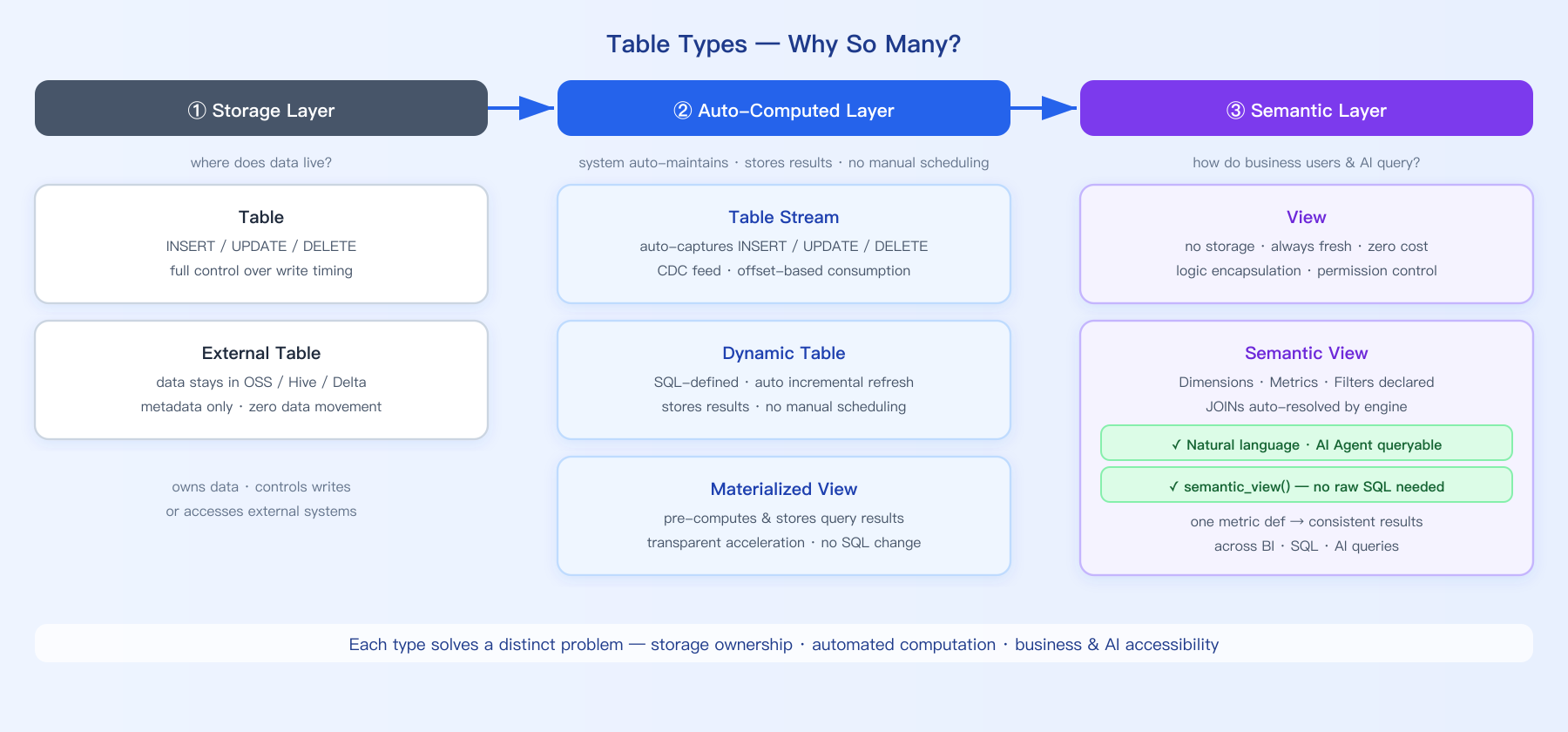
表类型选型
| 表类型 | 数据维护方式 | 适用场景 |
|---|---|---|
| 普通表 | 手动 INSERT/UPDATE/DELETE | ODS 原始数据、维度表、CDC 同步目标表 |
| Dynamic Table | 自动增量刷新 | DWD/DWS/ADS 层、基于查询自动计算结果 |
| 视图 | 无数据存储,查询时动态计算 | 逻辑封装、简化复杂查询 |
| 物化视图 | 自动刷新,预计算存储结果 | 透明查询加速、单表查询优化 |
| 外部表 | 数据在外部系统,Lakehouse 管理元数据 | 联邦查询、数据湖访问 |
| 语义视图 | 封装业务语义,支持自然语言查询 | AI 对话式分析、业务指标统一口径 |
何时使用哪种表?
第一步:数据从哪里来?
- 外部数据源同步(MySQL/PostgreSQL/Kafka)→ 同步任务写入普通表
- 文件导入(CSV/Parquet/JSON)→ COPY INTO 写入普通表
- SQL 查询结果 → Dynamic Table(自动刷新)或视图(不存储)
第二步:数据怎么用?
| 场景 | 推荐 | 原因 |
|---|---|---|
| ODS 层原始数据 | 普通表 | 需要精确控制写入时机 |
| DWD 层清洗后数据 | Dynamic Table | 基于 ODS 自动增量计算,无需调度 |
| DWS 层指标汇总 | Dynamic Table | 基于 DWD 自动聚合 |
| 频繁查询的中间结果 | 物化视图 | 透明加速,用户无需改 SQL |
| 简化复杂查询 | 视图 | 不存储数据,零成本 |
| AI 对话式分析 | 语义视图 | 封装业务语义 |
| 外部数据联邦查询 | 外部表 | 数据不迁入 Lakehouse |
存储格式
Lakehouse 的表默认使用 Parquet 列式存储格式:
- 高效压缩:同类型数据连续存储,压缩比高
- 查询优化:只读取查询所需的列,减少 I/O
- Schema 演进:支持添加列、修改列类型等变更
分区与分桶
- 分区:类似 Iceberg 隐藏分区,支持转换分区(years/months/days/hours),分区策略可在不影响数据的情况下修改
- 分桶:CLUSTER BY 通过哈希分桶优化 Join 和聚合操作
成本影响速查
| 操作 | 存储影响 | 计算影响 |
|---|---|---|
| 创建表 | 仅元数据,几乎零成本 | 无 |
| 写入数据 | 按 Parquet 压缩后数据量计费 | 消耗 VCluster CRU |
| 开启 Time Travel | 保留历史版本,增加存储 | 无 |
| 创建分区 | 不增加额外存储 | 查询时减少扫描量 |
| 创建索引 | 索引数据占用额外存储 | 查询时加速,减少 CRU |
相关文档
联系我们