
Dify中配置云器 Lakehouse作为向量数据库
概述
云器 Lakehouse是一个统一的数据湖仓平台,支持向量数据存储和高性能搜索。本指南将帮助你在Dify中配置云器作为向量数据库,替代默认的向量数据库选项,并同时支持全文检索和向量检索的知识库管理。
前置条件
1. 系统要求
- Dify V1.7.2+平台已部署
- 可访问的云器 Lakehouse实例
2. 必需的连接信息
在开始配置之前,请确保你有以下云器 Lakehouse连接信息,并提前创建好对应的
vcluster和schema| 参数 | 说明 | 示例 |
|---|---|---|
| Clickzetta用户名 | |
| Clickzetta密码 | |
| Clickzetta实例ID | |
| 服务端点 | |
| 工作空间名称 | |
| 虚拟集群名称 | |
| 数据库模式 | |
Dify配置文件设置
如果使用配置文件方式,请在Dify配置文件(.env)中添加:
验证配置
1. 连接测试
启动Dify后,可以通过以下方式验证云器连接:
-
查看日志:
-
创建知识库测试:
- 登录Dify管理界面
- 创建新的知识库
- 上传测试文档
- 观察是否成功创建向量索引
2. 功能验证
在Dify中验证以下功能:
- ✅ 知识库创建:能否成功创建知识库
- ✅ 文档上传:能否上传和处理文档
- ✅ 向量化存储:文档是否被正确向量化并存储
- ✅ 相似度搜索:搜索功能是否正常工作
- ✅ 问答功能:基于知识库的问答是否准确
使用指南
1. 知识库管理
创建知识库
- 登录Dify管理界面
- 点击「知识库」→「创建知识库」
- 填写知识库名称和描述
- 选择嵌入模型(推荐使用支持中文的模型)
- 点击「保存并处理」
上传文档
- 在知识库中点击「上传文档」
- 选择支持的文件格式(PDF、Word、TXT等)
- 配置文档分块规则
- 点击「保存并处理」
- 等待文档处理完成
备注:在Dify里配置unstructured.io作为ETL引擎可以支持PPT等更多格式文件。
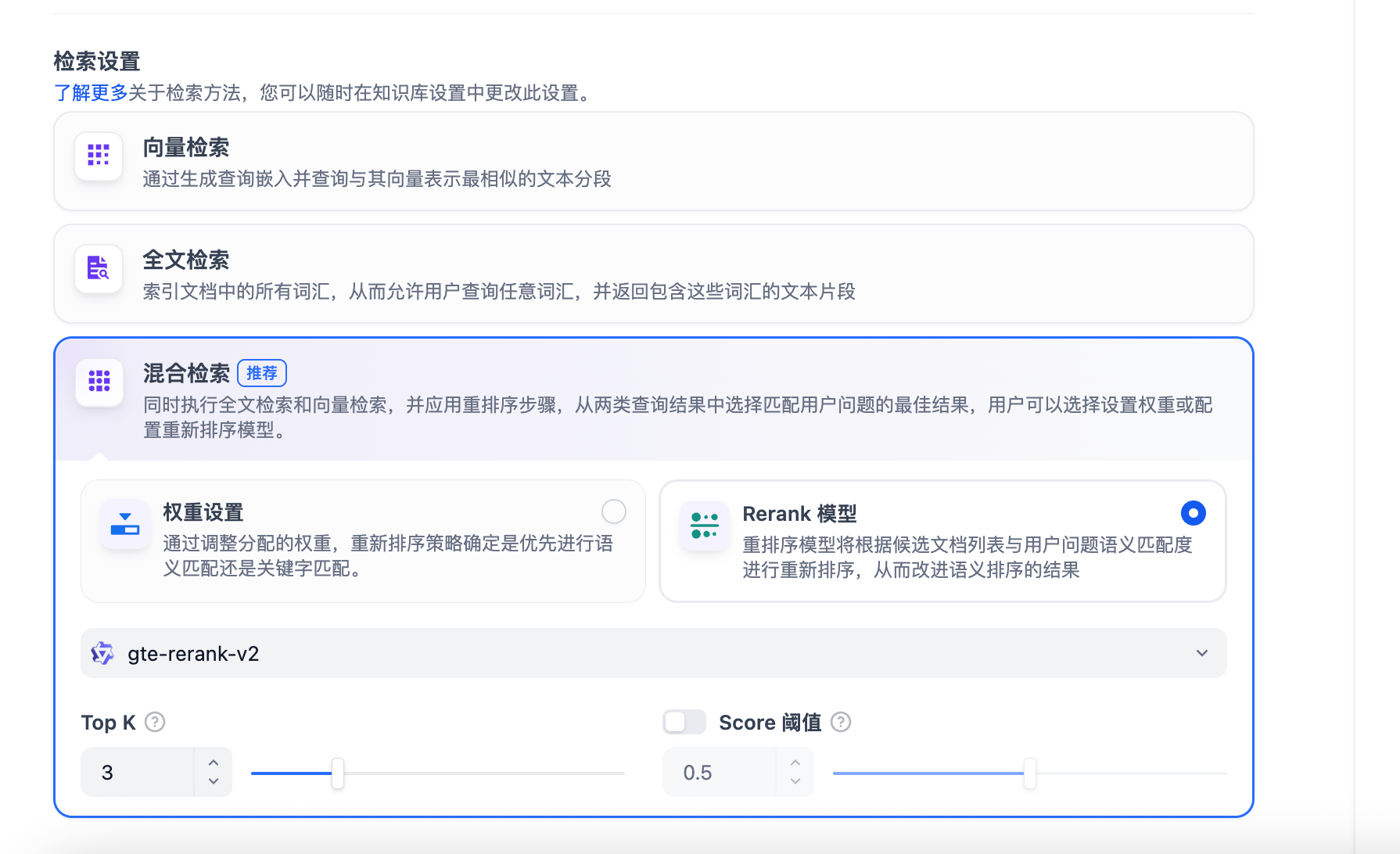
云器Lakehouse支持基于倒排索引和向量索引的混合检索方式:
管理向量数据
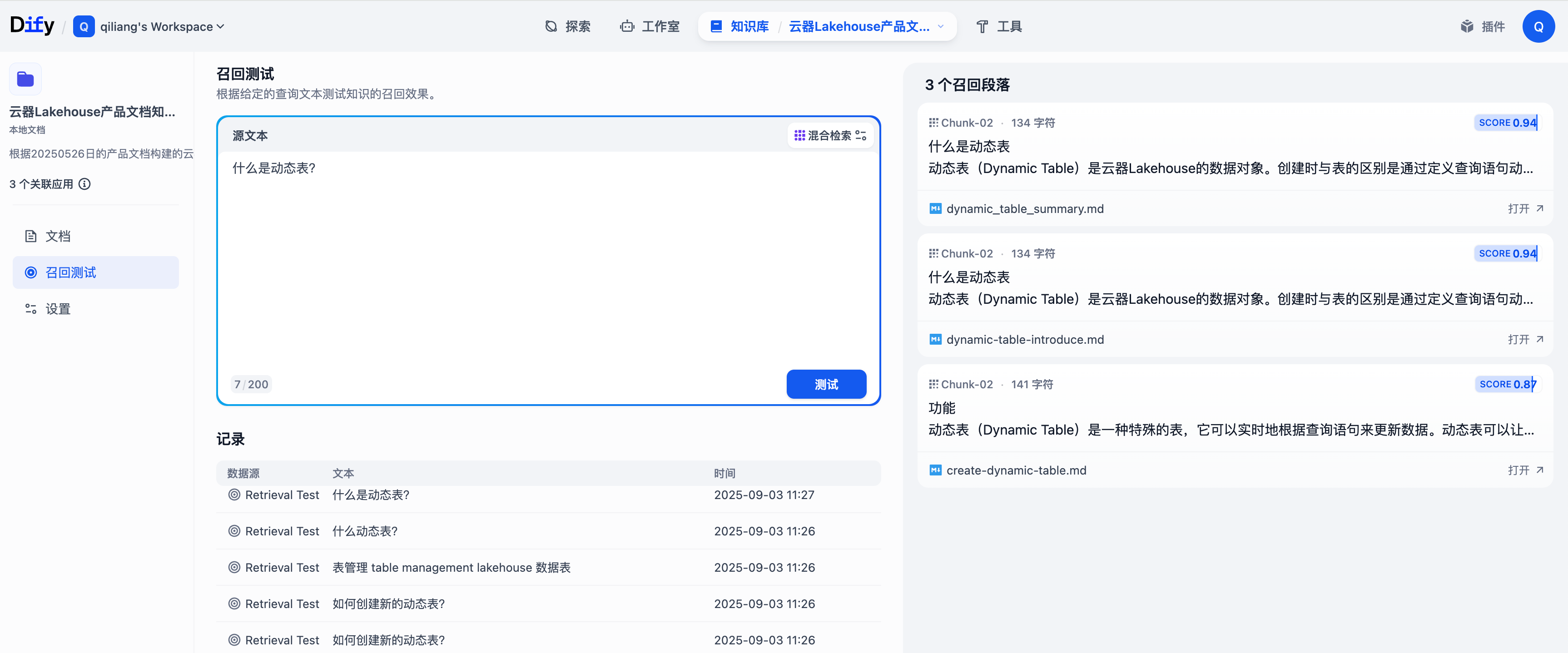
- 查看统计:在知识库详情页查看向量数量和存储统计
- 更新文档:可以更新或删除已上传的文档
- 搜索测试:使用搜索功能测试向量检索效果
2. 应用开发
在聊天应用中使用
- 创建新的聊天应用
-
在「提示词编排」中关联知识库
-
配置检索设置:
- TopK值:建议3-5
- 相似度阈值:建议0.3-0.7
- 重排序:可选启用
-
测试问答效果
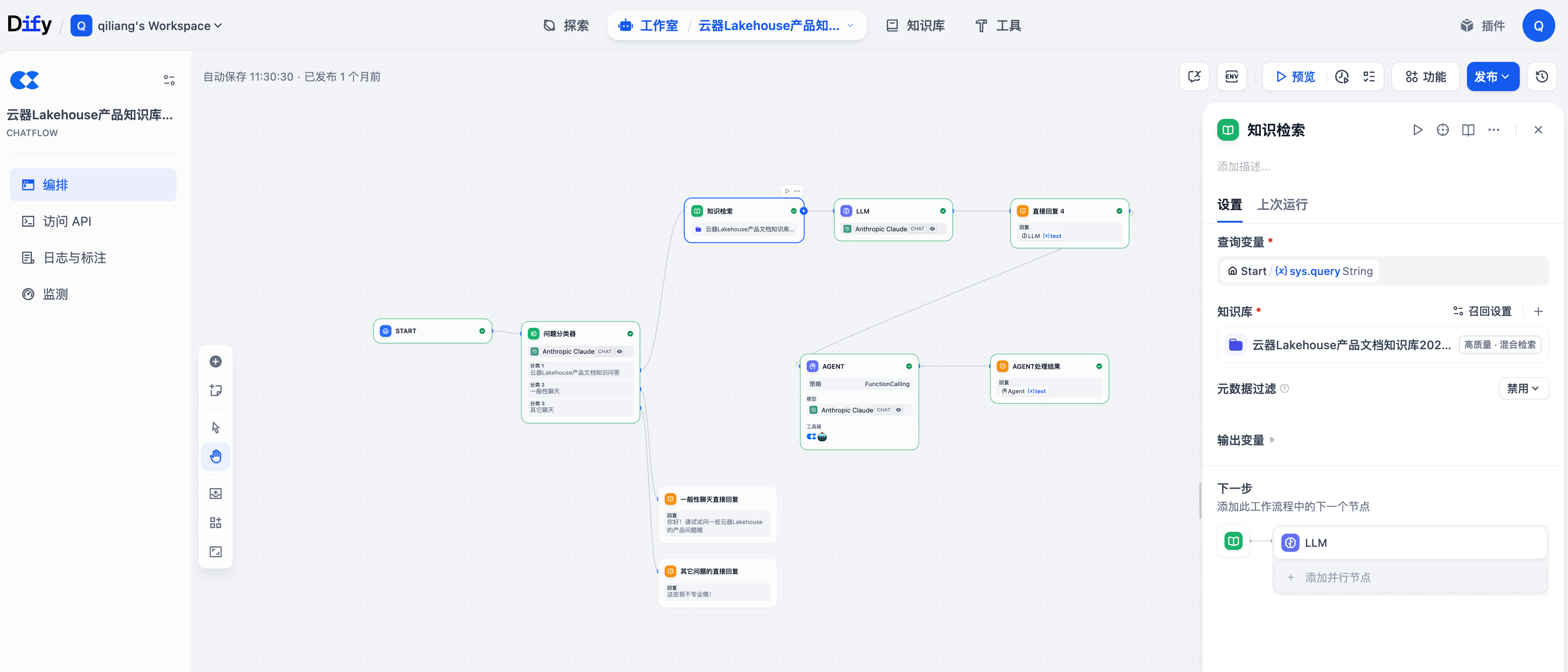
在工作流中使用
-
创建工作流应用
-
添加「知识检索」节点
-
配置检索参数:
- 查询变量:
{{sys.query}} - 知识库:选择目标知识库
- 检索设置:TopK和相似度阈值
- 查询变量:
-
将检索结果传递给LLM节点
性能优化
1. 向量索引优化
云器Lakehouse自动为向量字段创建HNSW索引,你可以通过以下方式优化:
在配置中调整索引参数:
或:
2. 批处理优化
调整批处理大小:
3. 全文搜索优化
启用倒排索引以支持全文搜索:
监控和维护
1. 性能监控
监控以下关键指标:
- 连接状态:数据库连接是否正常
- 查询延迟:向量搜索响应时间
- 吞吐量:每秒处理的向量查询数
- 存储使用:向量数据存储空间使用情况
2. 日志分析
关注以下日志信息:
连接日志:
向量操作日志:
错误日志:
3. 数据备份
定期备份重要的向量数据:
故障排除
常见问题
Q1: 连接失败
症状: Dify启动时报Clickzetta连接错误 解决方案:
- 检查网络连接
- 验证用户名和密码
- 确认实例ID正确
- 检查防火墙设置
Q2: 向量搜索性能差
症状: 搜索响应时间过长 解决方案:
- 检查是否创建了向量索引
- 调整TopK值
- 优化查询条件
- 考虑增加计算资源
Q3: 文档处理失败
症状: 文档上传后处理失败 解决方案:
- 检查文档格式是否支持
- 验证文档大小限制
- 查看详细错误日志
- 检查向量化模型状态
Q4: 中文搜索效果差
症状: 中文文档搜索结果不准确 解决方案:
- 启用中文分词器
- 调整相似度阈值
- 使用支持中文的嵌入模型
- 检查文档分块设置
有用的资源
- Dify官方文档: https://docs.dify.ai
- 云器文档: https://yunqi.tech/documents
- GitHub Issues: https://github.com/langgenius/dify/issues
- 社区论坛: https://community.dify.ai
*本指南基于Dify V1.7.2+ 和 云器 Lakehouse SaaS版本
联系我们