
从需求到语义层:DataAgent 指标口径管理最佳实践
指标平台为什么总是"建了也没用"
某次复盘,三个团队各自做了一版"复购率"看板,数字却对不上。排查到最后,问题不在 SQL 写错,而在一个谁都没说清的口径分歧:有人按"每个订单一个 id"统计,有人按"同一个真实的人"统计,还有一版混用了两者。三段 SQL 各自都"正确",但口径散落在各自的查询里,谁都没把它收住——同一个词、三个含义、三张看板。
这不是个例,而是企业用指标平台普遍会撞上的困境。把指标的一生拆开看,痛点分布在五个地方:
- 建设重、存量收编无解。 搭一个像样的指标平台/语义层本身就是个大工程——建模、定实体、配口径、连 join,架构师牵头跑几个月。更要命的是企业不是绿地:手里早有几千个散落在 BI、SQL、Excel 里的指标,平台是空的,靠人工一个个搬,永远追不上业务新增的速度。平台从第一天起就是"不全"的。
- 录入靠人工,规范靠自觉。 在主流平台里,"定义一个指标"和"把它登记进平台"是两个动作——人想起来才登记,想不起来就直接写 SQL 绕过去。规范只是一份挂在 Wiki 上的治理文档,靠自觉的规范等于没有规范,新人照样自己发挥。于是平台里只有"官方指标",长尾全在外面野生,口径孤岛、重复定义。
- 消费端各自重算,两套东西漂移。 就算指标进了平台,BI、Notebook、Ad-hoc SQL 依然各自重算一遍口径,"单一事实源"在消费层根本没落地。同时物理层一直在变,平台里的语义定义是事后贴的翻译层,两套东西永远在漂移,你日常工作的本质就是维护这俩对齐。
- 变更时血缘事后猜,改一处不知波及谁。 多数平台的血缘是事后用解析器去猜 SQL 得来的,既不全也滞后。上游字段一改,你根本不知道哪些指标、哪些看板会崩,只能改完跑错了被动救火。"改一个口径"于是变成全局 grep、各团队约谈、出事再补的高危操作——这是"指标治理贵"里最大的一块。
- AI 时代没有可靠口径锚点,Agent 只能猜。** NL2SQL / 数据 Agent 要可靠工作,必须有一个机器可读、唯一的口径源去锚定。而现状是口径仍散落、平台仍不全,Agent 没有锚点,只能现场猜口径——猜对是运气,猜错是事故。
以上问题的核心本质在于**,指标平台被当成了"数据建完之后追着物理层跑的下游翻译层",而不是业务意图进来的第一站。** 所以它天生不全(录入靠自觉)、天生漂移(两套对齐)、天生瞎(血缘事后猜)。
使用Data Agent,就可以做到把语义层从"事后翻译"挪到"治理源头"。
DataAgent :从源头治理,让指标需求与 Semantic View 全程联动

DataAgent 的思路一句话就能说清:让"提需求"这个动作,在源头就把口径、文档、实现、血缘锁成一体;之后任何一端发生变更,其余各端自动跟着动。 拆成三步看。
第一步——源头治理:提需求即建语义,口径当场被规范。 业务方提出需求,DataAgent 不急着写 SQL,而是先按一套统一的口径模板(口径、计算逻辑、数据源、统计粒度,一项都不能少)做推断,并把藏着的歧义翻出来让人确认——比如复购率里
customer_idcustomer_unique_id这就是"从源头治理"的含义——规范不是事后追着补的债,而是在入口处被流程强制掉的。指标根本没机会以"不规范"的状态进入系统。
第二步——全程联动:之后每一个指标需求,都挂在 Semantic View 上。 不是每个需求各写各的 SQL、各建各的口径。新指标复用同一批已声明的实体、join 关系和口径,全部沉淀进同一个语义层。需求文档与 Semantic View 是一一对应、双向绑定的——文档不再是死在 Wiki 里的旁注,它就是语义层本身的可读视图。于是"文档说 A、线上算 B"这种漂移,从结构上就不可能发生了。
第三步——双向变更联动:这是它真正解决"难管"的地方。 有了一个绑定的、声明式的源头,前面两个最失控的变更场景,变成了两个可控的方向:
- 正向 · 业务口径变更,自动下发。 "复购窗口从 30 天改成 60 天",改的只是 Semantic View 这一个源头。所有引用它的看板、下游报表、乃至 Agent 的自然语言查询,都自动用上新口径,不需要人去全局搜一遍、再一个个改。口径变更能及时、完整地更新,不会漏、不会出现新旧口径并存。
- 反向 · ETL 链路变更,反查影响。 某张中间表重构、某个字段含义变了——因为血缘是生成时声明的、机器可读,系统能顺着血缘反向推导:这次改动会波及哪些指标口径?于是它在你动手改之前就列出影响清单、给出预警,而不是等下游指标算错、业务来投诉了才回头排查。改前知道波及谁,把出错挡在上线之前。
正向能自动下发、反向能反查影响——两个方向都打通了,指标需求才算第一次真正被"管"住,而不是被一堆对不上的文档和救不完的火追着跑。
实践案例:用 巴西电商数据,五步走完一条指标的"出生到变更"
我们使用巴西电商公开数据集 Olist,包含订单(orders)、商品(order_items)、客户(customers)、支付(payments)、评价(reviews)几张核心表。
第一步:将业务需求整理成标准的指标需求文档
业务方提出需求:我现在要做个订单销售额GMV的分析报表。你帮我分析一下我能做哪些指标,给我一个指标需求说明
DataAgent不急着写 SQL,而是按统一模板(口径 / 计算逻辑 / 数据源 / 统计粒度,一项不能少)输出一份指标需求说明:
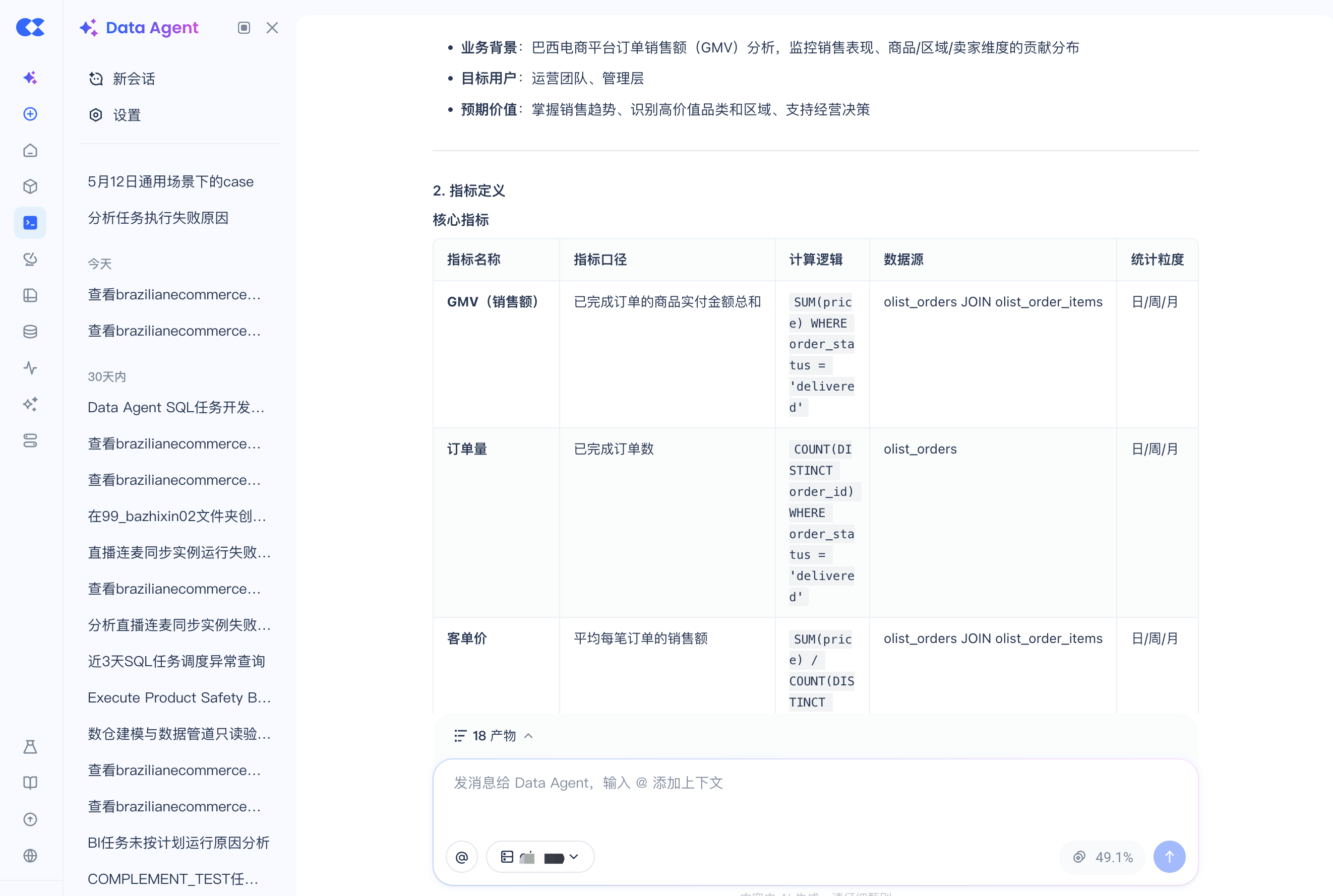
第二步:基于指标需求文档,创建对应的 Semantic View
需求文档确认完,不是归档了事,而是立刻落成 Lakehouse 里一条与之一一对应的 Semantic View——entity、join_path、dimension、metric 一次成形,血缘在这一刻被声明(注意:是"声明",不是事后解析,这一点是后面第五步反查影响的前提)。
继续向agent提出:帮我把这些指标这个保存成一个semantic view,命名为sv_gmv_analysis
DataAgent 据此生成 Semantic View:

到这里,这套 GMV 指标有了唯一的、机器可读的定义。需求文档与
sv_gmv_analysis第三步:口径变更,改一处、全局生效(正向联动)
指标需求从来不是定一次就完。业务方某天说:
传统方式下,这是个高危操作:得全局 grep 所有用到复购率的 SQL 和看板,一个个改,漏掉一个就出现新旧口径并存、数字对不上。
在这套实践里,改的只是 Semantic View 这一个源头。
1) 先提更新需求,让 Agent 给出口径说明。 Agent 不直接动手,而是先把"退货怎么识别"讲清楚——这又是一次"推断 + 确认":
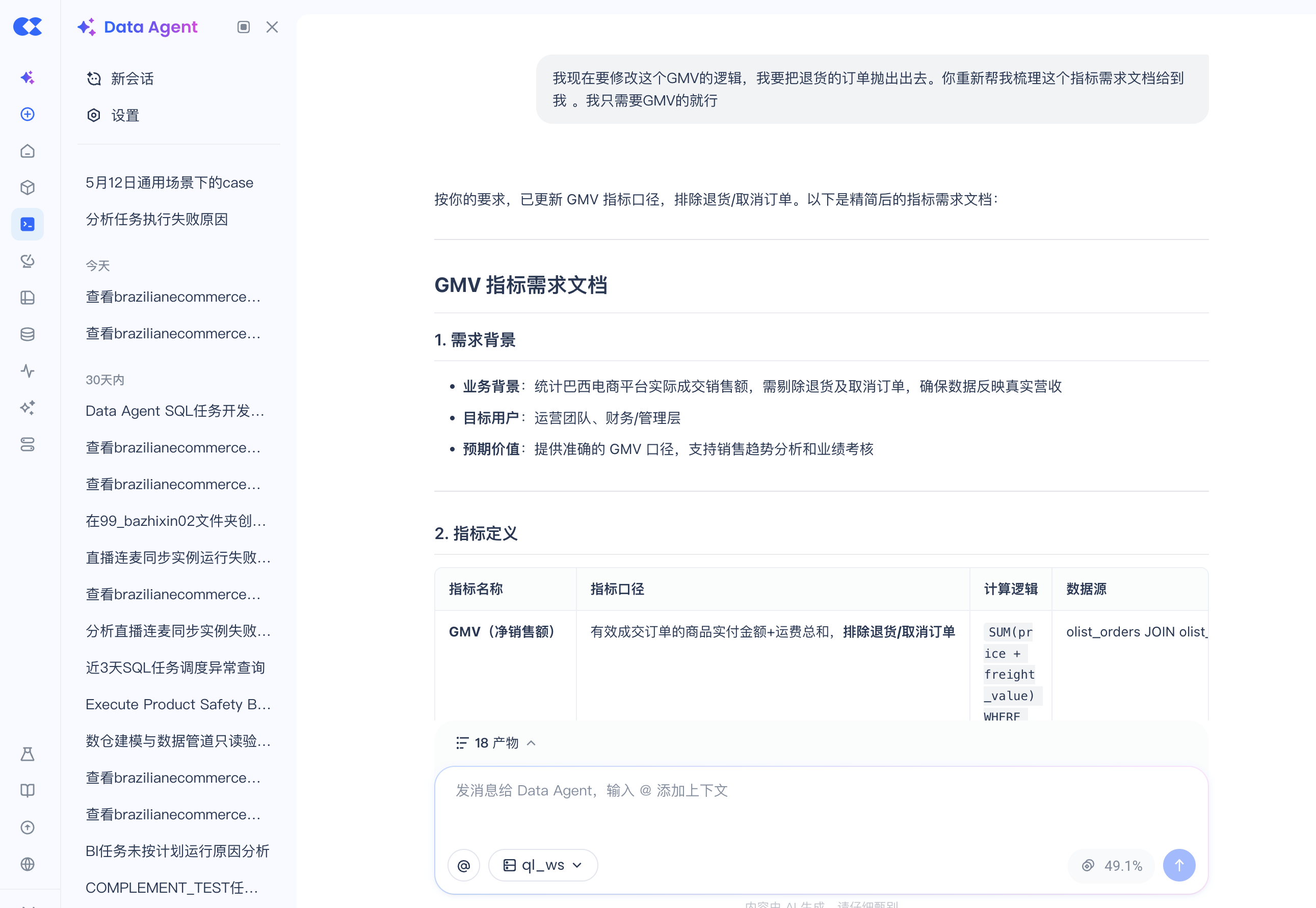
2) 确认后,更新对应的 Semantic View,做到约束统一。 改的是
sv_gmv_analysisgmv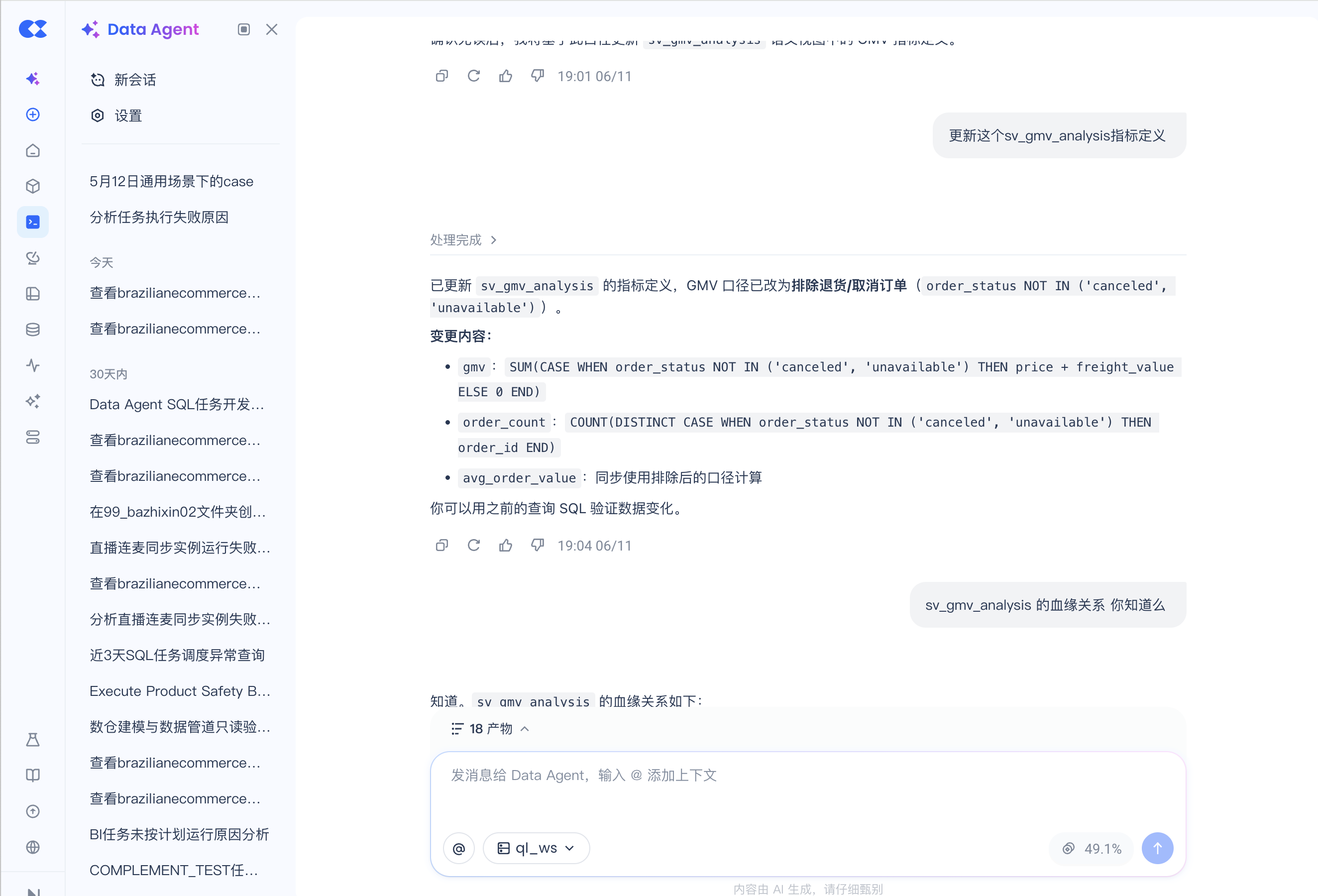
改完之后:所有引用 GMV 的看板、下游报表自动用上新口径;DataAgent 的自然语言查询(用户问"GMV 多少")也自动走新口径;不需要任何人去全局搜一遍、再逐个改。口径变更及时、完整地下发,不漏改、不并存——这就是"正向联动":源头一变,所有消费端跟着变。
第四步:ETL 链路变动前,反查会影响哪些指标(反向联动)
最后一类、也是最贵的变更:数据工程师要动物理层(某张表重构、某个字段含义变了)。在动手之前,他需要知道:这一改,会连累哪些指标口径?
用户只需问一句:
因为血缘是在第二步生成时声明的、机器可读,DataAgent 能两个方向都摊给你看:
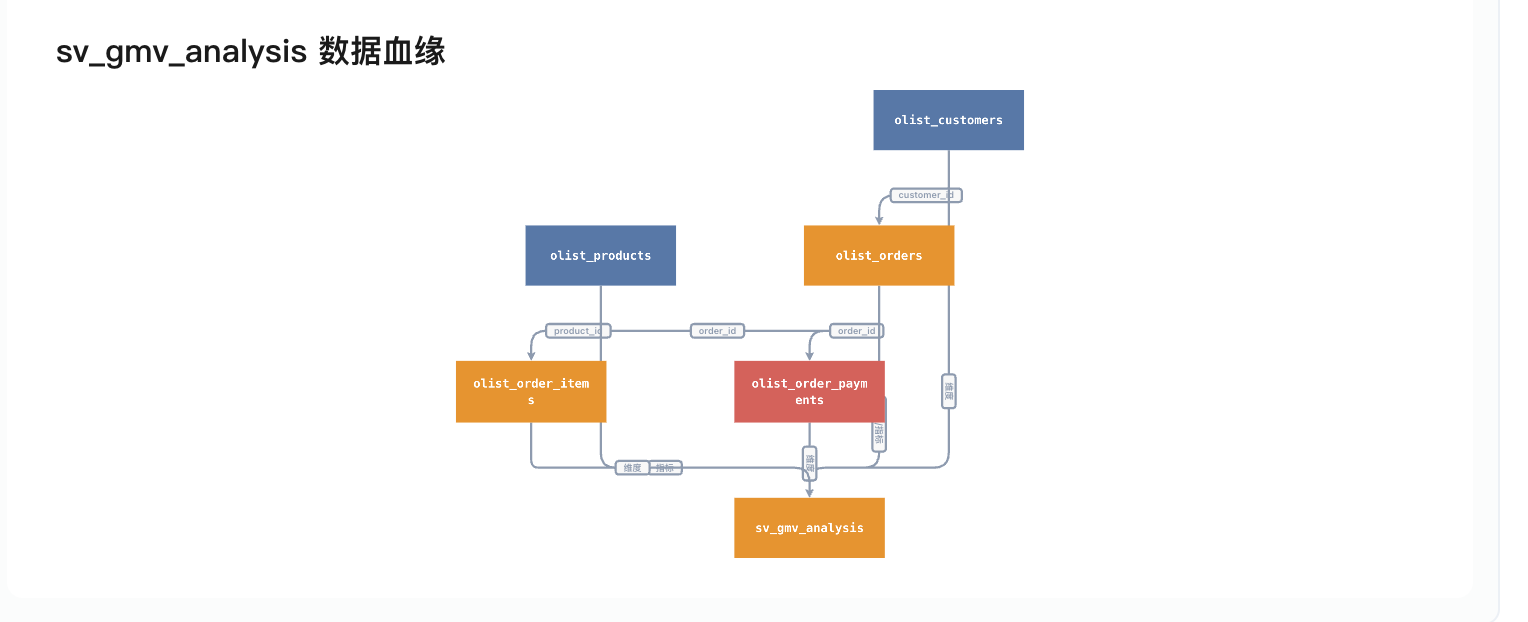
{kind=link}
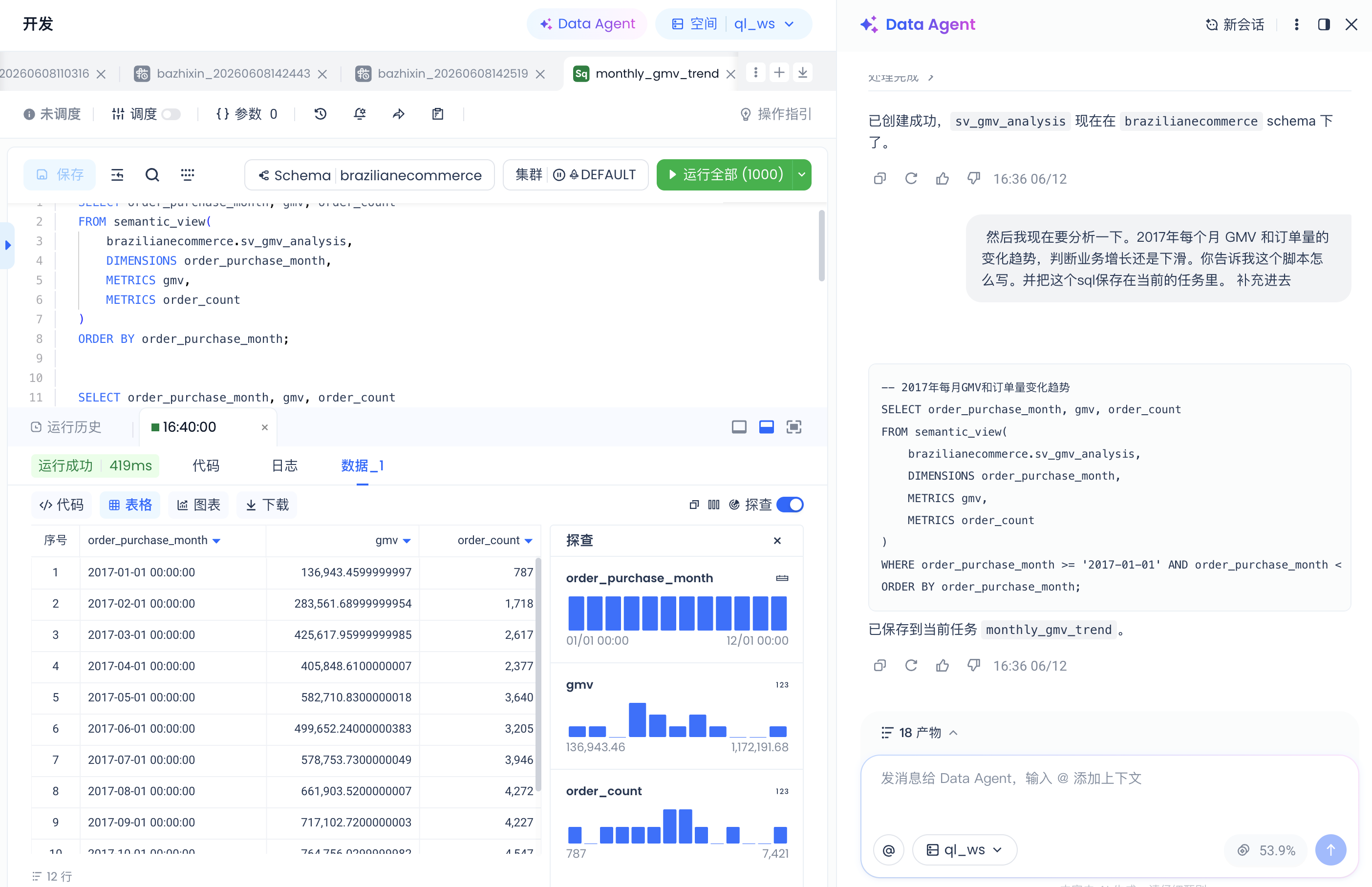
第五步:使用Semantic View进行分析
前四步把语义层建好、管好了。最后回到它的初衷——让分析这件事,只剩"问问题"本身。
分析师不用再关心 GMV 是哪几张表 join、有效订单怎么筛、月份怎么截——这些口径都已经焊死在
sv_gmv_analysis:-: 它只管"取哪几个指标、按什么维度切",不再重写一遍"什么算有效订单、GMV 怎么加"。对照不走语义层时每个分析师都要重写一遍的裸 SQL,口径分歧(有效订单、GMV 口径)就藏在那一堆 join 和 where 里——而现在,口径只有一个出处。
治理的繁琐,本就不该由人来扛
指标难管,从来不是因为指标多,而是因为需求、文档、实现、血缘四样东西各自为政,全靠人去维护它们的同步。
DataAgent 做的,是把指标需求和 Semantic View 锁成一体:提需求即建语义,口径变更自动下发到所有消费端,物理链路一动就反查出受影响的指标——同步不再是一项日常工作,而是系统的天然结果。
于是数据治理那些最繁琐的部分——对齐口径、追查血缘、防止漂移——被从根上消掉了。剩下的,是一个会自己生长、自己收口、自己预警的语义层,和一支终于不用再救火的数据团队。