
Analytics Agent 问答准确率提升最佳实践
回应大家最关心的问题:有哪些提升问答准确率的手段?什么场景适合什么方式?如何管理?
零、从架构上减少干扰:划分分析域
提升准确率最有效的第一步,不是调参,而是缩小模型的"选择空间"。当所有业务线的数据表都堆在一起时,模型每次回答都要从几十甚至上百张表里猜哪张是对的——干扰越多,选错的概率越高。
分析域让你把数据按业务主题拆开:销售一个域、人力资源一个域、供应链一个域。每个域只包含相关的表、指标和知识,用户在哪个域里问问题,模型就只在那个域的范围内思考,准确率自然提高。同时域可以绑定用户,天然实现数据隔离——不同部门的人只能看到自己域内的数据。
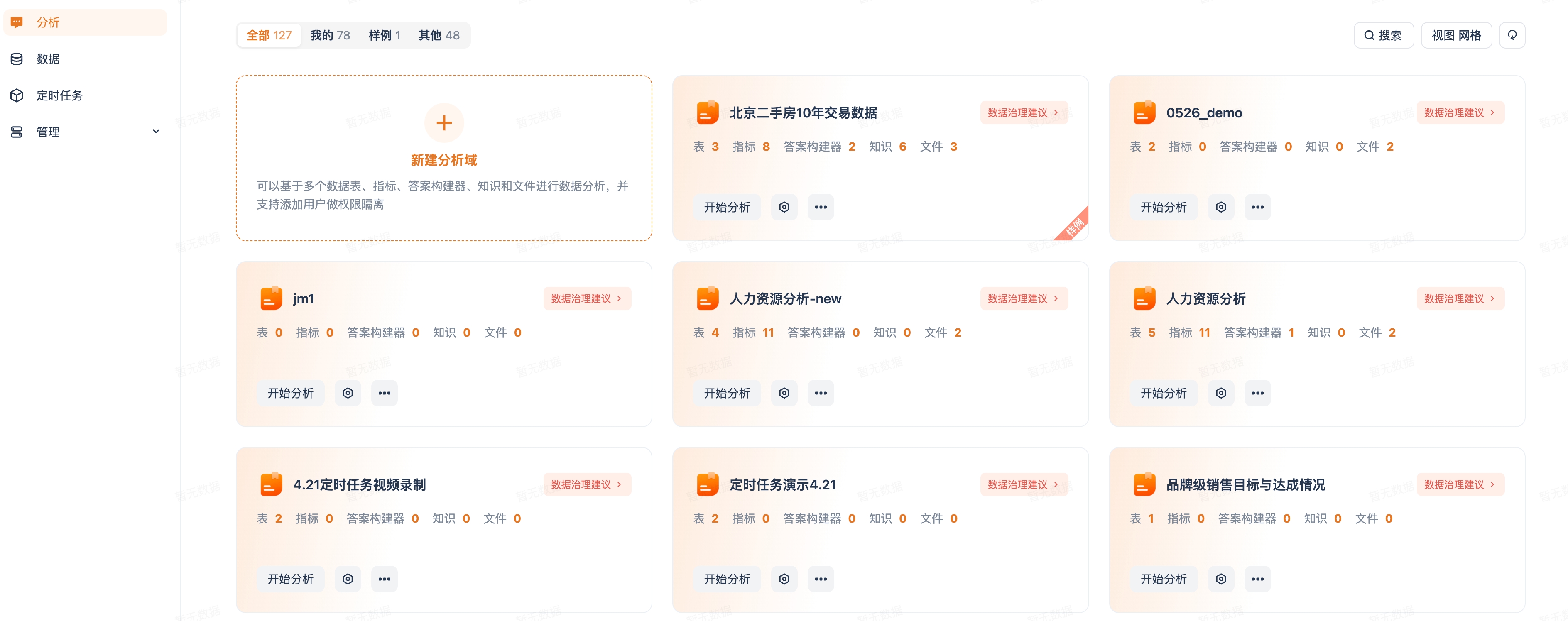
在分析页面可以看到所有分析域,每个域显示它包含的表、指标、答案构建器和知识数量。点击新建分析域创建,创建后在域设置里关联数据表和用户。
一、有哪些能力提升准确率?
Data Analytics Agent (DataGPT)提供 4 种核心能力来给模型更多业务信息输入,提高回答准确率:
1. 表列 Schema 说明

| 配置项 | 作用 | 示例 |
|---|---|---|
| 表描述 | 告诉模型这张表是什么 | "香港地区所有门店的每日经营流水数据" |
| 列别名(Alias) | 让模型理解同一字段的不同叫法 | 列名 rev_amt → 别名"营业额"、"收入" |
| 列描述(Description) | 解释列的业务含义和取值规则 | "payment_type: 支付方式,取值包括 cash/card/octopus" |
| 隐藏列 | 当数据表字段较多时,部分列对业务分析无意义(如系统主键、ETL 时间戳、内部编码等),开启隐藏后该列不会参与 AI 问答与分析,减少模型选错列的概率 | 适用场景: 表中有大量技术字段,干扰模型选列判断;或某些敏感字段不希望被AI引用 |
| 虚拟列 | 当变更schema需要AI适配理解时,不改动底层数据表,通过SQL表达式创建虚拟列即可 | 使用场景:原始字段需加工后方便AI理解业务含义 |
2. 知识(Knowledge Base / 分析文档)
以文件形式提供的业务背景知识,通过 RAG 检索注入对话上下文。
适合放入知识库的内容:
- 业务规则说明
- 数据字典 / 编码对照表
- 行业术语解释
- 分析方法论 / 计算口径说明
- FAQ 常见问答
- 仅在特定场景召回
核心价值:让模型理解"数据背后的业务逻辑",而不仅仅是数据结构。
3. 指标(Metrics)/ 答案构建器
预定义的计算公式,支持别名匹配,确保指标口径统一。其中:
- 指标:用于定义聚合类计算(如 SUM、AVG)
- 答案构建器:用于定义涉及多表 JOIN、复杂过滤条件
| 要素 | 说明 | 截图demo |
|---|---|---|
| 指标名称 | 如"客单价" | 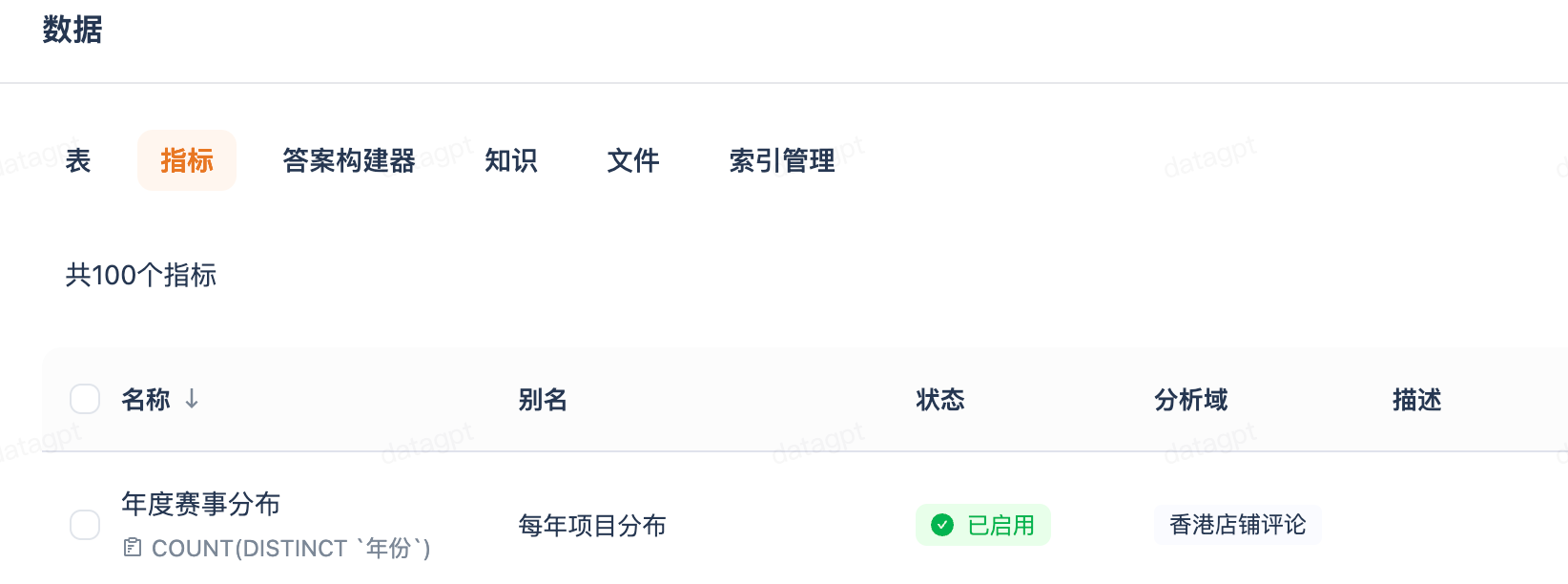 |
| 计算逻辑 | SUM(revenue) / COUNT(DISTINCT order_id) | 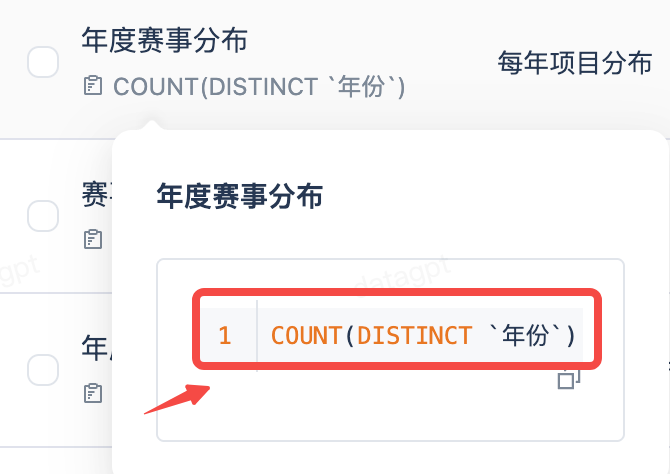 |
| 别名 | 让模型理解同一名词的不同叫法 |  |
| 指标自动生成 | 已支持针对选定数据表自动生成基础聚合指标(如 SUM、COUNT 等),后续将上线上下文感知的指标洞察与自动生成能力,实现更智能的指标推荐 | 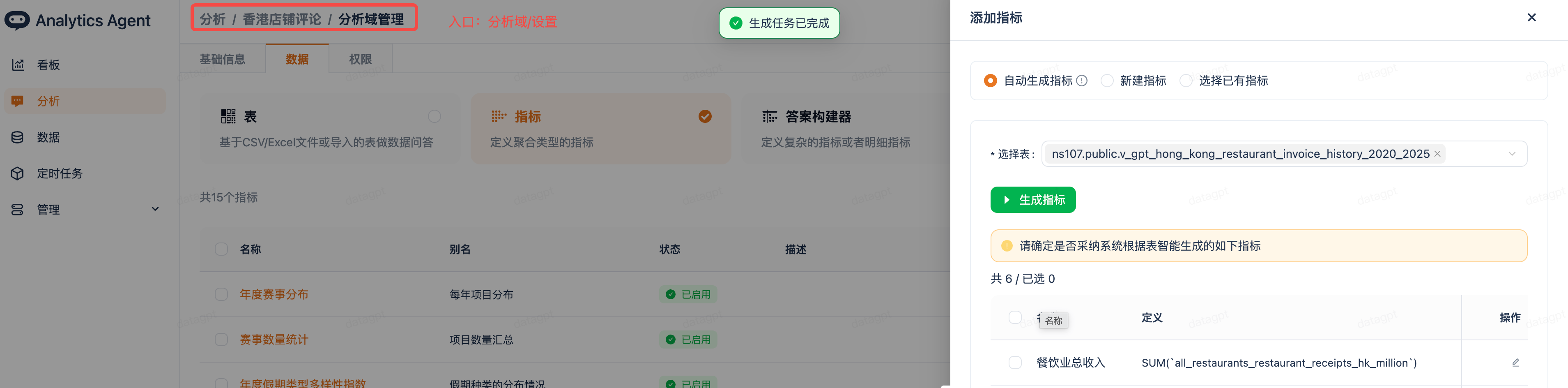 |
核心价值:确保关键业务指标的计算口径统一、准确,不会每次问都生成不同的 SQL
4. 域提示词(Domain Prompt)
分析域级别的系统提示词,相当于给模型一个"角色设定"和"行为规范"。
- 角色设定:"你是一个香港餐饮行业的数据分析师"
- 回答规范:"金额单位默认为港币,日期格式用 YYYY-MM-DD"
- 业务约束:"计算同店增长时,只包含开业满12个月的门店"
- 输出偏好:"趋势类问题优先用折线图展示"
核心价值:设定全局规则,避免每次对话都要重复说明前提条件
二、什么场景用什么能力?(场景 → 能力映射)
| 场景/问题类型 | 推荐能力 | 为什么 |
|---|---|---|
| 数据表很多,模型频繁选错表 | 划分分析域 | 缩小模型的选择范围 |
| 不同团队需要数据隔离 | 划分分析域 | 域绑定用户,天然隔离 |
| 模型选错了表或列 | 表列 Schema 说明 | 描述不清导致匹配错误 |
| 过滤条件的值写错(如用全称但数据存缩写) | 列值索引 | 建立模糊匹配 |
| 计算口径不对(如"毛利"算法错误) | 指标 | 预定义精确公式 |
| 复杂计算逻辑(多表 JOIN + 条件过滤) | 答案构建器(Answer Builder) | 提供 SQL 模板 |
| 模型不理解业务术语(如"翻台率") | 知识库 | 提供术语解释文档 |
| 需要背景知识才能回答(如"为什么3月业绩下降") | 知识库 | 提供业务背景文档 |
| 每次都要重复说明前提条件 | 域提示词 | 一次设定,全局生效 |
| 同一个指标有多种叫法 | 指标别名 / 列别名 | 支持多种表达匹配 |
决策流程图
三、怎么用?(知识库的管理方式)
3.1 知识库的组织结构
新版知识库采用层级文件夹结构(类似飞书知识库):

3.2 内容创建方式
| 方式 | 适用场景 |
|---|---|
| 直接新建 | 手动编写业务规则、术语解释等 |
| 本地上传 | 已有 PDF/Word/Excel/Markdown 文档 |
| 云存储导入 | 从 OSS/S3 批量导入已有文档 |
3.3 关联分析域(关键!)
知识库内容必须关联到分析域后,该域下的对话才能检索到:
- 可以在文件夹级别关联 → 子文件自动继承
- 支持一个文件关联多个分析域
- 未关联的文件不会被任何对话检索到
最佳实践:
- 按业务主题建文件夹,文件夹级别关联分析域
- 通用知识(如公司术语表)关联所有分析域
- 特定业务知识只关联对应域
3.4 什么内容适合放知识库?
✅ 适合放入知识库的内容:
| 内容类型 | 举例 |
|---|---|
| 业务规则 | 翻台率 = 接待桌数 / 总桌数;客单价 = 营业额 / 来客数 |
| 编码对照 | 门店代码 A01 = 铜锣湾店,A02 = 旺角店 |
| 行业术语 | "堂食"、"外卖"、"翻台"、"出餐时间"的定义 |
| 数据口径 | "有效订单"不包含退款订单和测试订单 |
| 分析方法 | 同店增长只统计开业满12个月的门店 |
| 常见 FAQ | "为什么报表数据和财务对不上?" → 因为报表不含税 |
| 背景信息 | 2026年Q1公司做了门店调整,3家新开、2家关闭 |
❌ 不适合放知识库的内容:
| 内容类型 | 应该用什么 |
|---|---|
| 指标的精确计算公式 | → 用「指标」功能 |
| 复杂 SQL 模板 | → 用「回答构建器」 |
| 列的别名和描述 | → 用「Schema 说明」 |
| 全局回答规范 | → 用「域提示词」 |
3.5 管理建议
| 建议 | 说明 |
|---|---|
| 按主题分文件夹 | 便于管理和批量关联分析域 |
| 文档保持简洁 | 每个文件聚焦一个主题,避免大而全 |
| 定期更新 | 业务规则变化时同步更新知识库 |
| 命名规范 | 文件名体现内容,如"翻台率计算规则.md" |
| 先验证再推广 | 添加知识后测试几个问题,确认效果再大范围使用 |
四、总结:4 种能力的协同关系
一句话总结:
- Schema 说明让模型"找对数据"
- 指标让模型"算对数字"
- 知识库让模型"理解业务"
- 域提示词让模型"遵守规范"
四者配合使用,准确率最高。
联系我们