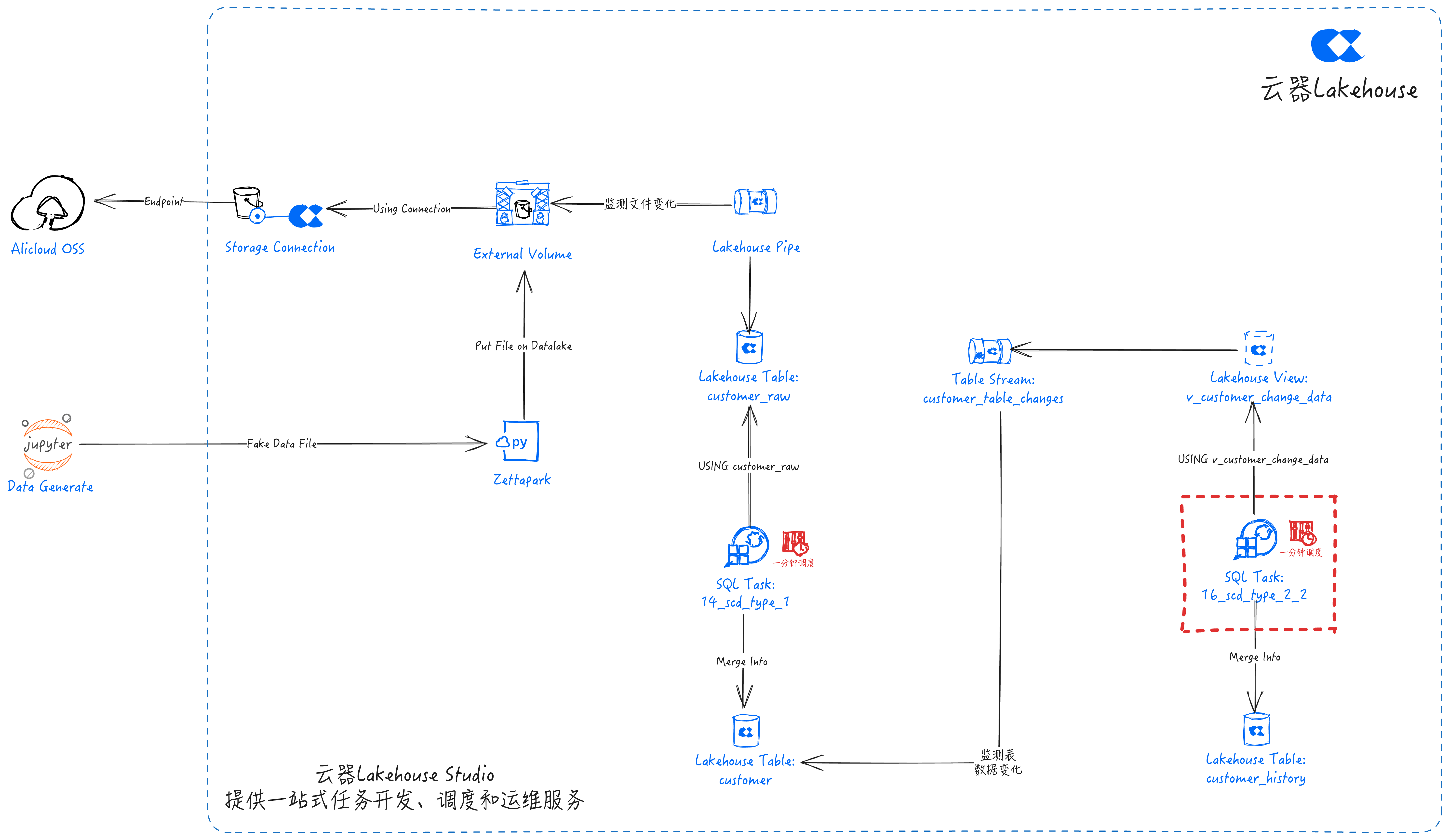
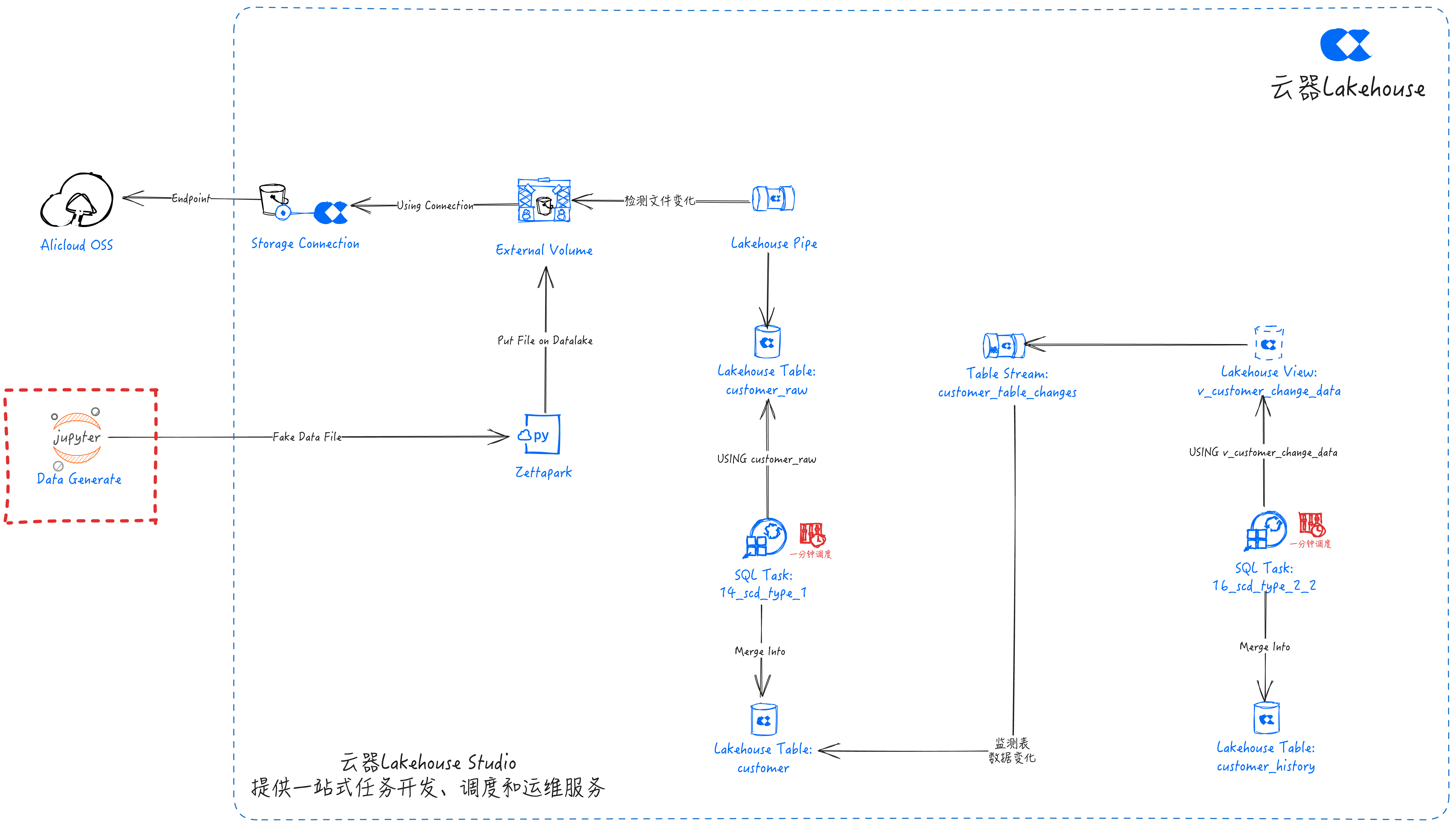
-- Create required virtual cluster and schemas
-- SCD virtual cluster
CREATE VCLUSTER IF NOT EXISTS SCD_VC
VCLUSTER_SIZE = XSMALL
VCLUSTER_TYPE = ANALYTICS
AUTO_SUSPEND_IN_SECOND = 60
AUTO_RESUME = TRUE
COMMENT 'SCD VCLUSTER for test';
-- Use our VCLUSTER
USE VCLUSTER SCD_VC;
-- Create and Use SCHEMA
CREATE SCHEMA IF NOT EXISTS SCD_SCH;
USE SCHEMA SCD_SCH;
USE VCLUSTER SCD_VC;
USE SCHEMA SCD_SCH;
create table if not exists customer (
customer_id string,
first_name varchar,
last_name varchar,
email varchar,
street varchar,
city varchar,
state varchar,
country varchar,
update_timestamp timestamp_ntz default current_timestamp());
create table if not exists customer_history (
customer_id string,
first_name varchar,
last_name varchar,
email varchar,
street varchar,
city varchar,
state varchar,
country varchar,
start_time timestamp_ntz default current_timestamp(),
end_time timestamp_ntz default current_timestamp(),
is_current boolean
);
create table if not exists customer_raw (
customer_id string,
first_name varchar,
last_name varchar,
email varchar,
street varchar,
city varchar,
state varchar,
country varchar);
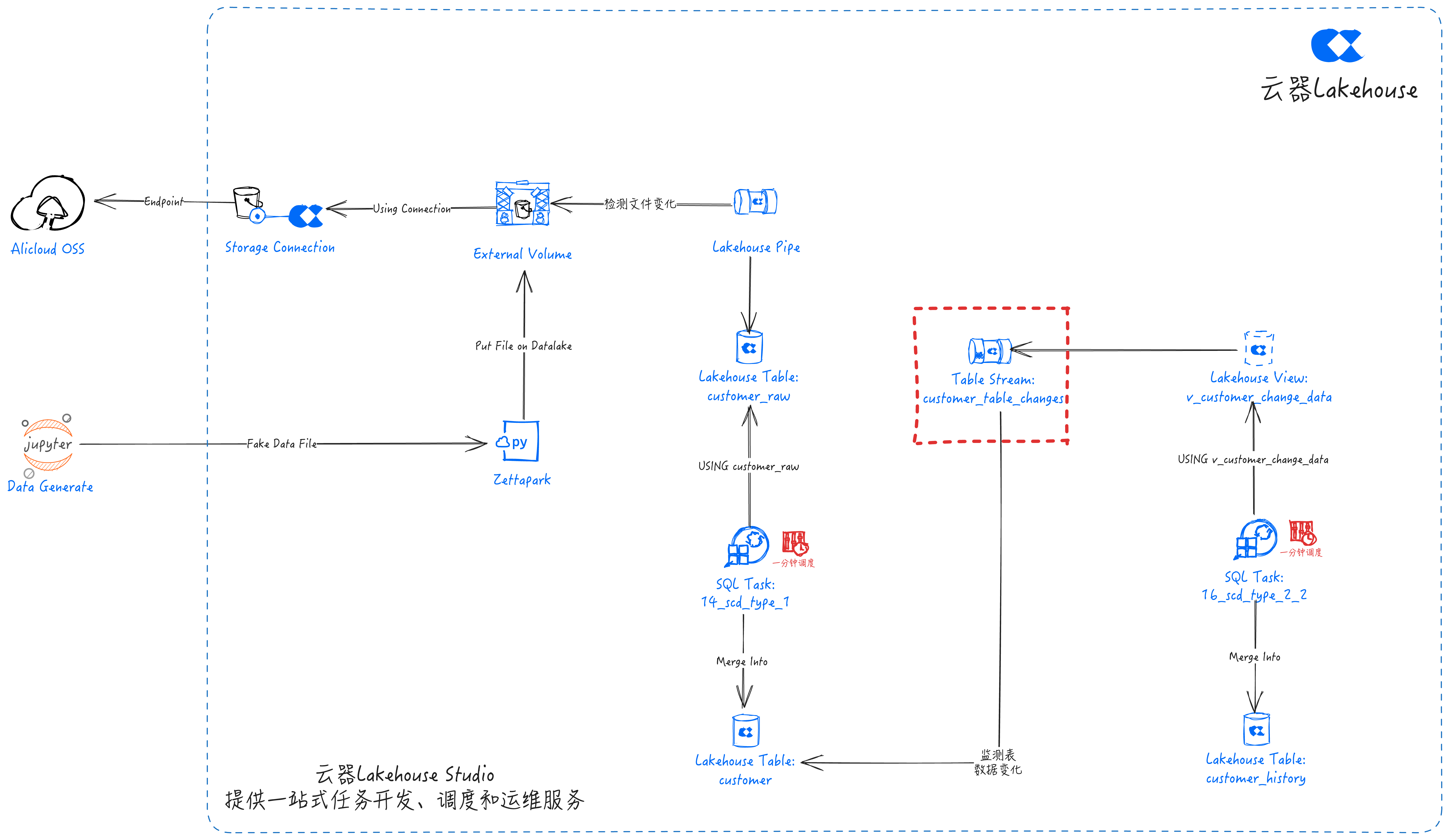
创建流(Stream)
SQL任务:11_stream_creation_for_change_detect
USE VCLUSTER SCD_VC;
USE SCHEMA SCD_SCH;
create table stream if not exists customer_table_changes
on table customer
WITH PROPERTIES('TABLE_STREAM_MODE' = 'STANDARD');
--external data lake
--创建数据湖Connection,到数据湖的连接
CREATE STORAGE CONNECTION if not exists hz_ingestion_demo
TYPE oss
ENDPOINT = 'oss-cn-hangzhou-internal.aliyuncs.com'
access_id = '请输入您的access_id'
access_key = '请输入您的access_key'
comments = 'hangzhou oss private endpoint for ingest demo'
USE VCLUSTER SCD_VC;
USE SCHEMA SCD_SCH;
--创建Volume,数据湖存储文件的位置
CREATE EXTERNAL VOLUME if not exists scd_demo
LOCATION 'oss://yourbucketname/scd_demo'
USING connection hz_ingestion_demo -- storage Connection
DIRECTORY = (
enable = TRUE
)
recursive = TRUE;
--同步数据湖Volume的目录到Lakehouse
ALTER volume scd_demo refresh;
--查看云器Lakehouse数据湖Volume上的文件
SELECT * from directory(volume scd_demo);
show volumes;
创建Pipe
SQL任务:13_pipe_creation_for_data_ingestion
USE VCLUSTER SCD_VC;
USE SCHEMA SCD_SCH;
create pipe volume_pipe_cdc_demo
VIRTUAL_CLUSTER = 'scd_vc'
--执行获取最新文件使用扫描文件模式
INGEST_MODE = 'LIST_PURGE'
as
copy into customer_raw from volume scd_demo(customer_id string,
first_name varchar,
last_name varchar,
email varchar,
street varchar,
city varchar,
state varchar,
country varchar)
using csv OPTIONS(
'header'='true'
)
--必须添加purge参数导入成功后删除数据
purge=true
;
show pipes;
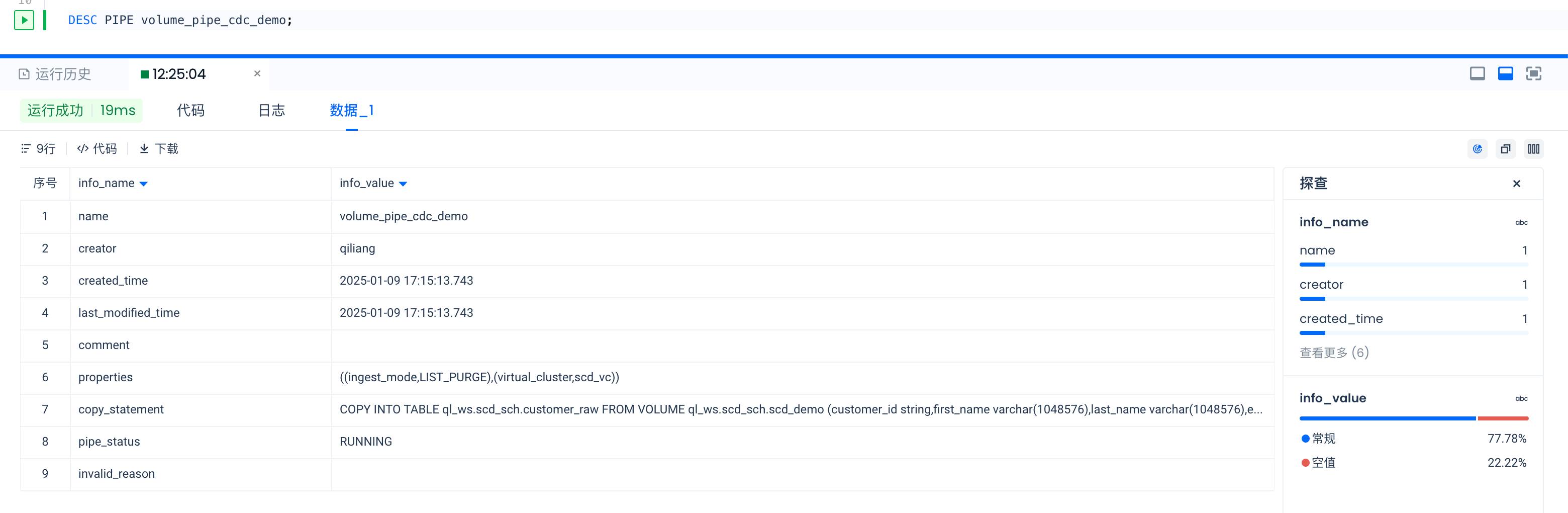
DESC PIPE volume_pipe_cdc_demo;
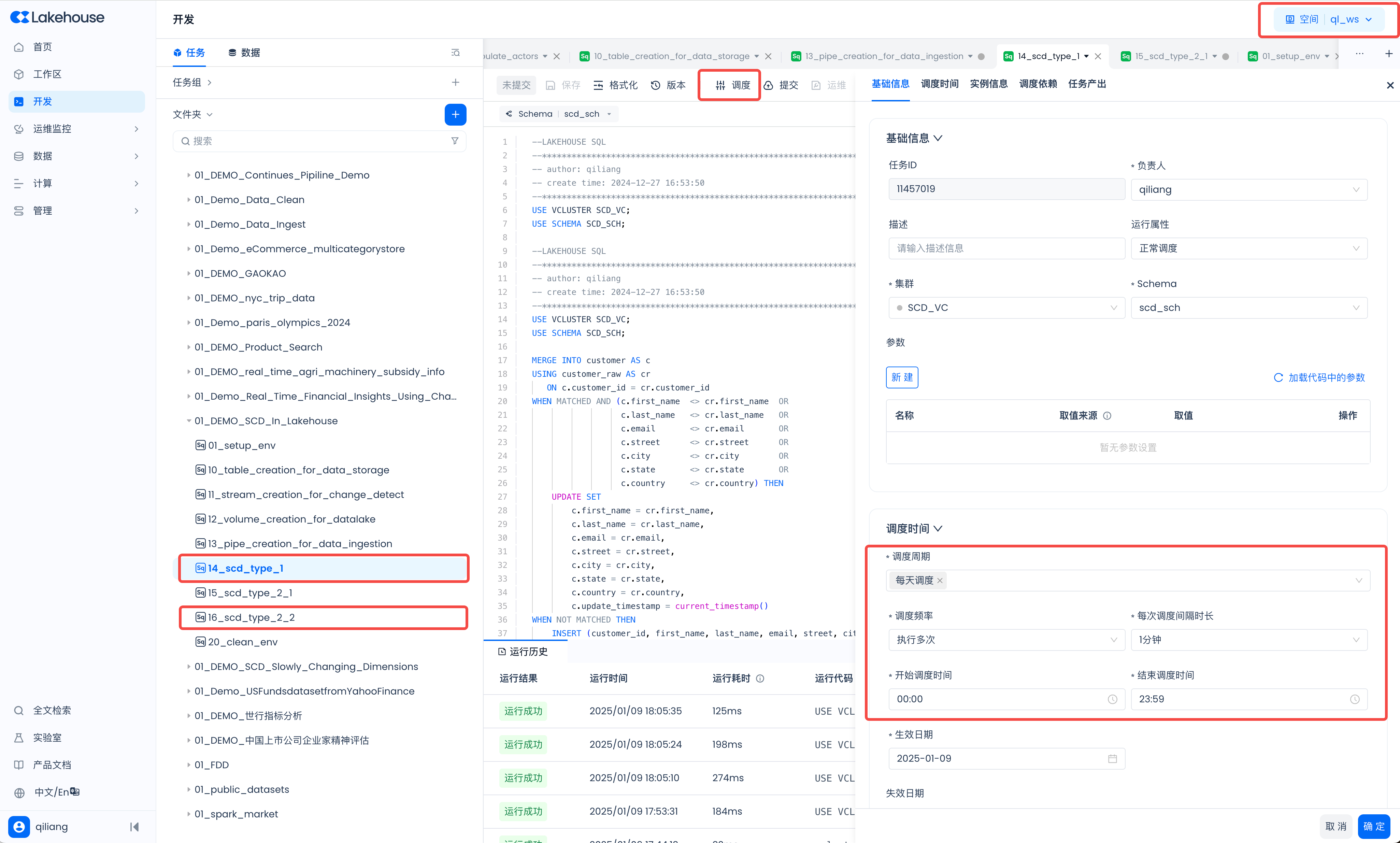
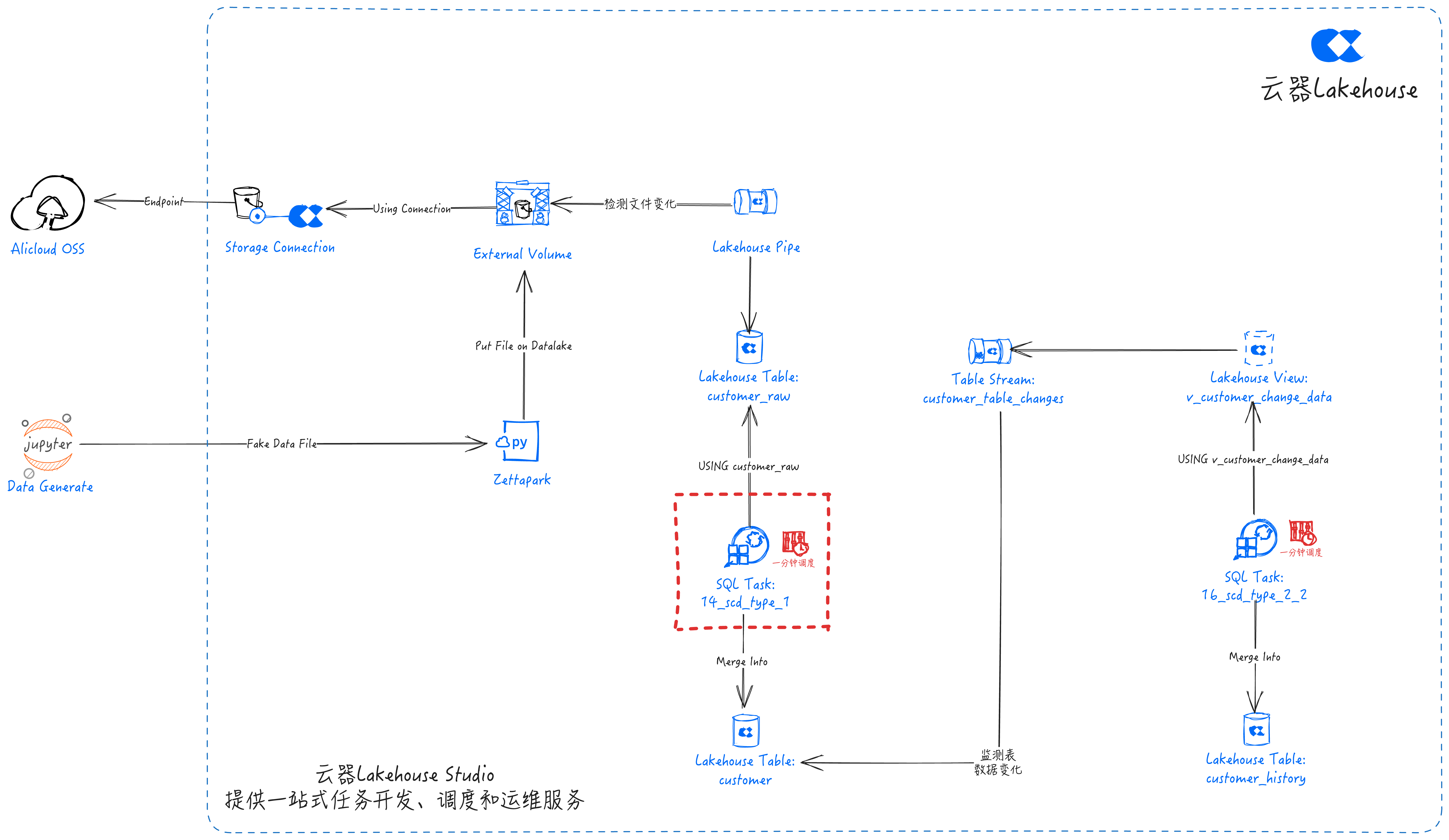
SCD Type 1
SQL任务:14_scd_type_1
USE VCLUSTER SCD_VC;
USE SCHEMA SCD_SCH;
MERGE INTO customer AS c
USING customer_raw AS cr
ON c.customer_id = cr.customer_id
WHEN MATCHED AND (c.first_name <> cr.first_name OR
c.last_name <> cr.last_name OR
c.email <> cr.email OR
c.street <> cr.street OR
c.city <> cr.city OR
c.state <> cr.state OR
c.country <> cr.country) THEN
UPDATE SET
c.first_name = cr.first_name,
c.last_name = cr.last_name,
c.email = cr.email,
c.street = cr.street,
c.city = cr.city,
c.state = cr.state,
c.country = cr.country,
c.update_timestamp = current_timestamp()
WHEN NOT MATCHED THEN
INSERT (customer_id, first_name, last_name, email, street, city, state, country)
VALUES (cr.customer_id, cr.first_name, cr.last_name, cr.email, cr.street, cr.city, cr.state, cr.country);
select count(*) from customer;
SCD Type 2-1
SQL任务:15_scd_type_2_1
USE VCLUSTER SCD_VC;
USE SCHEMA SCD_SCH;
-- 创建视图 v_customer_change_data
CREATE VIEW IF NOT EXISTS v_customer_change_data AS
-- 这个子查询用于处理插入到 customer 表的数据
-- 插入到 customer 表的数据会在 customer_HISTORY 表中产生一条新的插入记录
SELECT CUSTOMER_ID, FIRST_NAME, LAST_NAME, EMAIL, STREET, CITY, STATE, COUNTRY,
start_time, end_time, is_current, 'I' AS dml_type
FROM (
SELECT CUSTOMER_ID, FIRST_NAME, LAST_NAME, EMAIL, STREET, CITY, STATE, COUNTRY,
update_timestamp AS start_time,
LAG(update_timestamp) OVER (PARTITION BY customer_id ORDER BY update_timestamp DESC) AS end_time_raw,
CASE WHEN end_time_raw IS NULL THEN '9999-12-31' ELSE end_time_raw END AS end_time,
CASE WHEN end_time_raw IS NULL THEN TRUE ELSE FALSE END AS is_current
FROM (
SELECT CUSTOMER_ID, FIRST_NAME, LAST_NAME, EMAIL, STREET, CITY, STATE, COUNTRY, UPDATE_TIMESTAMP
FROM customer_table_changes
WHERE __change_type = 'INSERT'
)
)
UNION
-- 这个子查询用于处理更新到 customer 表的数据
-- 更新到 customer 表的数据会在 customer_HISTORY 表中产生一条更新记录和一条插入记录
-- 下面的子查询会生成两条记录,每条记录有不同的 dml_type
SELECT CUSTOMER_ID, FIRST_NAME, LAST_NAME, EMAIL, STREET, CITY, STATE, COUNTRY, start_time, end_time, is_current, dml_type
FROM (
SELECT CUSTOMER_ID, FIRST_NAME, LAST_NAME, EMAIL, STREET, CITY, STATE, COUNTRY,
update_timestamp AS start_time,
LAG(update_timestamp) OVER (PARTITION BY customer_id ORDER BY update_timestamp DESC) AS end_time_raw,
CASE WHEN end_time_raw IS NULL THEN '9999-12-31' ELSE end_time_raw END AS end_time,
CASE WHEN end_time_raw IS NULL THEN TRUE ELSE FALSE END AS is_current,
dml_type
FROM (
-- 识别需要插入到 customer_history 表的数据
SELECT CUSTOMER_ID, FIRST_NAME, LAST_NAME, EMAIL, STREET, CITY, STATE, COUNTRY, update_timestamp, 'I' AS dml_type
FROM customer_table_changes
WHERE __change_type = 'INSERT'
UNION
-- 识别 customer_HISTORY 表中需要更新的数据
SELECT CUSTOMER_ID, null AS FIRST_NAME, null AS LAST_NAME, null AS EMAIL, null AS STREET, null AS CITY, null AS STATE, null AS COUNTRY, start_time, 'U' AS dml_type
FROM customer_history
WHERE customer_id IN (
SELECT DISTINCT customer_id
FROM customer_table_changes
WHERE __change_type = 'DELETE'
)
AND is_current = TRUE
)
)
UNION
-- 这个子查询用于处理从 customer 表中删除的数据
-- 从 customer 表中删除的数据会在 customer_HISTORY 表中产生一条更新记录
SELECT ctc.CUSTOMER_ID, null AS FIRST_NAME, null AS LAST_NAME, null AS EMAIL, null AS STREET, null AS CITY, null AS STATE, null AS COUNTRY, ch.start_time, current_timestamp() AS end_time, NULL AS is_current, 'D' AS dml_type
FROM customer_history ch
INNER JOIN customer_table_changes ctc
ON ch.customer_id = ctc.customer_id
WHERE ctc.__change_type = 'DELETE'
AND ch.is_current = TRUE;
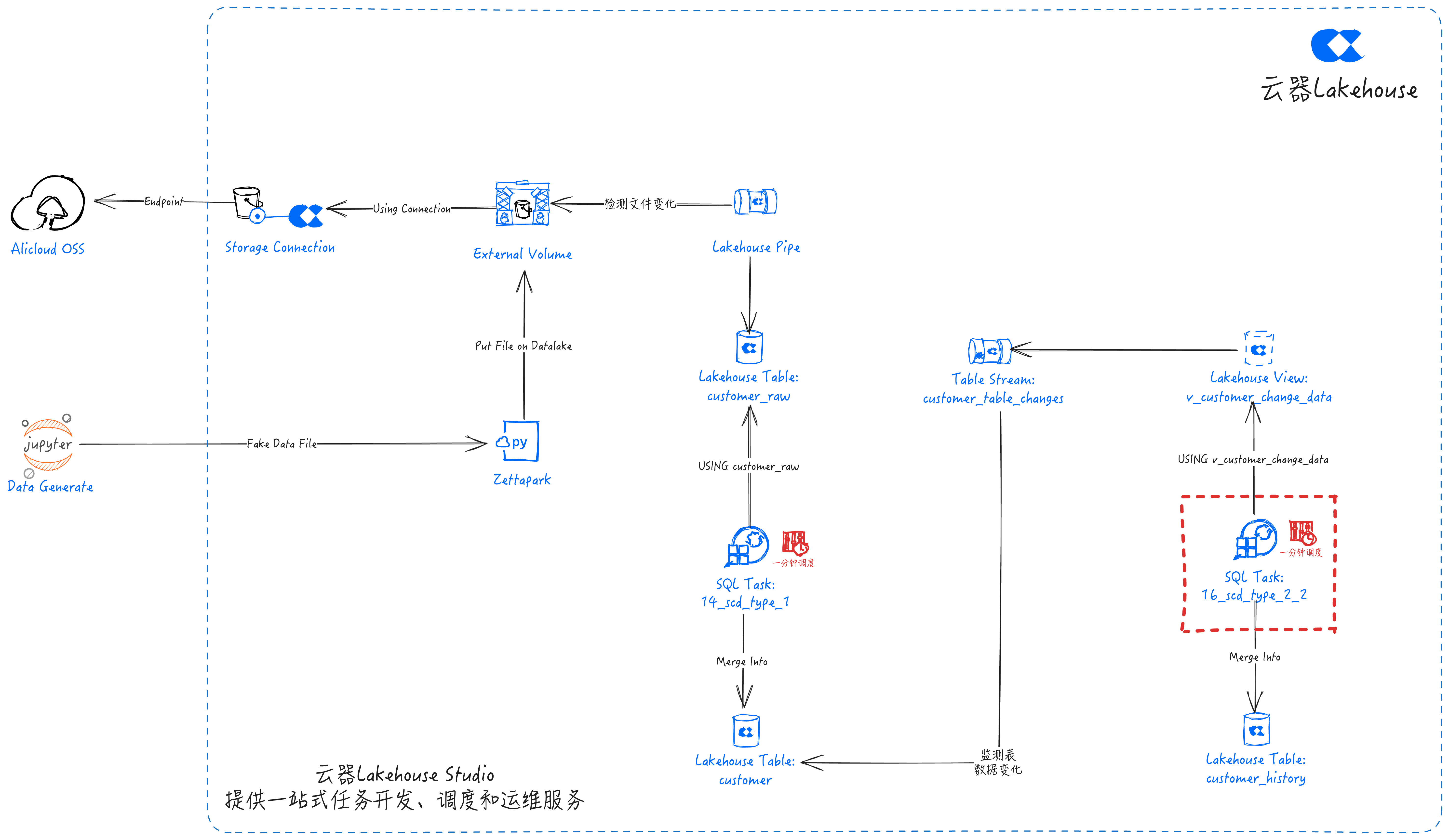
SCD Type 2-2
SQL任务:16_scd_type_2_2
USE VCLUSTER SCD_VC;
USE SCHEMA SCD_SCH;
merge into customer_history ch -- 目标表,将 NATION 中的变化合并到此表中
using v_customer_change_data ccd -- v_customer_change_data 是一个视图,包含插入/更新到 customer_history 表的逻辑。
on ch.CUSTOMER_ID = ccd.CUSTOMER_ID -- CUSTOMER_ID 和 start_time 确定 customer_history 表中是否存在唯一记录
and ch.start_time = ccd.start_time
when matched and ccd.dml_type = 'U' then update -- 表示记录已被更新且不再是当前记录,需要标记 end_time
set ch.end_time = ccd.end_time,
ch.is_current = FALSE
when matched and ccd.dml_type = 'D' then update -- 删除实际上是逻辑删除。记录会被标记且不会插入新版本
set ch.end_time = ccd.end_time,
ch.is_current = FALSE
when not matched and ccd.dml_type = 'I' then insert -- 插入一个新的 CUSTOMER_ID 或更新现有 CUSTOMER_ID 都会产生一个插入操作
(CUSTOMER_ID, FIRST_NAME, LAST_NAME, EMAIL, STREET, CITY, STATE, COUNTRY, start_time, end_time, is_current)
values (ccd.CUSTOMER_ID, ccd.FIRST_NAME, ccd.LAST_NAME, ccd.EMAIL, ccd.STREET, ccd.CITY, ccd.STATE, ccd.COUNTRY, ccd.start_time, ccd.end_time, ccd.is_current);