将Snowflake的实时ETL Pipeline迁移到云器Lakehouse
亮点
本文基于云器Lakehouse,快速实现了将Snowflake的实时ETL Pipeline迁移到云器Lakehouse,并发现基于云器Lakehouse的方案具备如下独特优势:
- 全球多云支持。本方案中云器Lakehouse和Snowflake都基于AWS,提供了云体验的一致性。同样本方案也适合在GCP上的迁移。同时云器Lakehouse还支持阿里云、腾讯云、华为云,而不仅仅是海外主流云服务提供商的支持。
- 迁移成本低。
- 云器Lakehouse提供了和Snowflake非常相似的产品概念,这对熟悉Snowflake的用户而言,非常容易理解和上手。
- 云器Lakehouse的SQL语法和Snowflake高度兼容,只需要做很少的Tiny修改即可实现代码迁移。
- 运维成本低
- 云器Lakehouse提供了内置的Python运行环境并和SQL等任务实现统一的调度、运维和监控。不需要额外的Airflow服务、Python运行环境,大幅简化了系统架构,降低了运维难度和成本。
Real-Time Insurance Data ETL Pipeline with Snowflake项目介绍
项目概况
如果你熟悉Snowflake的实际操作和应用,那么Github上的Real-Time Insurance Data ETL Pipeline with Snowflake 对你是再熟悉不过了。该项目涉及在Snowflake中创建实时 ETL(提取、转换、加载)数据管道,以处理来自 Kaggle 的保险数据并将其加载到 Snowflake 中。数据管道使用 Apache Airflow 进行管理,涉及几个步骤来清理、规范化和转换数据,然后将其加载到 Snowflake 进行进一步处理。AWS S3 用作数据湖,用于存储原始数据和转换后的数据。
开发完该项目后,可以根据需求安排 Airflow DAG 运行,确保 ETL 流程以所需的频率执行。最终清理、规范化和转换后的数据将可在 Tableau 中进行实时可视化,从而获得最新的见解和报告。项目架构图如下:
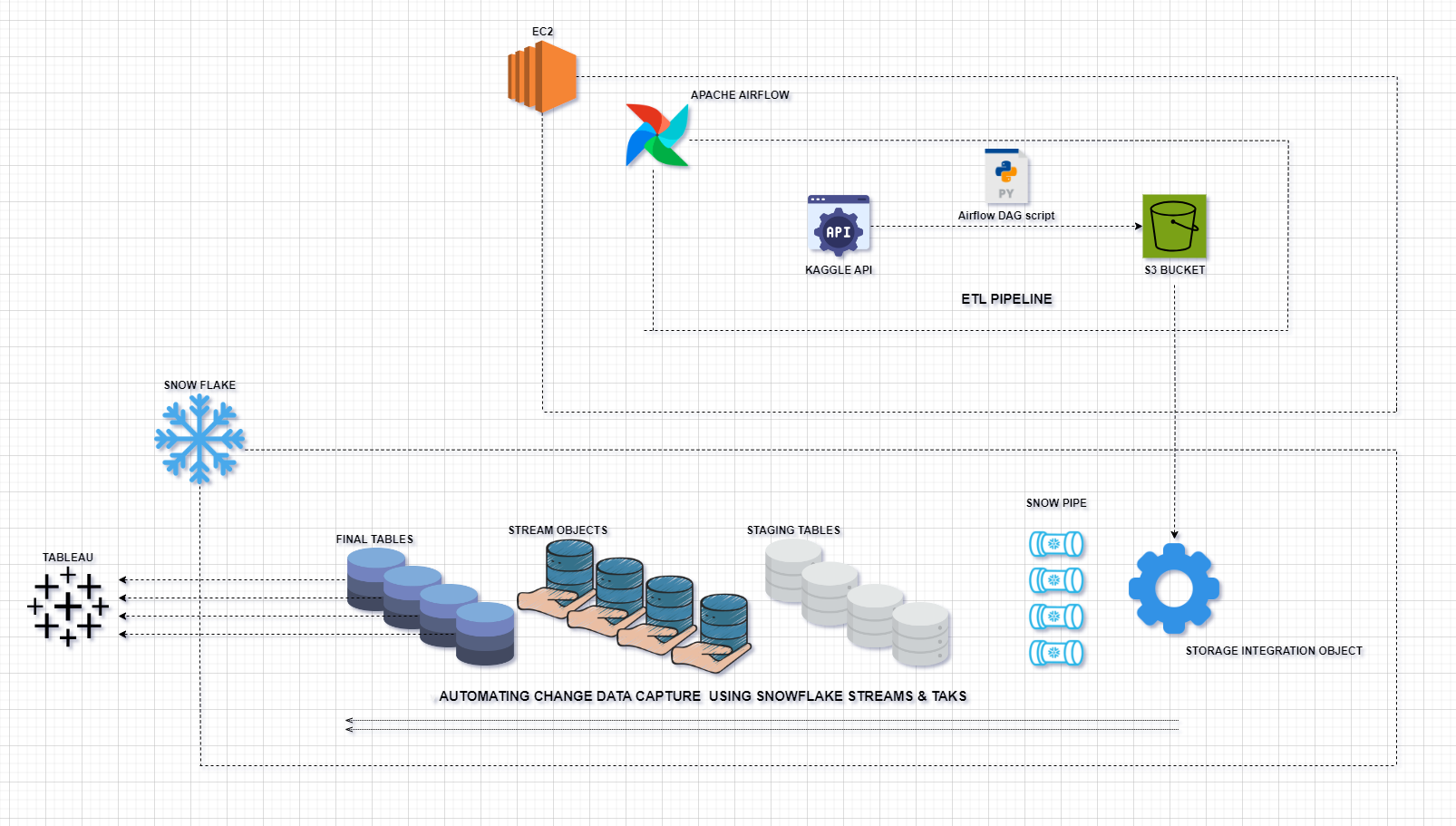
使用的工具和服务
- Python:用于脚本编写和数据处理。
- Pandas:用于数据操作和分析。
- AWS S3:作为存储原始数据和转换后数据的数据湖。
- Snowflake:用于数据建模和存储。
- Apache Airflow:用于协调 ETL 工作流程。
- EC2:用于托管 Airflow 环境。
- Kaggle API:用于从 Kaggle 提取数据。
- Tableau:用于数据可视化。
ETL 工作流
-
数据提取
-
数据存储
- 将转换后的数据存储在 S3 存储桶中,并针对每种类型的规范化数据 (
policy_data
policy_data
、customers_data
customers_data
、vehicles_data
vehicles_data
、claims_data
claims_data
) 组织到不同的文件夹中。
-
Snowflake中的数据处理
- 创建 Snowflake SQL 工作表来定义数据库模式。
- 在 Snowflake 中为每种类型的规范化数据创建暂存表。
- 定义 Snowpipes 以自动将数据从 S3 存储桶提取到暂存表。
- 为每个暂存表创建流对象以捕获变化。
- 创建最终表以合并来自流对象的新数据,确保仅插入不同的或新的行。
-
使用 Snowflake 流和任务更改数据捕获
- 在 Snowflake 中创建任务以自动捕获变更数据。
- 当流对象中有新数据可用时,将触发每个任务以将数据加载到最终表中。
-
Airflow DAG 任务
- 任务 1:检查 Kaggle API 是否可用。
- 任务 2:将转换后的数据上传到 S3 存储桶。
迁移方案
需要什么
云器Lakehouse和Snowflake对象概念映射
| 云器Lakehouse概念 | Snowflake概念 |
|---|
| WORSPACE | DATABASE |
| SCHEMA | SCHEMA |
| VCLUSTER | WAREHOUSE |
| STORAGE CONNECTION | STORAGE INTEGRATION |
| VOLUME | STAGE |
| TABLE | TABLE |
| PIPE | SNOWPIPE |
| TABLE STREAM | STREAM |
| STUDIO 任务 | TASK |
| Lakehouse SQL | Snowflake SQL |
基于云器Lakehouse的架构
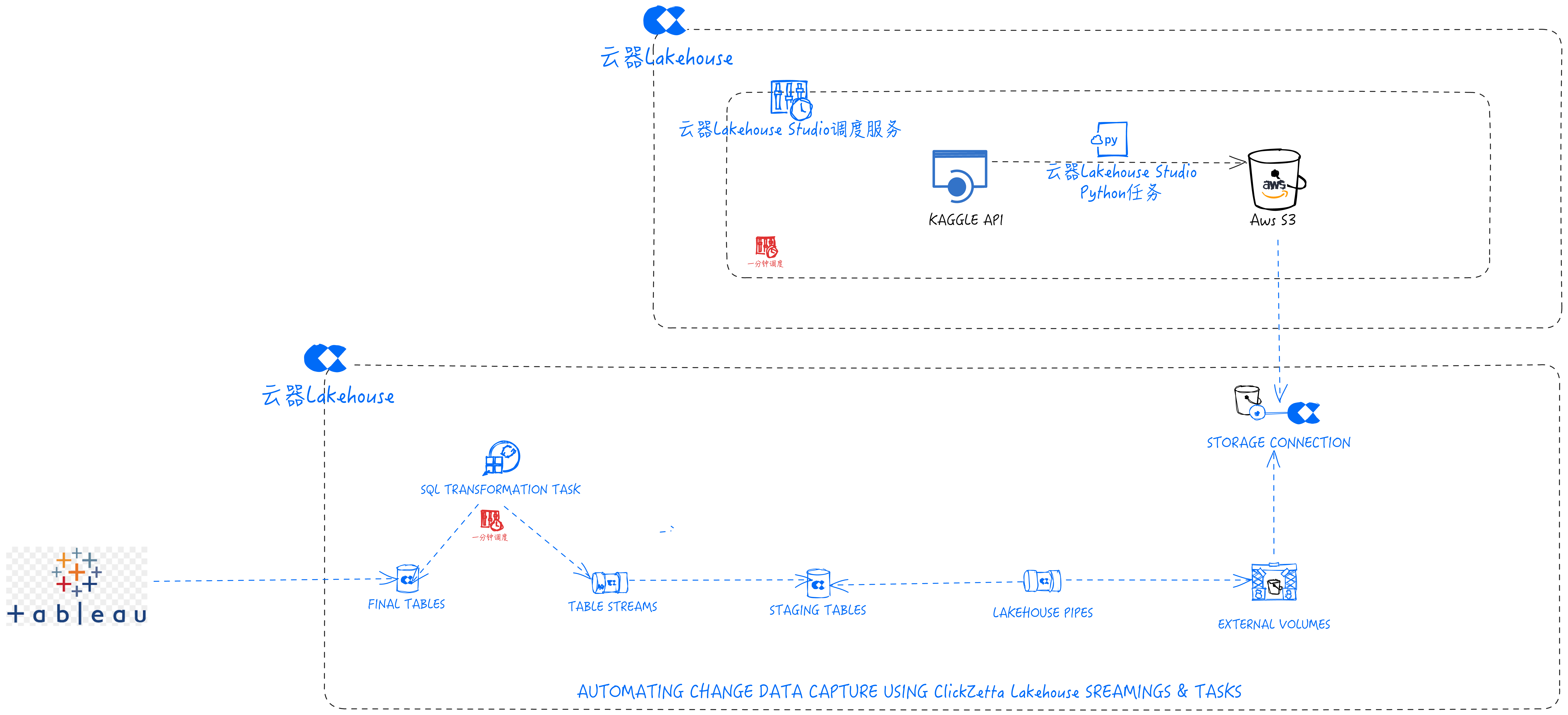
云器Lakehouse方案和Snowflake方案里的工具和服务对比
| 云器Lakehouse方案里工具和服务 | 用途 | Snowflake方案里的工具和服务 | 用途 |
|---|
| Python | 用于脚本编写和数据处理 | Python | 用于脚本编写和数据处理 |
| Pandas | 用于数据操作和分析 | Pandas | 用于数据操作和分析 |
| AWS S3 | 作为存储原始数据和转换后数据的数据湖 | AWS S3 | 作为存储原始数据和转换后数据的数据湖 |
| 云器Lakehouse | 用于数据建模和存储 | Snowflake | 用于数据建模和存储 |
| 云器Lakehouse Studio IDE | 用于协调 ETL 工作流程 | Apache Airflow | 用于协调 ETL 工作流程 |
| 云器Lakehouse Studio Python任务 | 用于托管 Airflow 环境 | EC2 | 用于托管 Airflow 环境 |
| 云器Lakehouse JDBC Driver | 用于连接Tableau | Tableau Snowflake连接器 | 用于连接Tableau |
| Kaggle API | 用于从 Kaggle 提取数据 | Kaggle API | 用于从 Kaggle 提取数据 |
| Tableau | 用于数据可视化 | Tableau | 用于数据可视化 |
迁移中碰到的语法差异
| 功能 | 云器Lakehouse | Snowflake |
|---|
| 代码注释 | —- or — | /// or // |
| stream元数据 | __change_type字段 | METADATA$ACTION |
| 创建对象DDL | 有些对象不支持CREATE OR REPLACE,用CREATE IF NOT EXISTS和ALTER的方式 | CREATE OR REPLACE |
迁移步骤
任务开发
任务树
导航到Lakehouse Studio的开发->任务,
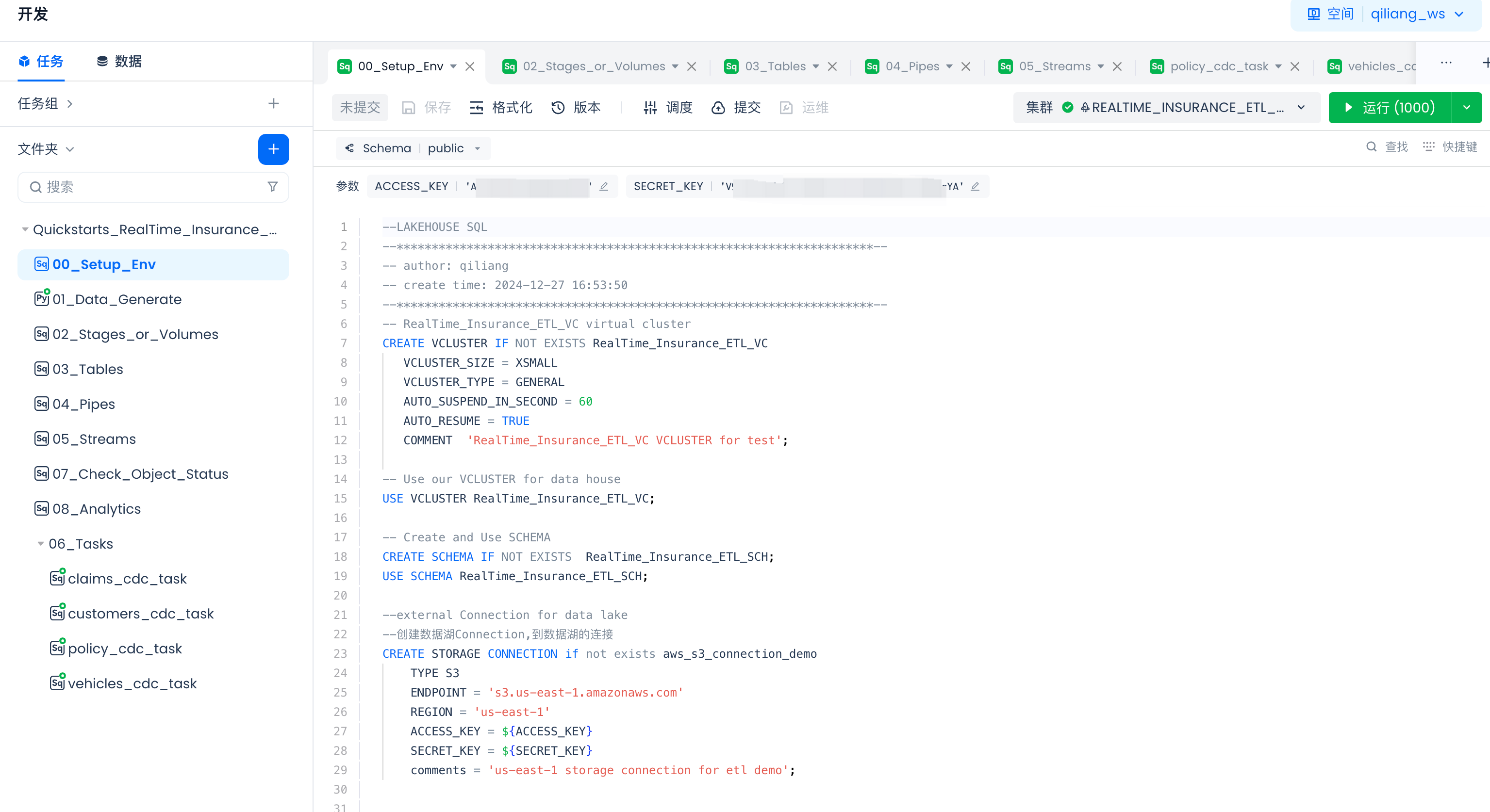
单击“+”新建如下目录:
- Quickstarts_RealTime_Insurance_claims_Data_ETL_Pipeline
单击“+”新建如下SQL任务:
- 00_Setup_Env
- 02_Stages_or_Volumes
- 03_Tables
- 04_Pipes
- 05_Streams
以上任务开发好后请点击“运行”完成对象创建。
单击“+”新建如下PYTHON任务:
- 01_Data_Generate
- 06_Tasks(目录)
- claims_cdc_task
- customers_cdc_task
- policy_cdc_task
- vehicles_cdc_task
以上任务开发好后请点击“运行”先进行测试(后续步骤请参考文档后面的调度和发布指导)。
将如下代码复制到对应的任务里,也可以从GitHub下载文件后将内容复制到对应的任务里。
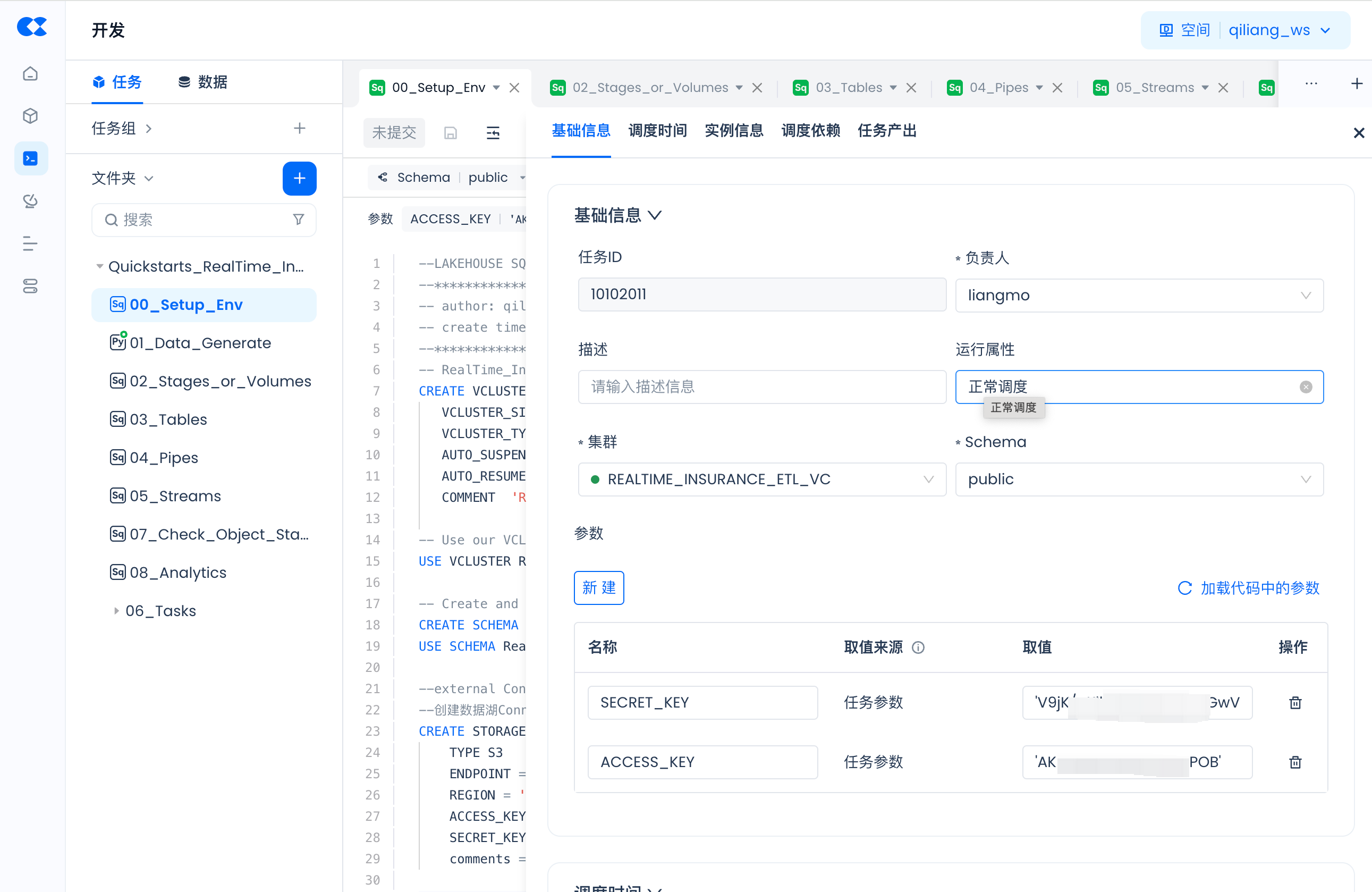
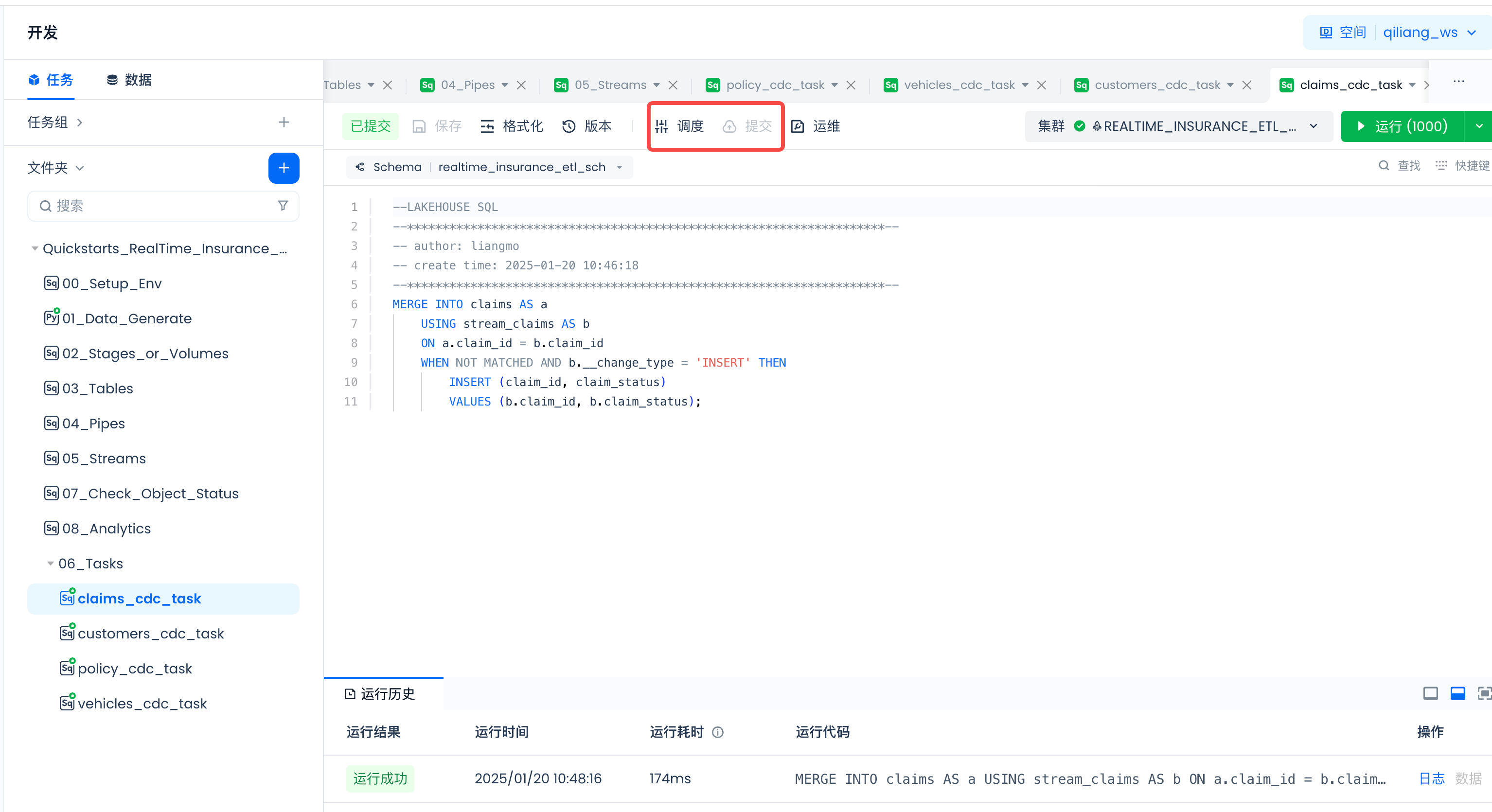
任务里的参数设置
对于任务(00_Setup_Env和01_Data_Generate)里是带有参数的,比如:
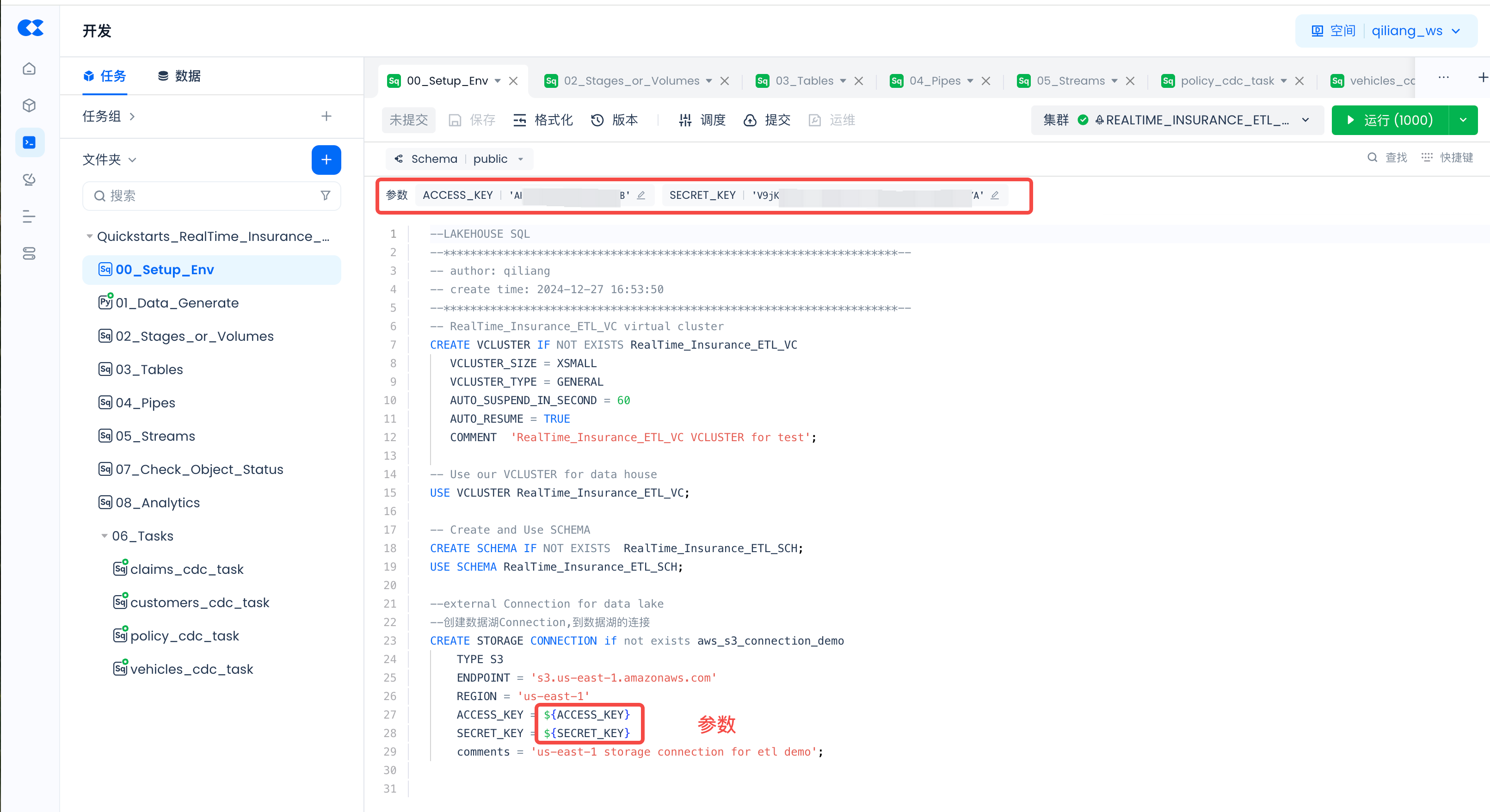
请点击“调度”:

然后“加载代码中的参数”并填入实际值:
构建云器Lakehouse环境
00_Setup_Env:
-- RealTime_Insurance_ETL_VC virtual cluster
CREATE VCLUSTER IF NOT EXISTS RealTime_Insurance_ETL_VC
VCLUSTER_SIZE = XSMALL
VCLUSTER_TYPE = GENERAL
AUTO_SUSPEND_IN_SECOND = 60
AUTO_RESUME = TRUE
COMMENT 'RealTime_Insurance_ETL_VC VCLUSTER for test';
-- Use our VCLUSTER for data house
USE VCLUSTER RealTime_Insurance_ETL_VC;
-- Create and Use SCHEMA
CREATE SCHEMA IF NOT EXISTS RealTime_Insurance_ETL_SCH;
USE SCHEMA RealTime_Insurance_ETL_SCH;
--external Connection for data lake
--创建数据湖Connection,到数据湖的连接
CREATE STORAGE CONNECTION if not exists aws_s3_connection_demo
TYPE S3
ENDPOINT = 's3.us-east-1.amazonaws.com'
REGION = 'us-east-1'
ACCESS_KEY = ${ACCESS_KEY}
SECRET_KEY = ${SECRET_KEY}
comments = 'us-east-1 storage connection for etl demo';
将SNOWFLAKE_ETL.py迁移为云器Lakehouse的内置Python任务Data_Generate
云器Lakehouse提供了托管的Python运行环境,在云器Lakehouse Studio里开发的Python任务,可以直接运行,也可以通过配置调度信息实现周期性的运行。
01_Data_Generate:
import subprocess
import sys
import warnings
import contextlib
import os
# Suppress warnings
warnings.filterwarnings("ignore", message="A value is trying to be set on a copy of a slice from a DataFrame")
# Suppress stderr
@contextlib.contextmanager
def suppress_stderr():
with open(os.devnull, 'w') as devnull:
old_stderr = sys.stderr
sys.stderr = devnull
try:
yield
finally:
sys.stderr = old_stderr
with suppress_stderr():
# Install kaggle
subprocess.run([sys.executable, "-m", "pip", "install", "kaggle", "--target", "/home/system_normal", "-i", "https://pypi.tuna.tsinghua.edu.cn/simple"], stderr=subprocess.DEVNULL)
sys.path.append('/home/system_normal')
import pandas as pd
import boto3
import random
import os, json, io
import zipfile
from datetime import datetime
def load_random_sample(csv_file, sample_size):
# Count total rows in the CSV file
total_rows = sum(1 for line in open(csv_file, encoding='utf-8')) - 1 # Subtract header row
# Calculate indices of rows to skip (non-selected)
skip_indices = random.sample(range(1, total_rows + 1), total_rows - sample_size)
# Load DataFrame with random sample of rows
df = pd.read_csv(csv_file, skiprows=skip_indices)
policy_table = df[['policy_id', 'subscription_length', 'region_code', 'segment']].copy()
vehicles_table = df[['policy_id', 'vehicle_age', 'fuel_type', 'is_parking_sensors', 'is_parking_camera', 'rear_brakes_type', 'displacement', 'transmission_type', 'steering_type', 'turning_radius', 'gross_weight', 'is_front_fog_lights', 'is_rear_window_wiper', 'is_rear_window_washer', 'is_rear_window_defogger', 'is_brake_assist', 'is_central_locking', 'is_power_steering', 'is_day_night_rear_view_mirror', 'is_speed_alert', 'ncap_rating']].copy()
customers_table = df[['policy_id', 'customer_age', 'region_density']].copy()
claims_table = df[['policy_id', 'claim_status']].copy()
vehicles_table.rename(columns={'policy_id': 'vehicle_id'}, inplace=True)
customers_table.rename(columns={'policy_id': 'customer_id'}, inplace=True)
claims_table.rename(columns={'policy_id': 'claim_id'}, inplace=True)
return policy_table, vehicles_table, customers_table, claims_table
def upload_df_to_s3():
try:
with suppress_stderr():
# Setup Kaggle API
# Ensure the directory exists
config_dir = '/home/system_normal/tempdata/.config/kaggle'
if not os.path.exists(config_dir):
os.makedirs(config_dir)
# Create the kaggle.json file with the given credentials
kaggle_json = {
"username": ${kaggle_username},
"key": ${kaggel_key}
}
with open(os.path.join(config_dir, 'kaggle.json'), 'w') as f:
json.dump(kaggle_json, f)
# Set the environment variable to the directory containing kaggle.json
os.environ['KAGGLE_CONFIG_DIR'] = config_dir
from kaggle.api.kaggle_api_extended import KaggleApi
# Authenticate the Kaggle API
api = KaggleApi()
api.authenticate()
# Define the dataset
dataset = 'litvinenko630/insurance-claims'
# Define the CSV file name
csv_file = 'Insurance claims data.csv'
# Download the entire dataset as a zip file
api.dataset_download_files(dataset, path='/home/system_normal/tempdata')
# Extract the CSV file from the downloaded zip file
with zipfile.ZipFile('/home/system_normal/tempdata/insurance-claims.zip', 'r') as zip_ref:
zip_ref.extract(csv_file, path='/home/system_normal/tempdata')
policy_data, vehicles_data, customers_data, claims_data = load_random_sample(f'/home/system_normal/tempdata/{csv_file}', 20)
# Convert DataFrame to CSV string
policy = policy_data.to_csv(index=False)
vehicles = vehicles_data.to_csv(index=False)
customers = customers_data.to_csv(index=False)
claims = claims_data.to_csv(index=False)
current_datetime = datetime.now().strftime("%Y%m%d_%H%M%S")
# Ensure you have set your AWS credentials in environment variables or replace the following with your credentials
s3_client = boto3.client(
's3',
aws_access_key_id= ${aws_access_key_id},
aws_secret_access_key= ${aws_secret_access_key},
region_name= ${aws_region_name}
)
# Define S3 bucket and keys with current date and time
s3_bucket = 'insurance-data-clickzetta-etl-project'
s3_key_policy = f'policy/policy_{current_datetime}.csv'
s3_key_vehicles = f'vehicles/vehicles_{current_datetime}.csv'
s3_key_customers = f'customers/customers_{current_datetime}.csv'
s3_key_claims = f'claims/claims_{current_datetime}.csv'
# Upload to S3
s3_client.put_object(Bucket=s3_bucket, Key=s3_key_policy, Body=policy)
s3_client.put_object(Bucket=s3_bucket, Key=s3_key_vehicles, Body=vehicles)
s3_client.put_object(Bucket=s3_bucket, Key=s3_key_customers, Body=customers)
s3_client.put_object(Bucket=s3_bucket, Key=s3_key_claims, Body=claims)
printf("upload_df_to_s3 down:{s3_key_policy},{s3_key_vehicles},{s3_key_customers},{s3_key_claims}")
except Exception as e:
pass # Ignore errors
# Run the upload function
upload_df_to_s3()
创建云器Lakehouse Volumes(对应Snowflake的Stages)
02_Stages_or_Volumes:
请将LOCATION 's3://insurance-data-clickzetta-etl-project/policy'里的bucket名称insurance-data-clickzetta-etl-project改为你的bucket名称。
--创建Volume,数据湖存储文件的位置
CREATE EXTERNAL VOLUME if not exists policy_data_stage
LOCATION 's3://insurance-data-clickzetta-etl-project/policy'
USING connection aws_s3_connection_demo -- storage Connection
DIRECTORY = (
enable = TRUE
)
recursive = TRUE;
--同步数据湖Volume的目录到Lakehouse
ALTER volume policy_data_stage refresh;
--查看云器Lakehouse数据湖Volume上的文件
SELECT * from directory(volume policy_data_stage);
--********************************************************************--
--创建Volume,数据湖存储文件的位置
CREATE EXTERNAL VOLUME if not exists vehicles_data_stage
LOCATION 's3://insurance-data-clickzetta-etl-project/vehicles'
USING connection aws_s3_connection_demo -- storage Connection
DIRECTORY = (
enable = TRUE
)
recursive = TRUE;
--同步数据湖Volume的目录到Lakehouse
ALTER volume vehicles_data_stage refresh;
--查看云器Lakehouse数据湖Volume上的文件
SELECT * from directory(volume vehicles_data_stage);
--********************************************************************--
--创建Volume,数据湖存储文件的位置
CREATE EXTERNAL VOLUME if not exists customers_data_stage
LOCATION 's3://insurance-data-clickzetta-etl-project/customers'
USING connection aws_s3_connection_demo -- storage Connection
DIRECTORY = (
enable = TRUE
)
recursive = TRUE;
--同步数据湖Volume的目录到Lakehouse
ALTER volume customers_data_stage refresh;
--查看云器Lakehouse数据湖Volume上的文件
SELECT * from directory(volume customers_data_stage);
--********************************************************************--
--创建Volume,数据湖存储文件的位置
CREATE EXTERNAL VOLUME if not exists claims_data_stage
LOCATION 's3://insurance-data-clickzetta-etl-project/claims'
USING connection aws_s3_connection_demo -- storage Connection
DIRECTORY = (
enable = TRUE
)
recursive = TRUE;
--同步数据湖Volume的目录到Lakehouse
ALTER volume claims_data_stage refresh;
--查看云器Lakehouse数据湖Volume上的文件
SELECT * from directory(volume claims_data_stage);
创建云器Lakehouse Tables
03_Tables:
--- STAGING TABLES ---
--creating staging tables for each normalized tables created by data pipeline
CREATE TABLE IF NOT EXISTS staging_policy(
policy_id VARCHAR(15) ,
subscription_length FLOAT,
region_code VARCHAR(5),
segment VARCHAR(10));
CREATE TABLE IF NOT EXISTS staging_vehicles (
vehicle_id VARCHAR(15) ,
vehicle_age FLOAT,
fuel_type VARCHAR(10),
parking_sensors VARCHAR(5),
parking_camera VARCHAR(5),
rear_brakes_type VARCHAR(10),
displacement INT,
trasmission_type VARCHAR(20),
steering_type VARCHAR(15),
turning_radius FLOAT,
gross_weight INT,
front_fog_lights VARCHAR(5),
rear_window_wiper VARCHAR(5),
rear_window_washer VARCHAR(5),
rear_window_defogger VARCHAR(5),
brake_assist VARCHAR(5),
central_locking VARCHAR(5),
power_steering VARCHAR(5),
day_night_rear_view_mirror VARCHAR(5),
is_speed_alert VARCHAR(5),
ncap_rating INT);
CREATE TABLE IF NOT EXISTS staging_customers(
customer_id VARCHAR(20) ,
customer_age INT,
region_density INT);
CREATE TABLE IF NOT EXISTS staging_claims(
claim_id VARCHAR(20) ,
claim_status INT);
--- FINAL TABLES ---
--creating final table to store transformed data captured by stream objects
CREATE TABLE IF NOT EXISTS policy(
policy_id VARCHAR(15) ,
subscription_length FLOAT,
region_code VARCHAR(5),
segment VARCHAR(10));
SELECT * FROM policy;
TRUNCATE TABLE policy;
CREATE TABLE IF NOT EXISTS vehicles (
vehicle_id VARCHAR(15) ,
vehicle_age FLOAT,
fuel_type VARCHAR(10),
parking_sensors VARCHAR(5),
parking_camera VARCHAR(5),
rear_brakes_type VARCHAR(10),
displacement INT,
trasmission_type VARCHAR(20),
steering_type VARCHAR(15),
turning_radius FLOAT,
gross_weight INT,
front_fog_lights VARCHAR(5),
rear_window_wiper VARCHAR(5),
rear_window_washer VARCHAR(5),
rear_window_defogger VARCHAR(5),
brake_assist VARCHAR(5),
central_locking VARCHAR(5),
power_steering VARCHAR(5),
day_night_rear_view_mirror VARCHAR(5),
is_speed_alert VARCHAR(5),
ncap_rating INT);
CREATE TABLE IF NOT EXISTS customers(
customer_id VARCHAR(20) ,
customer_age INT,
region_density INT);
CREATE TABLE IF NOT EXISTS claims(
claim_id VARCHAR(20) ,
claim_status INT);
创建云器Lakehouse Pipes
04_Pipes:
create pipe policy_pipe
VIRTUAL_CLUSTER = 'RealTime_Insurance_ETL_VC'
--执行获取最新文件使用扫描文件模式
INGEST_MODE = 'LIST_PURGE'
as
copy into staging_policy from volume policy_data_stage(
policy_id VARCHAR(15) ,
subscription_length FLOAT,
region_code VARCHAR(5),
segment VARCHAR(10))
using csv OPTIONS(
'header'='true'
)
--必须添加purge参数导入成功后删除数据
purge=true
;
--********************************************************************--
create pipe vehicles_pipe
VIRTUAL_CLUSTER = 'RealTime_Insurance_ETL_VC'
--执行获取最新文件使用扫描文件模式
INGEST_MODE = 'LIST_PURGE'
as
copy into staging_vehicles from volume vehicles_data_stage(
vehicle_id VARCHAR(15) ,
vehicle_age FLOAT,
fuel_type VARCHAR(10),
parking_sensors VARCHAR(5),
parking_camera VARCHAR(5),
rear_brakes_type VARCHAR(10),
displacement INT,
trasmission_type VARCHAR(20),
steering_type VARCHAR(15),
turning_radius FLOAT,
gross_weight INT,
front_fog_lights VARCHAR(5),
rear_window_wiper VARCHAR(5),
rear_window_washer VARCHAR(5),
rear_window_defogger VARCHAR(5),
brake_assist VARCHAR(5),
central_locking VARCHAR(5),
power_steering VARCHAR(5),
day_night_rear_view_mirror VARCHAR(5),
is_speed_alert VARCHAR(5),
ncap_rating INT)
using csv OPTIONS(
'header'='true'
)
--必须添加purge参数导入成功后删除数据
purge=true
;
--********************************************************************--
create pipe customers_pipe
VIRTUAL_CLUSTER = 'RealTime_Insurance_ETL_VC'
--执行获取最新文件使用扫描文件模式
INGEST_MODE = 'LIST_PURGE'
as
copy into staging_customers from volume customers_data_stage(
customer_id VARCHAR(20),
customer_age INT,
region_density INT)
using csv OPTIONS(
'header'='true'
)
--必须添加purge参数导入成功后删除数据
purge=true
;
--********************************************************************--
create pipe claims_pipe
VIRTUAL_CLUSTER = 'RealTime_Insurance_ETL_VC'
--执行获取最新文件使用扫描文件模式
INGEST_MODE = 'LIST_PURGE'
as
copy into staging_claims from volume claims_data_stage(
claim_id VARCHAR(20) ,
claim_status INT)
using csv OPTIONS(
'header'='true'
)
--必须添加purge参数导入成功后删除数据
purge=true
;
创建云器Lakehouse Table Streams(对应Snowflake的Streams)
05_Streams:
--********************************************************************--
--- CREATING TABLE STREAM OBJECTS FOR EACH STAGING TABLES TO CAPTURE NEW DATA
-- creating TABLE STREAM objects for staging tables
CREATE TABLE STREAM IF NOT EXISTS STREAM_policy ON TABLE staging_policy
WITH
PROPERTIES ('TABLE_STREAM_MODE' = 'APPEND_ONLY');
--********************************************************************--
CREATE TABLE STREAM IF NOT EXISTS STREAM_vehicles ON TABLE staging_vehicles
WITH
PROPERTIES ('TABLE_STREAM_MODE' = 'APPEND_ONLY');
--********************************************************************--
CREATE TABLE STREAM IF NOT EXISTS STREAM_customers ON TABLE staging_customers
WITH
PROPERTIES ('TABLE_STREAM_MODE' = 'APPEND_ONLY');
--********************************************************************--
CREATE TABLE STREAM IF NOT EXISTS STREAM_claims ON TABLE staging_claims
WITH
PROPERTIES ('TABLE_STREAM_MODE' = 'APPEND_ONLY');
--********************************************************************--
-- check total streams
SHOW TABLE STREAMS;
检查新创建的对象
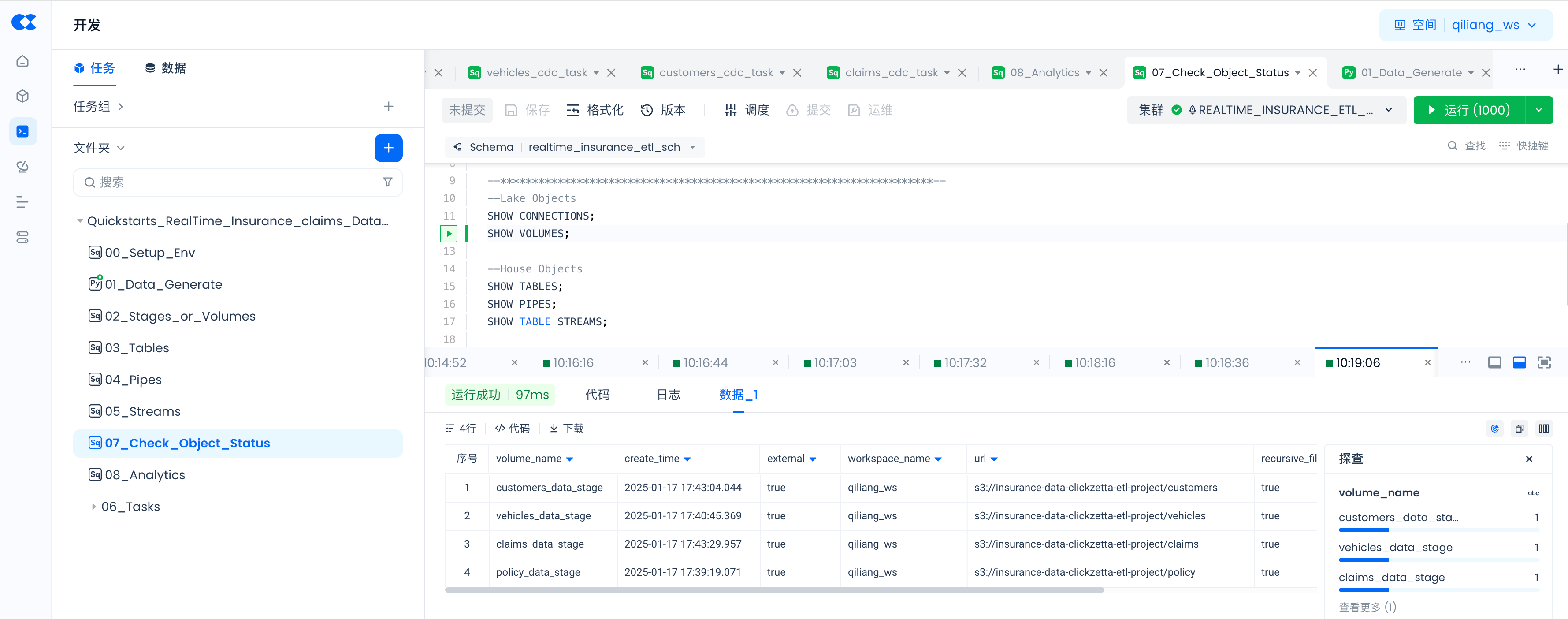
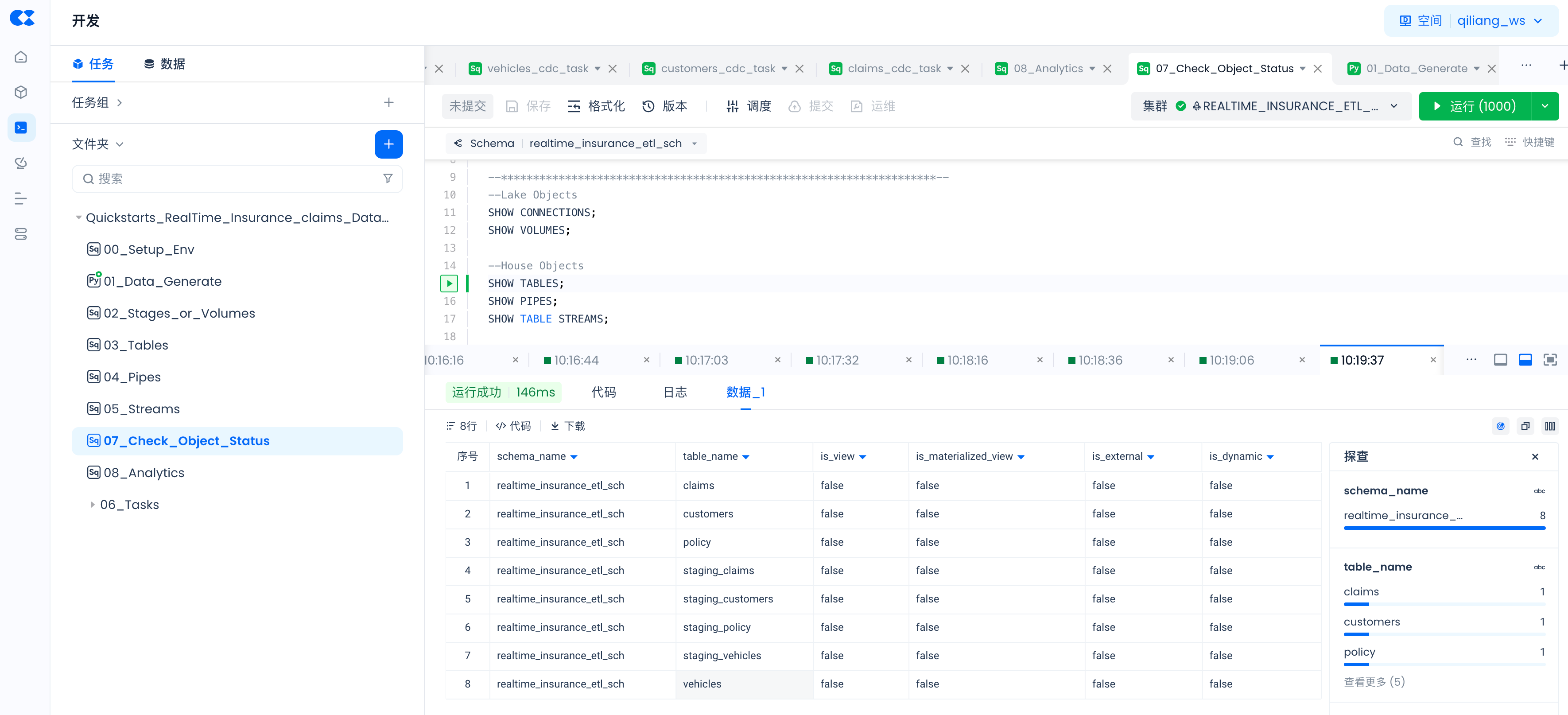
通过以下命令检查通过SQL命令创建对象是否已成功,以及PIPES的状态。
--Lake Objects
SHOW CONNECTIONS;
SHOW VOLUMES;
--House Objects
SHOW TABLES;
SHOW PIPES;
SHOW TABLE STREAMS;
SHOW CONNECTIONS;
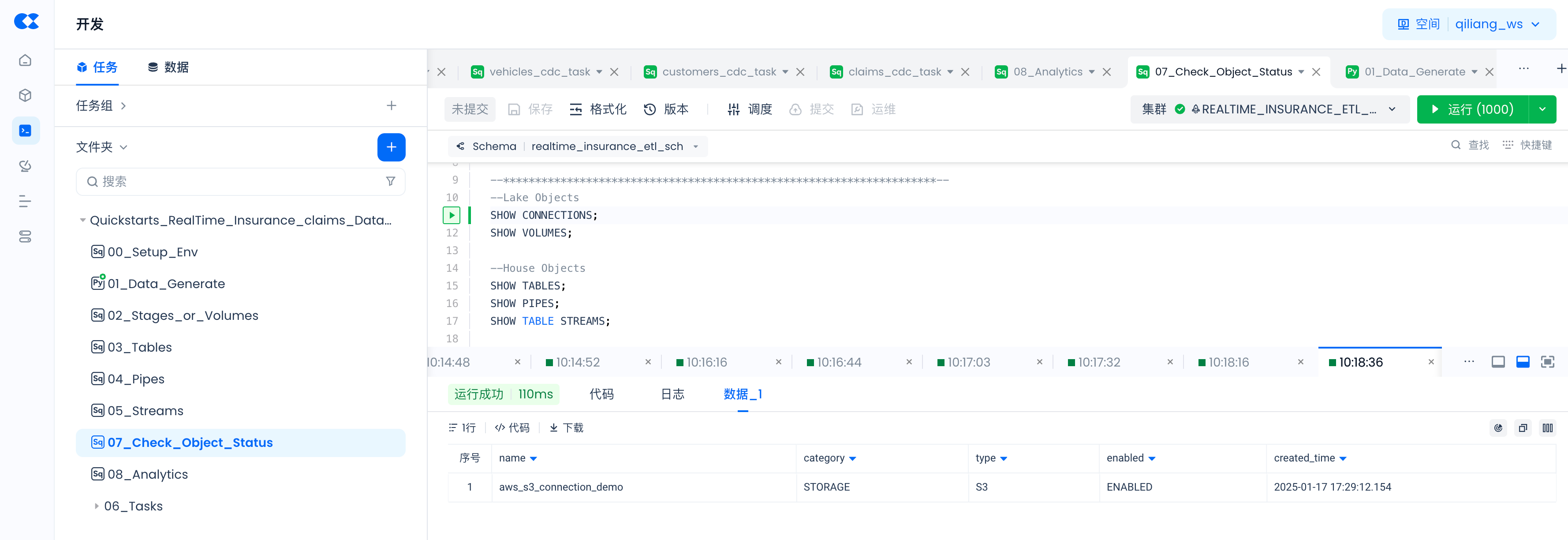
SHOW VOLUMES;
SHOW TABLES;
SHOW PIPES;
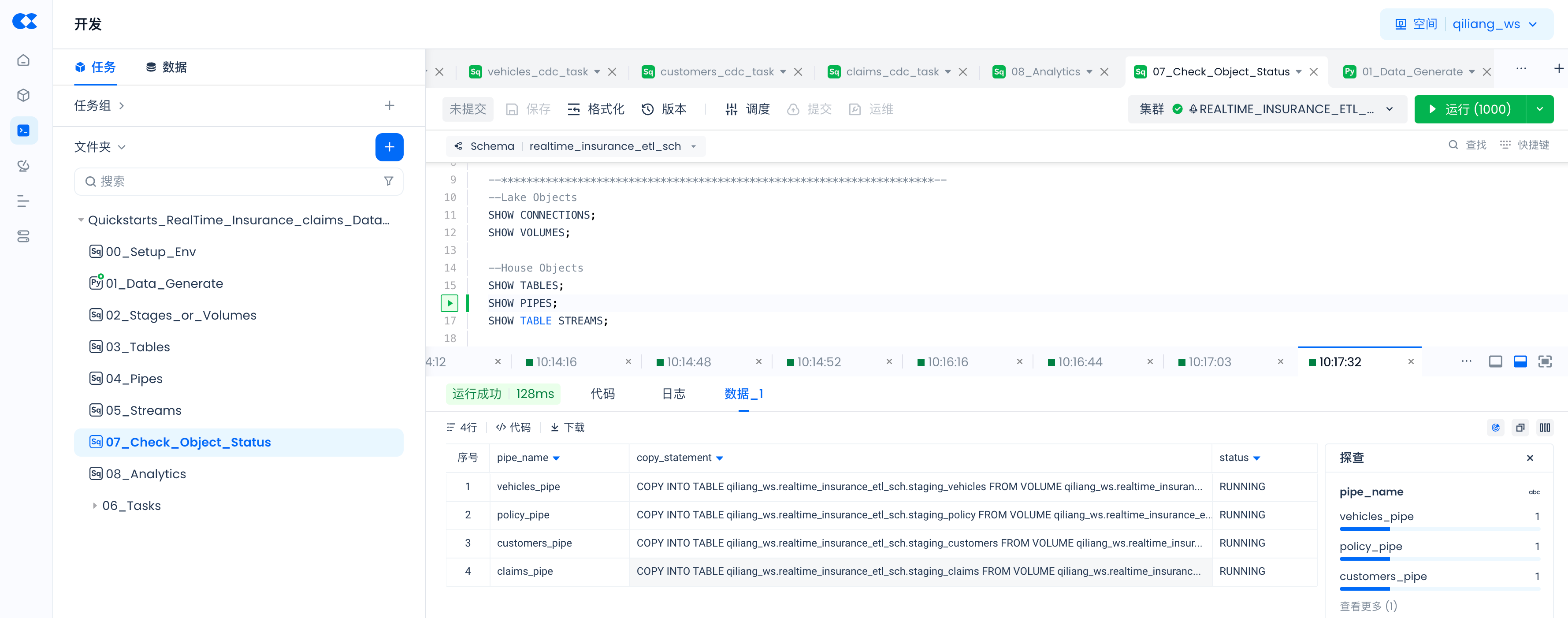
SHOW TABLE STREAMS;

06_Tasks:claims_cdc_task
MERGE INTO claims AS a
USING stream_claims AS b
ON a.claim_id = b.claim_id
WHEN NOT MATCHED AND b.__change_type = 'INSERT' THEN
INSERT (claim_id, claim_status)
VALUES (b.claim_id, b.claim_status);
06_Tasks:customers_cdc_task
MERGE INTO customers AS a
USING stream_customers AS b
ON a.customer_id = b.customer_id
WHEN NOT MATCHED AND b.__change_type = 'INSERT' THEN
INSERT (customer_id, customer_age, region_density)
VALUES (b.customer_id, b.customer_age, b.region_density);
06_Tasks:policy_cdc_task
MERGE INTO policy AS a
USING stream_policy AS b
ON a.policy_id = b.policy_id
WHEN NOT MATCHED AND b.__change_type = 'INSERT' THEN
INSERT (policy_id, subscription_length, region_code, segment)
VALUES (b.policy_id, b.subscription_length, b.region_code, b.segment);
06_Tasks:vehicles_cdc_task
MERGE INTO vehicles AS a
USING stream_vehicles AS b
ON a.vehicle_id = b.vehicle_id
WHEN NOT MATCHED AND b.__change_type = 'INSERT' THEN
INSERT (vehicle_id, vehicle_age, fuel_type, parking_sensors, parking_camera, rear_brakes_type, displacement, trasmission_type, steering_type, turning_radius, gross_weight, front_fog_lights, rear_window_wiper, rear_window_washer, rear_window_defogger, brake_assist, central_locking, power_steering, day_night_rear_view_mirror, is_speed_alert, ncap_rating)
VALUES (b.vehicle_id, b.vehicle_age,b.fuel_type, b.parking_sensors, b.parking_camera, b.rear_brakes_type, b.displacement, b.trasmission_type, b.steering_type, b.turning_radius, b.gross_weight, b.front_fog_lights, b.rear_window_wiper, b.rear_window_washer, b.rear_window_defogger, b.brake_assist, b.central_locking, b.power_steering, b.day_night_rear_view_mirror, b.is_speed_alert, b.ncap_rating);
生产运行
作业调度
导航到Lakehouse Studio的开发->任务,
配置如下任务的调度参数并提交到生成环境运行。
需要配置调度和提交上线的任务如下:
- 01_Data_Generate
- claims_cdc_task
- customers_cdc_task
- policy_cdc_task
- vehicles_cdc_task
调度参数配置如下:
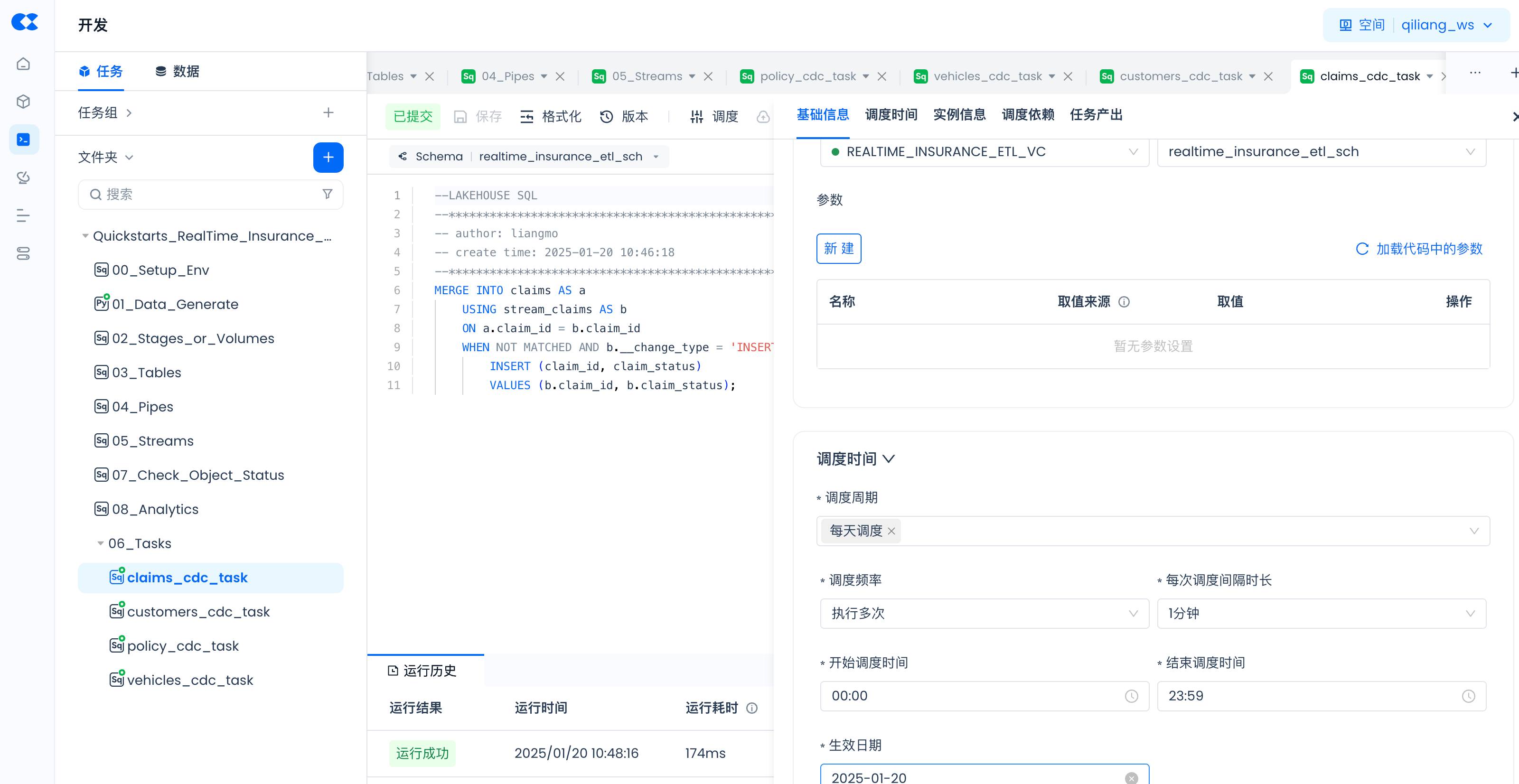
Streams和Pipes创建后会自动运行,无需调度。
通过Tableau分析云器Lakehouse里的数据
参考这个文章将Tableau通过JDBC连接到云器Lakehouse,对Lakehouse里的数据进行数据探查、分析,并创建BI报表。
周期任务运维
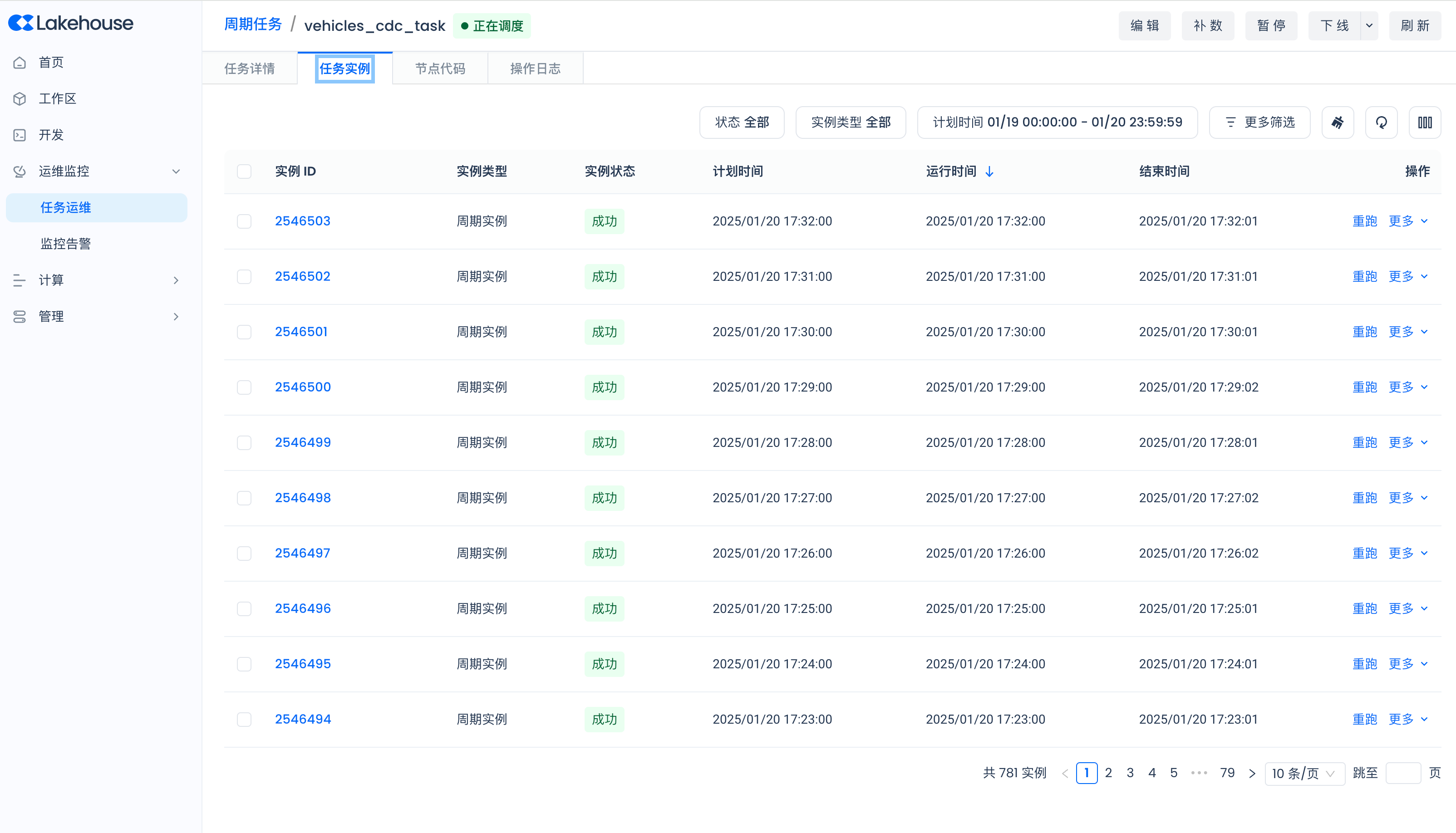
导航到Lakehouse Studio的运维监控->任务运维->周期任务,查看各个周期调度任务的运行状态:
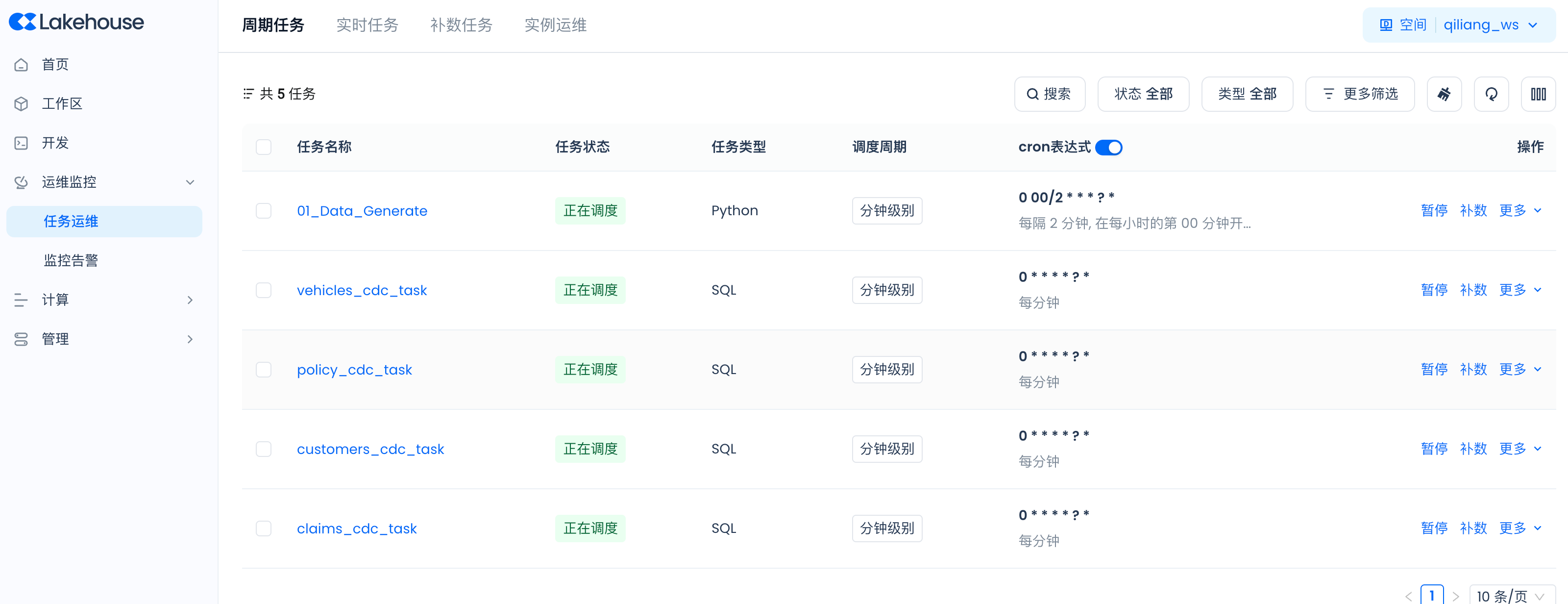
周期任务的任务实例管理
Pipes运维
-- 暂停和启动PIPE
-- 暂停
ALTER pipe policy_pipe SET PIPE_EXECUTION_PAUSED = true;
-- 启动
ALTER pipe policy_pipe SET PIPE_EXECUTION_PAUSED = false;
-- 查看pipe copy作业执行情况
-- 七天之内的,延迟半小时
SELECT * FROM INFORMATION_SCHEMA.JOB_HISTORY WHERE QUERY_TAG="pipe.qiliang_ws.realtime_insurance_etl_sch.policy_pipe";
-- 实时的
SHOW JOBS IN VCLUSTER SCD_VC WHERE QUERY_TAG="pipe.qiliang_ws.realtime_insurance_etl_sch.policy_pipe";
SHOW JOBS where length(QUERY_TAG)>10;
-- 查看copy作业导入的历史文件
select * from load_history('RealTime_Insurance_ETL_SCH.staging_policy');
select * from load_history('RealTime_Insurance_ETL_SCH.staging_vehicles');
select * from load_history('RealTime_Insurance_ETL_SCH.staging_customers');
select * from load_history('RealTime_Insurance_ETL_SCH.staging_claims');
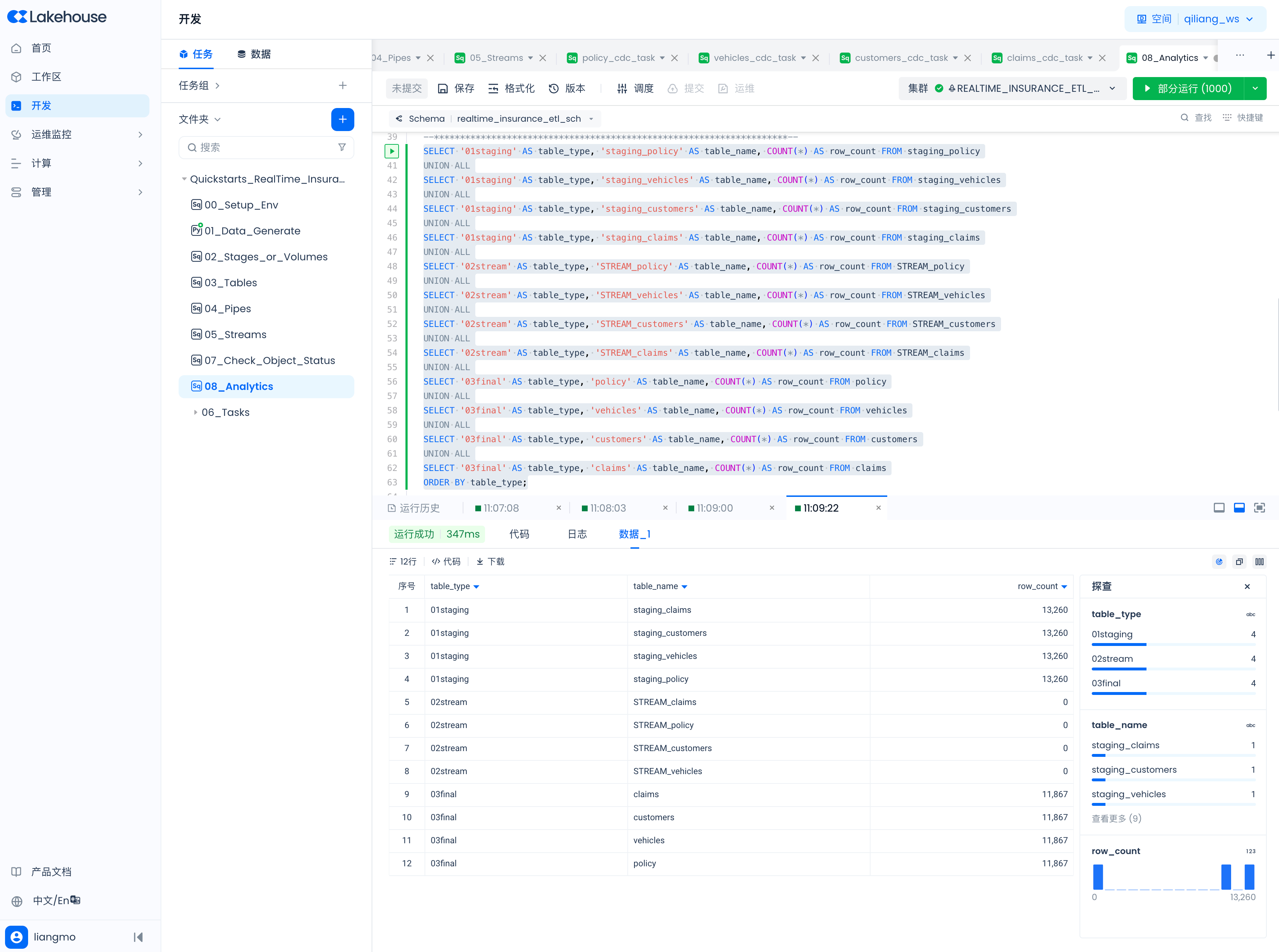
查看staging table、table stream和final table表里的数据
SELECT '01staging' AS table_type, 'staging_policy' AS table_name, COUNT(*) AS row_count FROM staging_policy
UNION ALL
SELECT '01staging' AS table_type, 'staging_vehicles' AS table_name, COUNT(*) AS row_count FROM staging_vehicles
UNION ALL
SELECT '01staging' AS table_type, 'staging_customers' AS table_name, COUNT(*) AS row_count FROM staging_customers
UNION ALL
SELECT '01staging' AS table_type, 'staging_claims' AS table_name, COUNT(*) AS row_count FROM staging_claims
UNION ALL
SELECT '02stream' AS table_type, 'STREAM_policy' AS table_name, COUNT(*) AS row_count FROM STREAM_policy
UNION ALL
SELECT '02stream' AS table_type, 'STREAM_vehicles' AS table_name, COUNT(*) AS row_count FROM STREAM_vehicles
UNION ALL
SELECT '02stream' AS table_type, 'STREAM_customers' AS table_name, COUNT(*) AS row_count FROM STREAM_customers
UNION ALL
SELECT '02stream' AS table_type, 'STREAM_claims' AS table_name, COUNT(*) AS row_count FROM STREAM_claims
UNION ALL
SELECT '03final' AS table_type, 'policy' AS table_name, COUNT(*) AS row_count FROM policy
UNION ALL
SELECT '03final' AS table_type, 'vehicles' AS table_name, COUNT(*) AS row_count FROM vehicles
UNION ALL
SELECT '03final' AS table_type, 'customers' AS table_name, COUNT(*) AS row_count FROM customers
UNION ALL
SELECT '03final' AS table_type, 'claims' AS table_name, COUNT(*) AS row_count FROM claims
ORDER BY table_type;
资料
云器Lakehouse基本概念
云器Lakehouse JDBC Driver
云器Lakehouse Python任务
云器云器Lakehouse调度与运维
