连接MindsDB实现基于ML和LLM的数据分析
步骤概述:
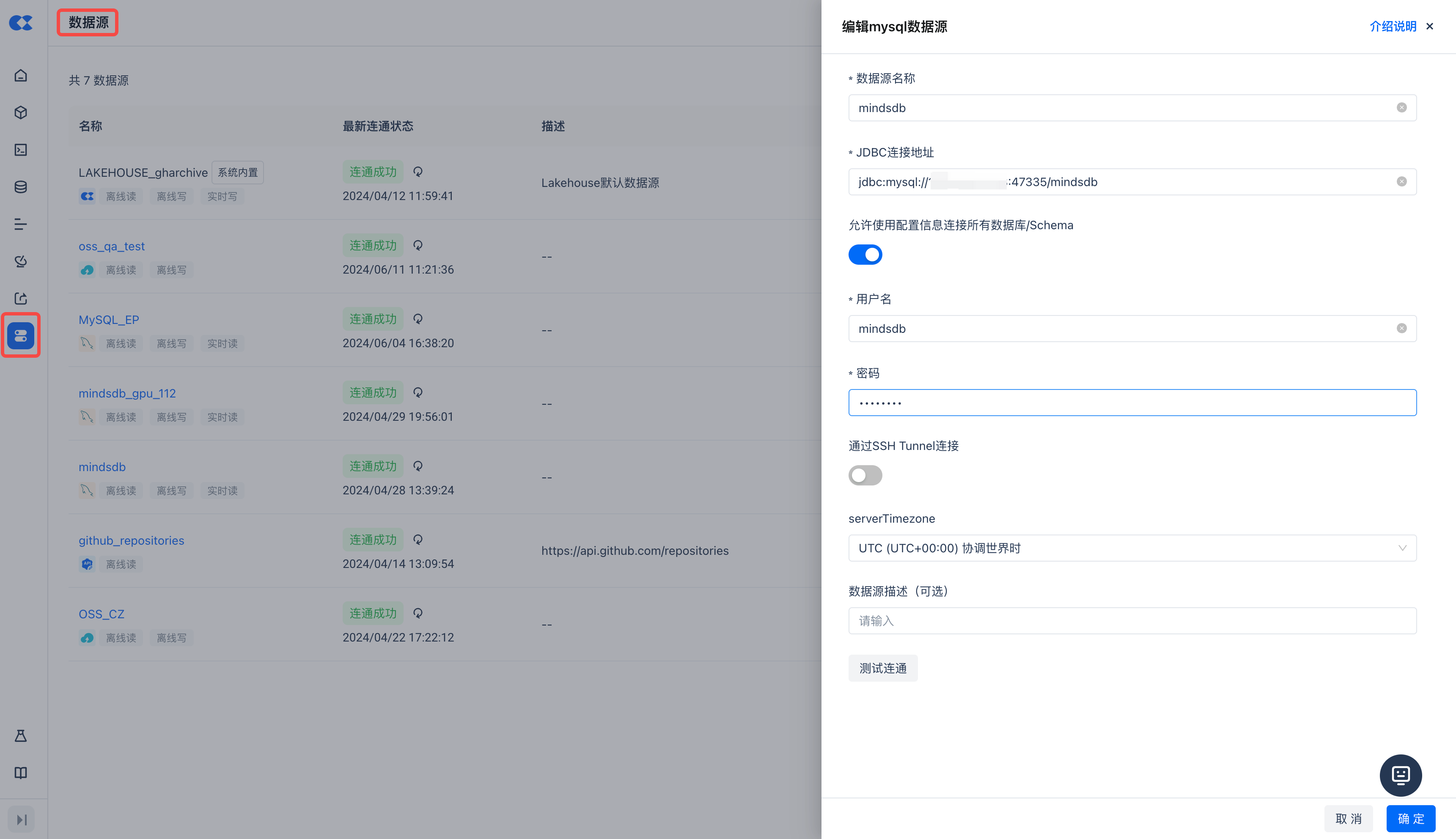
- 在云器Lakehouse的“数据源”里增加MySQL类型的数据源,通过MySQL协议连接到MindsDB。
- 在云器Lakehouse中新建“JDBC脚本”任务类型,数据源选择在第一步新建的MindsDB数据源。
- 这样,就可以在云器Lakehouse中使用MySQL语法来操作和管理MindsDB,并对云器Lakehouse中的数据,通过MindsDB管理的模型(包括传统机器学习模型和LLM)进行各种预测分析。
- 与SQL任务一样,可以直接对JDBC任务进行周期调度和运维,并通过设置任务依赖实现与其他任务的工作流编排。
新建MindsDB连接
新建连接前,请确保你的MindsDB已开启MySQL服务端口47335。
新建JDBC脚本任务,查看MindsDB的元数据
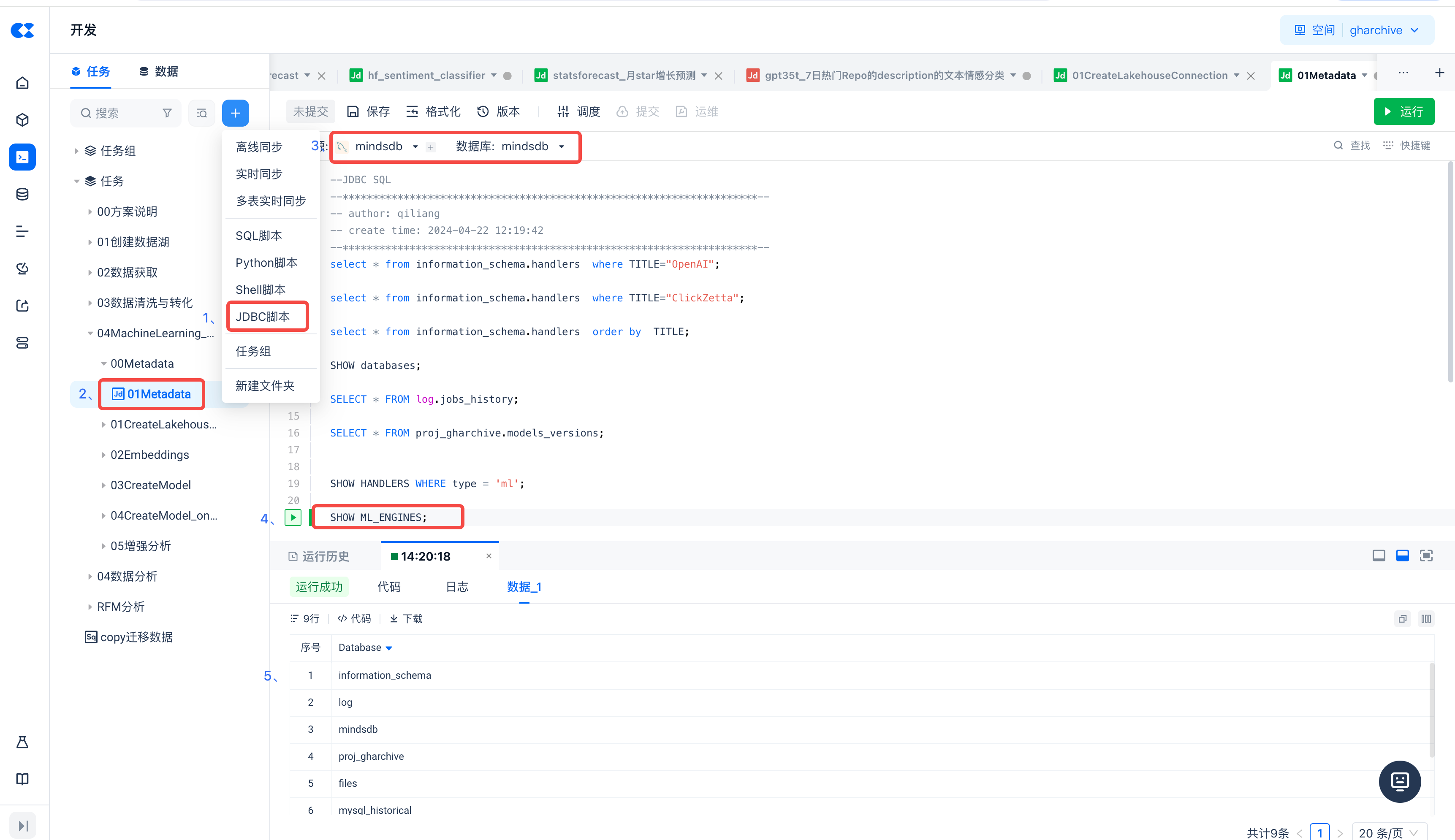
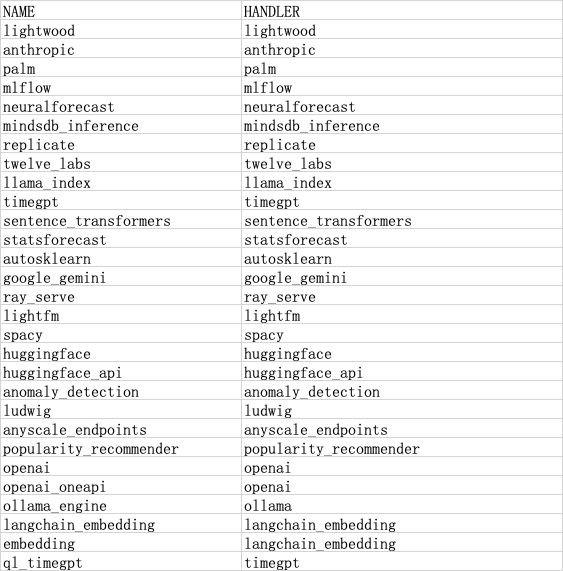
执行以下命令,查看MindsDB中已部署的ML ENGINES:
SHOW ML_ENGINES;
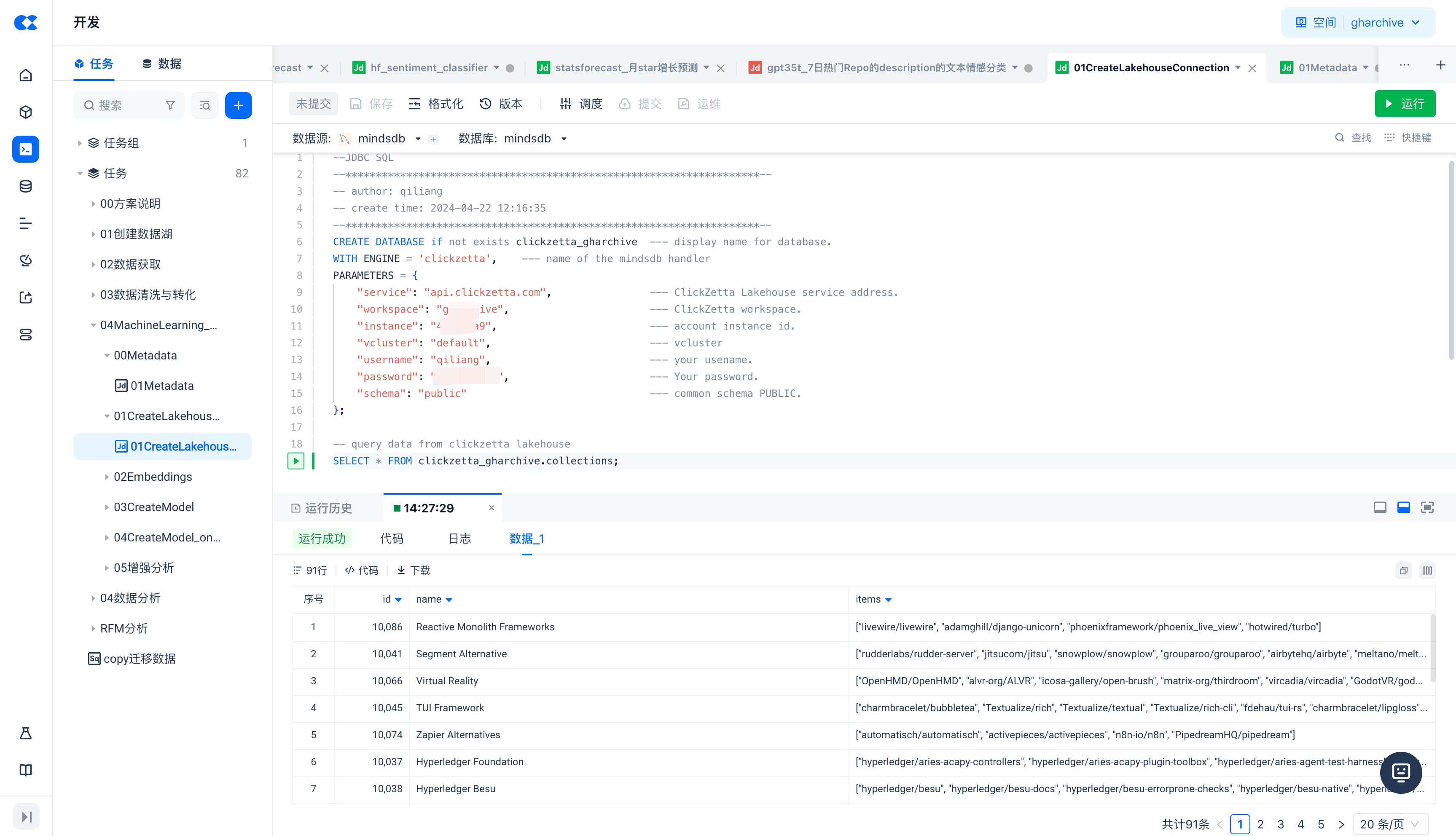
新建JDBC脚本任务,创建MindsDB到云器Lakehouse的连接
CREATE DATABASE if not exists clickzetta_gharchive --- display name for database.
WITH ENGINE = 'clickzetta', --- name of the mindsdb handler
PARAMETERS = {
"service": "<region\_id>.api.clickzetta.com", --- ClickZetta Lakehouse service address.
"workspace": "", --- ClickZetta workspace.
"instance": "", --- account instance id.
"vcluster": "DEFAULT", --- vcluster
"username": "", --- your usename.
"password": "", --- Your password.
"schema": "public" --- common schema PUBLIC.
};
-- query data from clickzetta lakehouse
SELECT * FROM clickzetta_gharchive.collections;
新建JDBC脚本任务,通过Huggingface sentiment classifier模型对Lakehouse表里文本数据进行情感分类
新建模型
CREATE MODEL if not exists proj_gharchive.hf_sentiment_classifier
PREDICT sentiment
USING
engine='huggingface',
model_name= 'cardiffnlp/twitter-roberta-base-sentiment',
task='text-classification',
input_column = 'description',
labels=['negative','neutral','positive'];
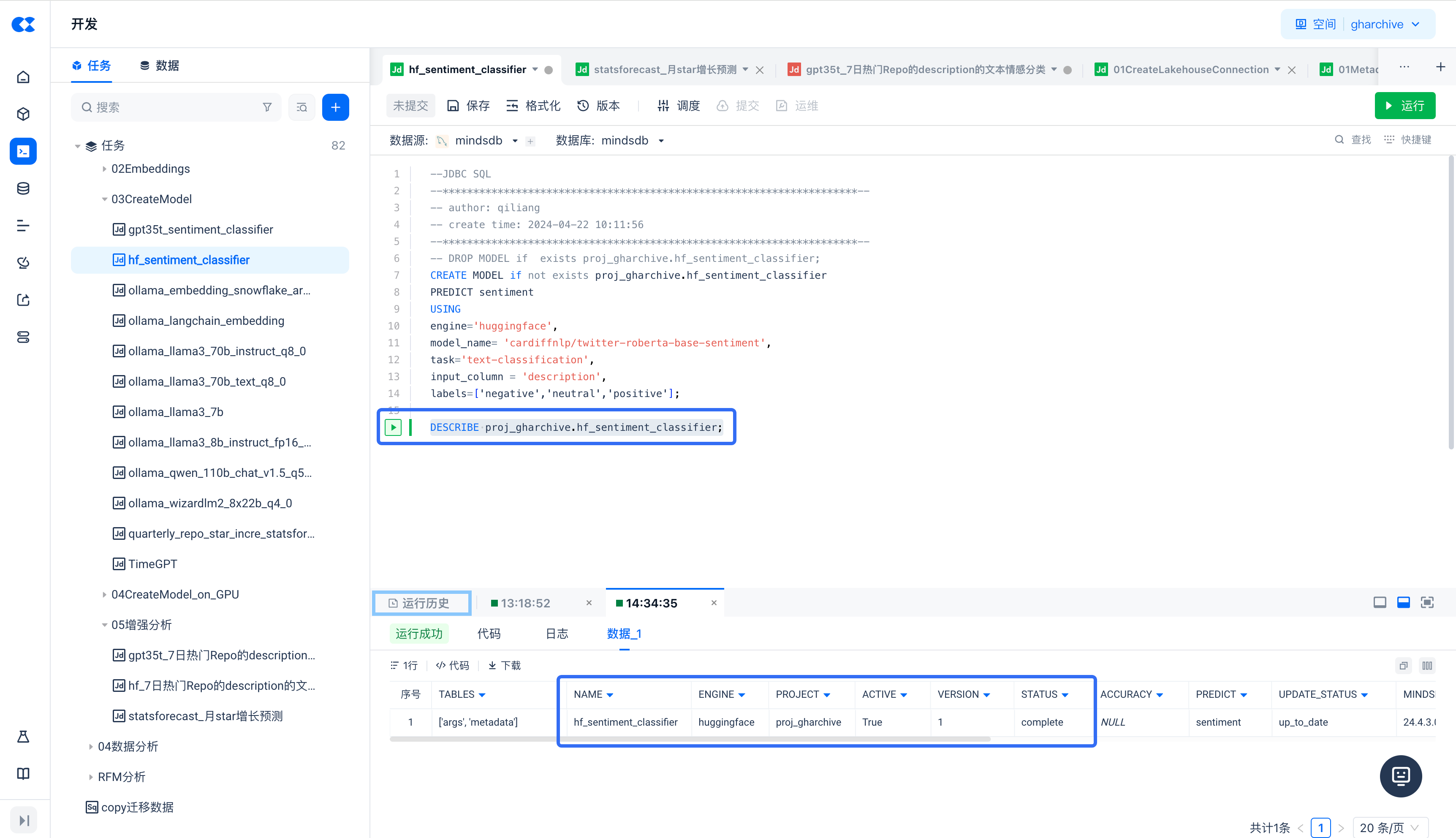
DESCRIBE proj_gharchive.hf_sentiment_classifier;
通过执行
DESCRIBE proj_gharchive.hf_sentiment_classifier
DESCRIBE proj_gharchive.hf_sentiment_classifier
命令,可以看到
hf_sentiment_classifier
hf_sentiment_classifier
模型已部署完成且处于激活状态。
对云器Lakehouse里的数据进行批量预测(情感分类)
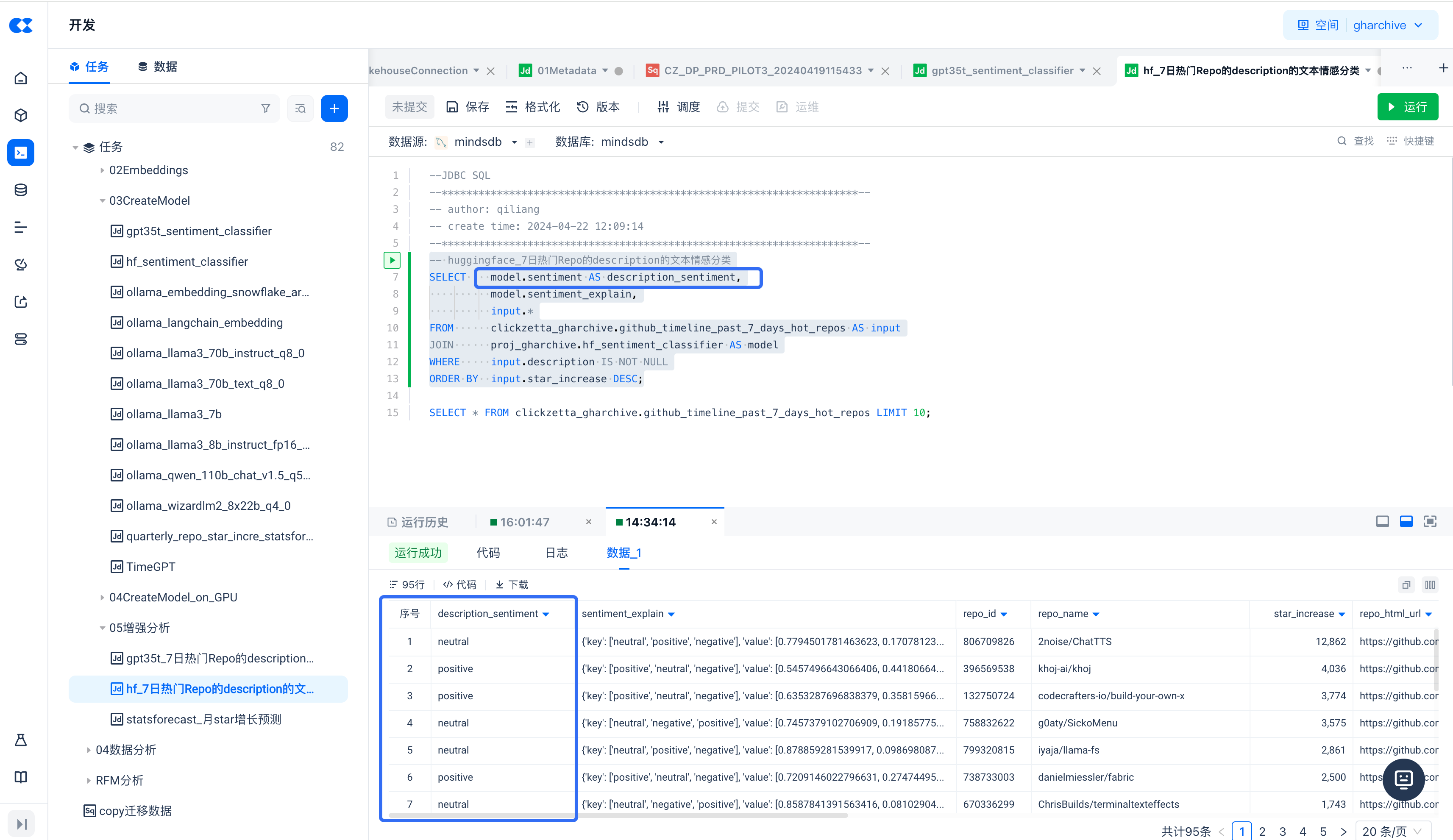
-- huggingface_7日热门Repo的description的文本情感分类
SELECT model.sentiment AS description_sentiment,
model.sentiment_explain,
input.*
FROM clickzetta_gharchive.github_timeline_past_7_days_hot_repos AS input
JOIN proj_gharchive.hf_sentiment_classifier AS model
WHERE input.description IS NOT NULL
ORDER BY input.star_increase DESC;
运行上述SQL,查看查询结果的
description_sentiment
description_sentiment
字段,可以看到对
input_column = 'description'
input_column = 'description'
列的不同分类结果,包括 neutral、positive 或者 negative(模型中的 labels 值)。
新建JDBC脚本任务,通过OpenAI大模型对Lakehouse表里文本数据进行情感分类
在本节中,我们将借助 OpenAI GPT-3.5 模型对文本进行情感分类。
新建模型
CREATE ML\_ENGINE if not exists openai_engine
FROM openai
USING
openai_api_key = 'sk-';
-- DROP MODEL if exists proj_gharchive.gpt35t_sentiment_classifier_openai;
CREATE MODEL if not exists proj_gharchive.gpt35t_sentiment_classifier_openai
PREDICT sentiment
USING
engine = 'openai_engine',
prompt_template = 'describe the sentiment of the description
strictly as "positive", "neutral", or "negative".
"I love the product":positive
"It is a scam":negative
"{{description}}.":';
对云器Lakehouse里的数据进行批量预测(情感分类)
--gpt35t_7日热门Repo的description的文本情感分类
SELECT output.*,
input.*
FROM clickzetta_gharchive.github_timeline_past_7_days_hot_repos AS input
JOIN proj_gharchive.gpt35t_sentiment_classifier AS output
LIMIT 10;
新建JDBC脚本任务,通过StatsForecast模型对Lakehouse时序数据进行预测
新建模型
StatsForecast提供了一组广泛使用的单变量时间序列预测模型,包括
ARIMA
ARIMA
使用指数平滑和针对高性能进行优化的自动建模
numba
numba
。
CREATE MODEL if not exists proj_gharchive.quarterly_repo_star_incre_forecaster
FROM clickzetta_gharchive
(SELECT *
FROM github_timeline_from_20220101_repos_star_incre_monthly
WHERE repo_id = 214011414
)
PREDICT star_increase
ORDER BY month_of_date
GROUP BY repo_id
WINDOW 12
HORIZON 3
USING ENGINE = 'statsforecast';
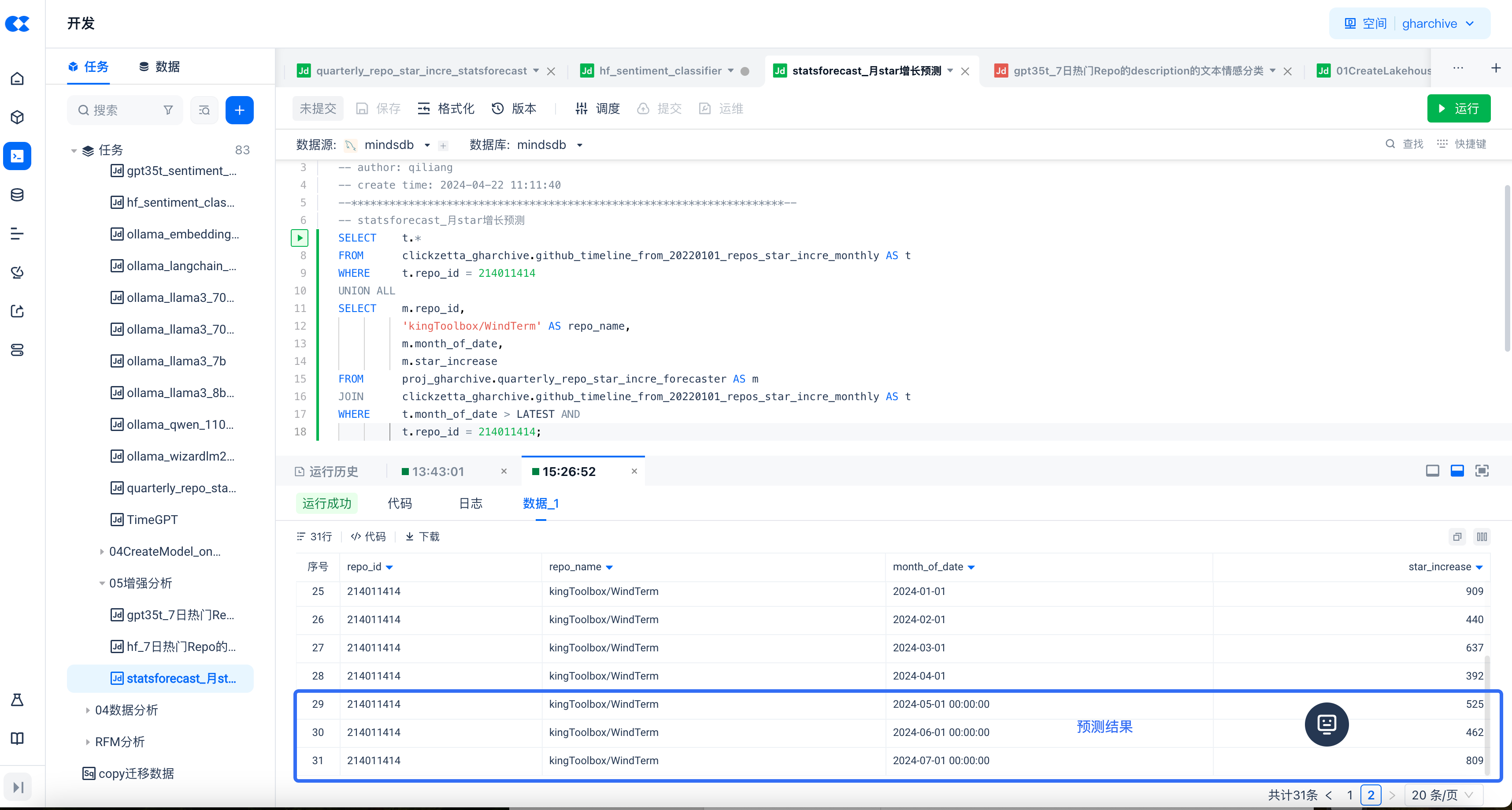
对云器Lakehouse里的数据进行批量预测
-- statsforecast_月star增长预测
SELECT t.*
FROM clickzetta_gharchive.github_timeline_from_20220101_repos_star_incre_monthly AS t
WHERE t.repo_id = 214011414
UNION ALL
SELECT m.repo_id,
'kingToolboxWindTerm' AS repo_name,
m.month_of_date,
m.star_increase
FROM proj_gharchive.quarterly_repo_star_incre_forecaster AS m
JOIN clickzetta_gharchive.github_timeline_from_20220101_repos_star_incre_monthly AS t
WHERE t.month_of_date > LATEST AND
t.repo_id = 214011414;
任务调度和流程编排
与SQL任务一样,可以直接对JDBC任务进行周期调度和运维,并通过设置任务依赖实现与其他任务的工作流编排。
