通过Bluepipe实现Oracle数据库到云器Lakehouse的实时数据同步
方案介绍
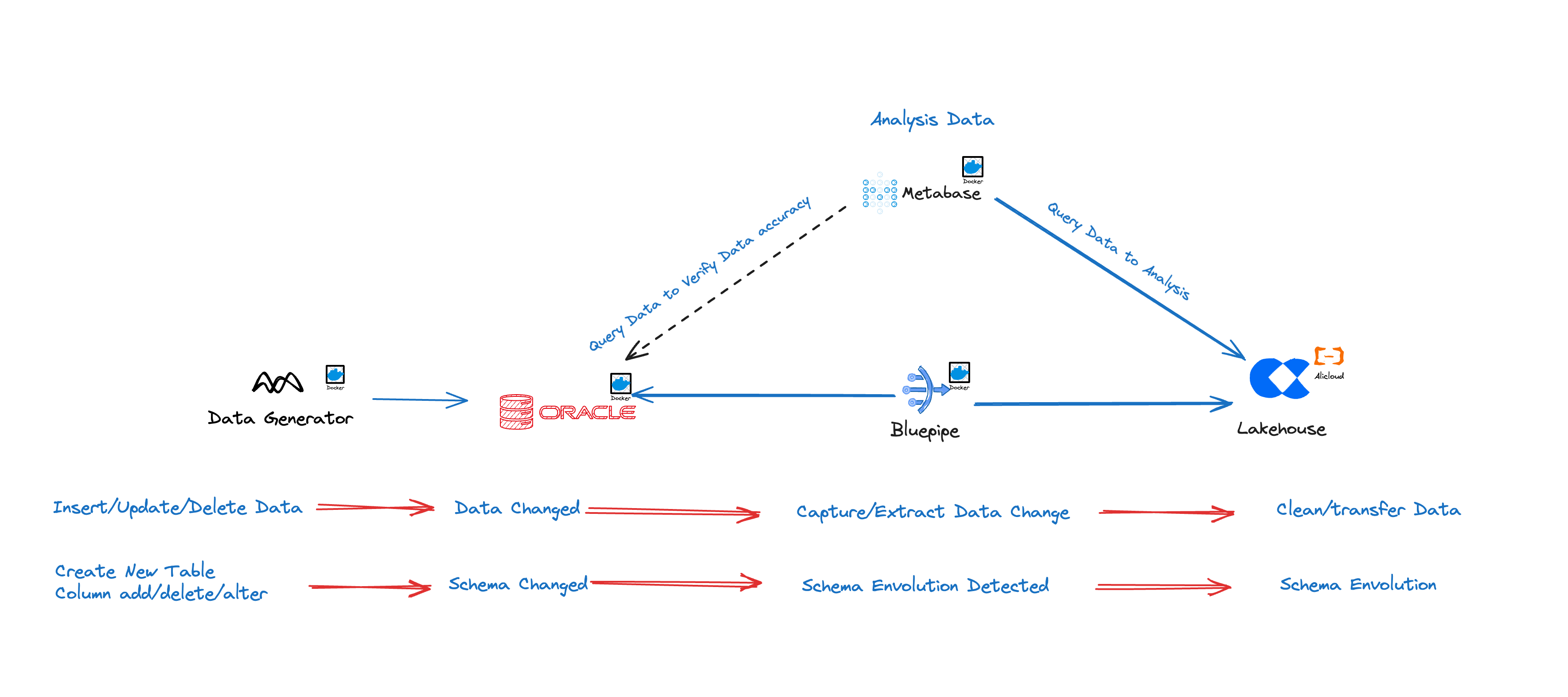
30 多年来,Oracle 一直在关系数据库和数据仓库领域占有重要地位。随着 Exadata、Exalytics、Exalogic、SuperCluster 和 12c Database 等集成系统的推出,存储和计算的紧密集成使得能够使用本地基础设施更快地处理大量数据。然而,数据的数量、速度和种类急剧增加,而云为现代数据分析带来了更多可能性。例如,通过将计算与存储分离,云器Lakehouse实现了新一代的云数据平台,以share-nothing数据架构实现了计算和存储的自动即时扩展。
方案优势
Bluepipe支持从Oracle到云器Lakehouse的实时数据同步。特别是在多实例、多表的复杂数据库环境中,Bluepipe实现了自动化同步,极大降低了人工配置同步作业的复杂度和工作量。对于数万张表的源数据库,Bluepipe能够做到自动配置同步任务。
开箱即用,10 分钟完成配置
Bluepipe
Bluepipe
几乎可以运行在任何Linux
Linux
系统中,支持x86
x86
和arm
arm
芯片;常见的机架式服务器、笔记本电脑,甚至树莓派都可以用来部署;- 极简的配置过程,默认参数即可达到最佳性能。
全、增量一体化,无需运维干预
- 全量同步与增量同步深度协同,几乎无需日常运维操作;
- 高效的数据比对与热修复技术,始终保证数据一致性;
- 高度鲁棒的
Schema Evolution
Schema Evolution
。
推数据,而不是暴露端口
Bluepipe
Bluepipe
与您的数据库一起部署在您的内网,无需对外暴露端口;- 弹性
buffer size
buffer size
技术,在吞吐(Throughput)
吞吐(Throughput)
和延迟(latency)
延迟(latency)
之间自动平衡。
Oracle链路的独特优势
Bluepipe
Bluepipe
基于
Oracle LogMiner
Oracle LogMiner
实现对变更数据的捕捉。与此同时,在以下几个方面做了深度优化:
对DDL行为的深度兼容
在
LogMiner
LogMiner
默认策略下,当发生
DDL
DDL
行为后,相关表上后续的
DML
DML
操作均无法正确解析,从而导致无法正确捕捉到变更。
Bluepipe
Bluepipe
维护了字典文件的自动构建策略,保证表结构变更后仍然能捕捉到正确的增量数据。
大事务优化
Oracle Redo Log
Oracle Redo Log
中记录了完整的事务(
Transaction
Transaction
)过程,而业务上通常仅希望拿到
commit
commit
之后的数据,因此,需要在传输过程中使用
buffer
buffer
来暂存尚未
commit
commit
的变更记录。
Bluepipe
Bluepipe
基于独特的内存管理技术,单节点上也能轻松应对千万量级的大事务。
Oracle 12.2
Oracle 12.2
版本之后,对表名、字段名的最大长度支持到了 128 字节。 但因为种种原因,
LogMiner
LogMiner
对于无
OGG LICENSE
OGG LICENSE
的实例,至今仍不支持对包含长名称的表的 DML 解析,详情参考
官方文档。
Bluepipe
Bluepipe
基于高效的流批融合技术,全面支持了此种情况下的增量数据捕捉与投递。
适配支持RAC
RAC
架构
同步效果
LAG:10秒左右
同步速度:20000行/秒
实施步骤
安装和部署Bluepipe
如您尚未完成Bluepipe的安装和部署,请联系云器或者Bluepipe。
在Bluepipe中配置同步数据源
配置Oracle数据源
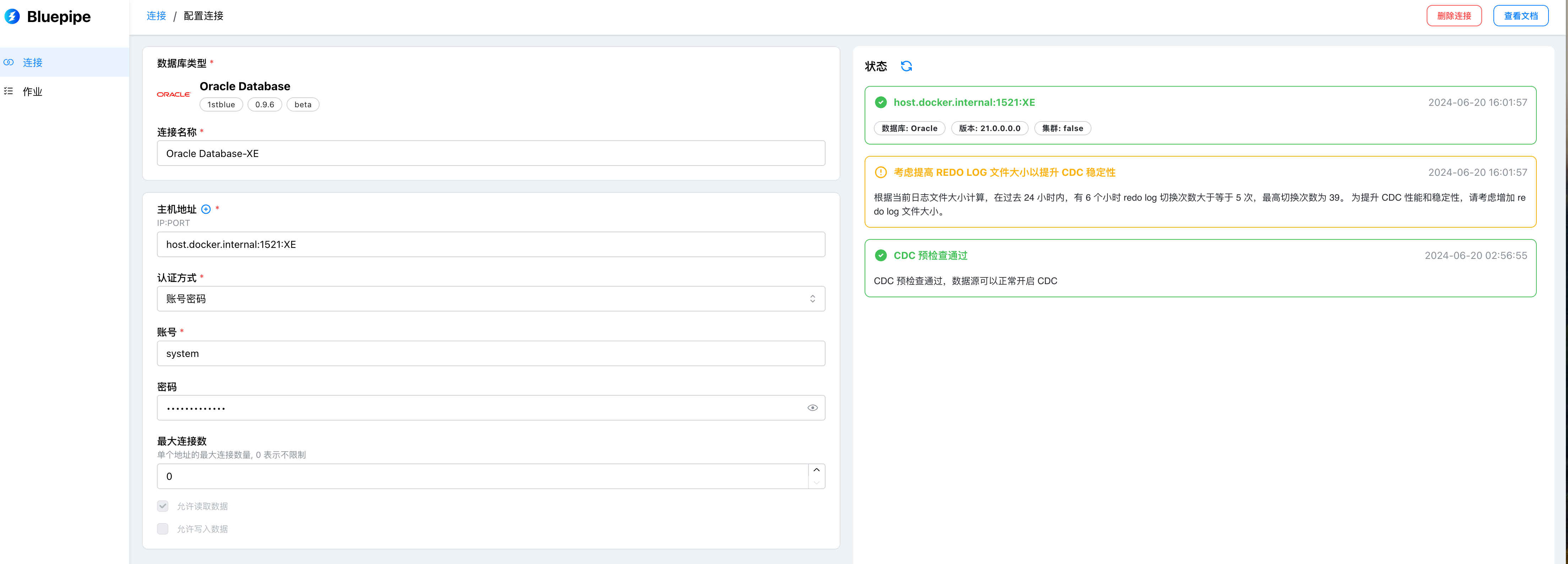
配置项说明
| 配置项名称 | 说明 |
|---|
| 连接串 | 数据源的连接方式,格式是:IP:PORT:SID,例如:127.0.0.1:1521:XE |
| 用户名 | 连接数据库的用户名,例如:C##CDC_USER |
| 密码 | 连接数据库的用户名所对应的密码,例如:userpassword |
| 连接名称 | 自定义的数据源名称,方便后续管理,例如:本地测试实例 |
| 允许批量抽取 | 以查询方式读取数据表,支持行级别过滤,默认开启 |
| 允许流式抽取 | 以CDC的方式实时捕捉数据库变更,默认开启 |
| 允许数据写入 | 可以作为目标端数据源,默认开启 |
基本功能
| 功能 | 说明 |
|---|
| 结构迁移 | 如目标不存在所选表,则自动根据源端元数据,结合映射生成对端创建语句并执行创建 |
| 全量数据迁移 | 逻辑迁移,通过顺序扫描表数据,将数据分批写入到对端数据库 |
| 增量实时同步 | 支持 INSERT, UPDATE, DELETE 常见 DML 同步 |
配置云器Lakehouse作为目标端
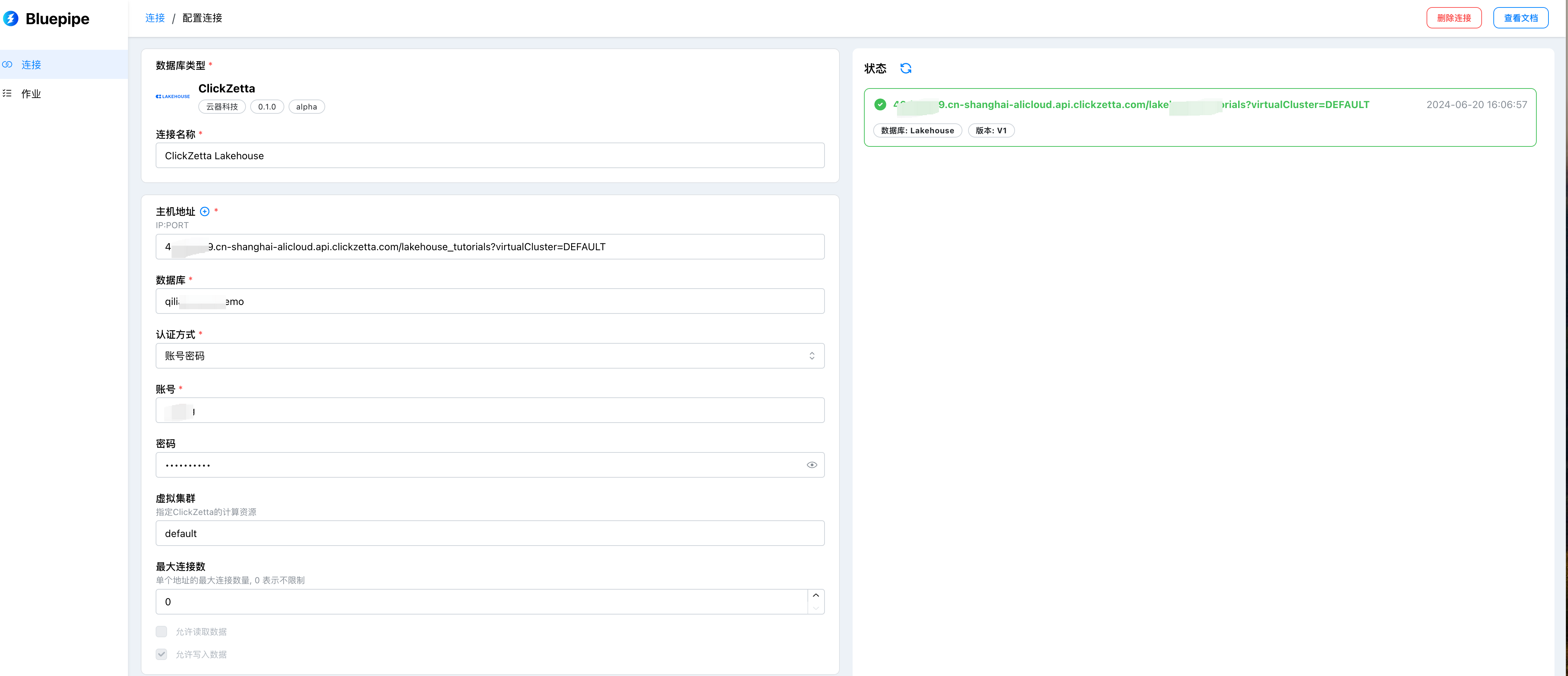
配置项说明
| 配置项名称 | 说明 |
|---|
| 连接串 | 数据源的连接方式,格式是:{instance}.{domain}/{workspace},例如:abcdef.cn-shanghai-alicloud.api.clickzetta.com/quick_start |
| 虚拟集群 | 设置运行的虚拟集群,默认值为default |
| 用户名 | 连接数据库的用户名,例如:username |
| 密码 | 连接数据库的用户名所对应的密码,例如:userpassword |
| 连接名称 | 自定义的数据源名称,方便后续管理,例如:本地测试实例 |
| 允许批量抽取 | 以查询方式读取数据表,支持行级别过滤,暂不支持抽取 |
| 允许流式抽取 | 以CDC的方式实时捕捉数据库变更,暂不支持抽取 |
| 允许数据写入 | 可以作为目标端数据源,默认开启 |
在Oracle数据库创建表
CREATE TABLE metabase.people_with_pk (
id INTEGER PRIMARY KEY,
age INTEGER,
name VARCHAR(32),
create_date DATE DEFAULT GETDATE()
);
CREATE TABLE metabase.employees (
employee_id INTEGER PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
hire_date DATE,
salary INTEGER,
department_id INTEGER,
email VARCHAR(100),
phone_number VARCHAR(20),
address VARCHAR(200),
job_title VARCHAR(100),
manager_id INTEGER,
commission_pct DECIMAL,
birth_date DATE,
marital_status VARCHAR(10),
nationality VARCHAR(50),
create_date DATE DEFAULT GETDATE()
);
CREATE TABLE metabase.departments (
department_id INTEGER PRIMARY KEY,
department_name VARCHAR(100),
location VARCHAR(200),
manager_id INTEGER,
created_date DATE,
description VARCHAR(500),
budget INTEGER,
status VARCHAR(20),
contact_person VARCHAR(100),
phone_number VARCHAR(20),
email VARCHAR(100),
website VARCHAR(200),
start_date DATE,
end_date DATE,
num_employees INTEGER,
create_date DATE DEFAULT GETDATE()
);
在Bluepipe新建同步作业
请注意:
- 在选择来源时,目标表名
{namespace}/{table}
{namespace}/{table}
中的 {namespace}
{namespace}
,可以用你期望的schema名字来替代,比如 bluepipe_oracle_staging
bluepipe_oracle_staging
。
- 在设计环节,增量复制选择“使用CDC技术实时复制”。
新建同步作业成功后的效果如下图:
 新建作业会自动启动并开始全量数据同步,之后开始持续的增量数据实时同步。
新建作业会自动启动并开始全量数据同步,之后开始持续的增量数据实时同步。
数据生成
通过运行如下Python代码,向Oracle源表employees中实时插入数据:
import oracledb
import random
import time,datetime
db_user = "SYSTEM"
db_password = ""
db_host = "
db_port = "1521"
db_service_name = "XE"
# 连接到 Oracle 数据库,并获取游标
connection = oracledb.connect(f"{db_user}/{db_password}@{db_host}:{db_port}/{db_service_name}")
cursor = connection.cursor()
# 要插入的总数量
total_records = 1000000
batch_size = 1000 # 每批次插入的记录数
inserted_rows = 0
start_time = time.time()
for batch_start in range(1, total_records + 1, batch_size):
batch_end = min(batch_start + batch_size - 1, total_records)
hire_date = random.randint(1, 200)
# 构建插入语句
insert_sql = f"""
INSERT INTO metabase.employees (
employee_id, first_name, last_name, hire_date, salary, department_id,
email, phone_number, address, job_title, manager_id, commission_pct,
birth\_date, marital_status, nationality
)
SELECT
LEVEL,
'名字' || LEVEL,
'姓氏' || LEVEL,
SYSDATE - {hire_date},
5000 + LEVEL * 1000,
MOD(LEVEL, 5) + 1,
'employee' || LEVEL || '@example.com',
'123-456-' || LPAD(LEVEL, 3, '0'),
'地址' || LEVEL,
CASE MOD(LEVEL, 3)
WHEN 0 THEN '经理'
WHEN 1 THEN '分析师'
WHEN 2 THEN '职员'
END,
CASE WHEN LEVEL > 1 THEN TRUNC((LEVEL - 1) / 5) END,
0.1 * LEVEL,
SYSDATE - (LEVEL * 100),
CASE MOD(LEVEL, 2)
WHEN 0 THEN '单身'
WHEN 1 THEN '已婚'
END,
CASE MOD(LEVEL, 4)
WHEN 0 THEN '中国'
WHEN 1 THEN '美国'
WHEN 2 THEN '英国'
WHEN 3 THEN '澳大利亚'
END
FROM DUAL
CONNECT BY LEVEL <= {batch_size}
"""
# 执行插入
cursor.execute(insert_sql)
connection.commit()
inserted_rows = inserted_rows + batch_size
end_time = time.time()
total_time = end_time - start_time
average_insert_speed = inserted_rows / total_time
print(f"Total rows inserted: {inserted_rows}")
print(f"Average insert speed: {average_insert_speed:.2f} rows/second")
time.sleep(0.5)
end_time = time.time()
total_time = end_time - start_time
average_insert_speed = inserted_rows / total_time
print(f"Total rows inserted: {inserted\_rows}")
print(f"Average insert speed: {average\_insert\_speed:.2f} rows/second")
# 关闭游标和连接
cursor.close()
connection.close()
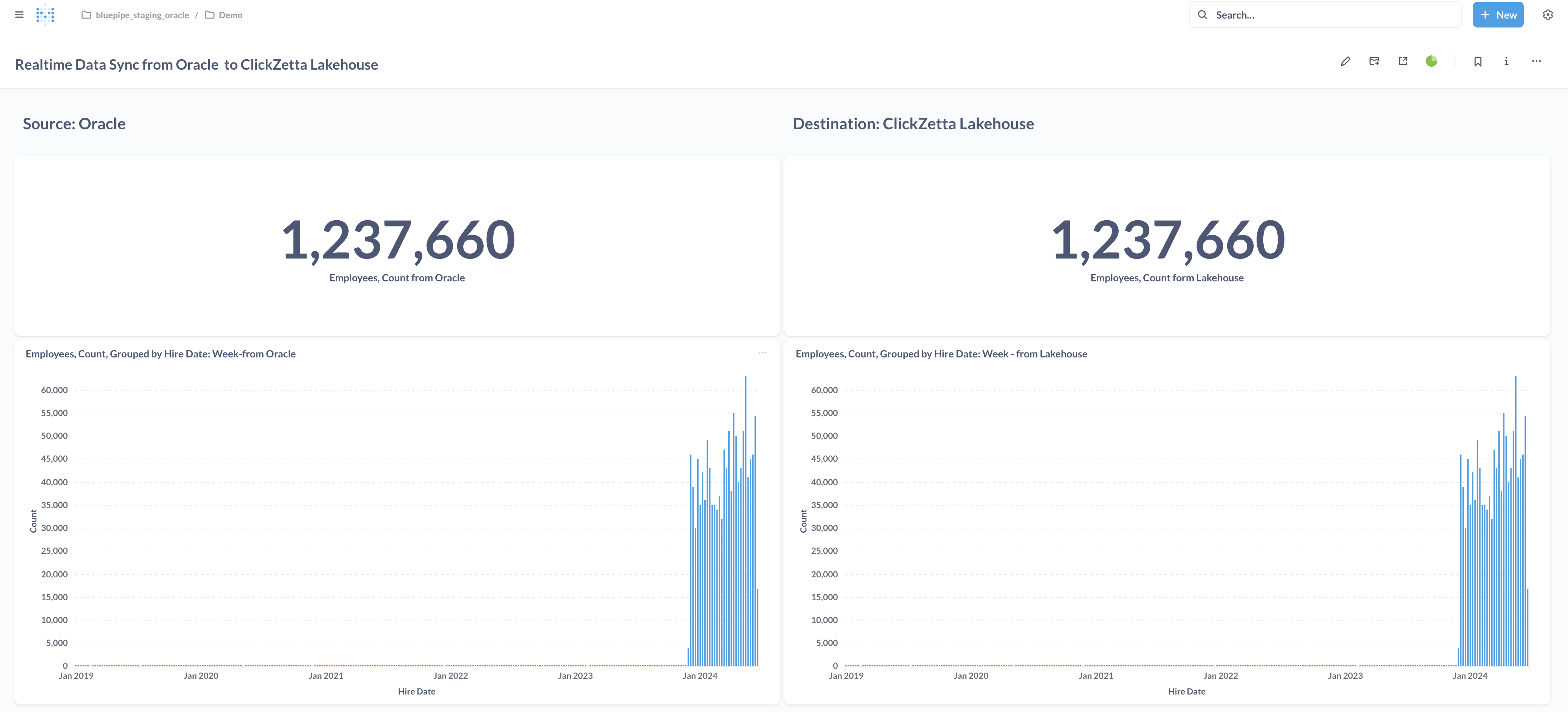
请参考:
Metabase的安装部署